
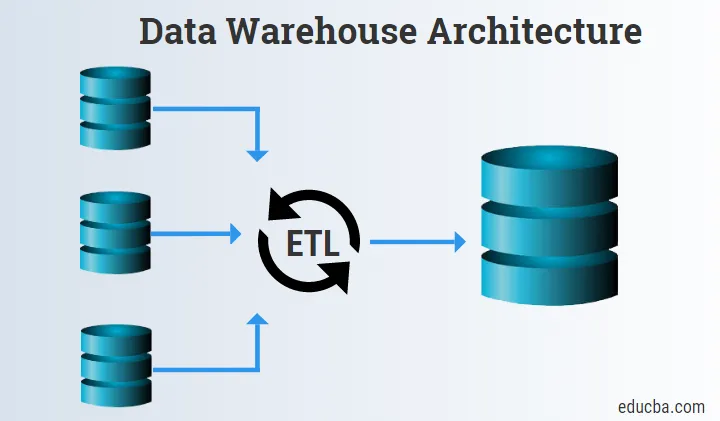
Uvod v arhitekturo skladišča podatkov
- Skladišče podatkov je prostor za shranjevanje, ki vsebuje zbirke več različnih vrst podatkov, pridobljenih iz več vrst virov.
- Celoten postopek, pri katerem se zunanji viri podatkov pridobivajo, obdelujejo, shranjujejo in analizirajo do uporabnih informacij, odvijajo v naboru sistemov, ki so združeni z eno samo shemo, znano kot arhitektura skladišča podatkov.
Arhitektura skladišča podatkov

Arhitektura skladišča podatkov na splošno obsega tri stopnje.
- Vrhunski nivo
- Srednji nivo
- Spodnji nivo
Vrhunski nivo
- Top Tier je sestavljen iz odjemalčevega sprednjega dela arhitekture.
- Informacije, ki se uporabljajo v Transformirani in Logiki, shranjene v skladišču podatkov, bodo uporabljene in pridobljene za poslovne namene v tem nivoju.
- Za ustvarjanje želenih informacij je na voljo več orodij za pripravo in analizo poročil.
- Tu se izvaja rudarjenje podatkov, ki je postalo velik trend.
- Vsi dokumenti, analiza stroškov in vse funkcije, ki določajo poslovni posel na osnovi dobička, se izvedejo na podlagi teh orodij, ki uporabljajo podatke skladišča podatkov.
Srednji nivo
- Srednji nivo sestavljajo strežniki OLAP
- OLAP je spletni analitični strežnik za obdelavo podatkov
- OLAP se uporablja za zagotavljanje informacij poslovnim analitikom in managerjem
- Ker se nahaja na srednjem nivoju, pravilno sodeluje z informacijami, ki so prisotne na spodnjem nivoju, in vpogleda posreduje orodjem Top Tier, ki obdelujejo razpoložljive informacije.
- V arhitekturi podatkovnih skladišč se uporablja večinoma relacijski ali večdimenzionalni OLAP.
Spodnji nivo
Spodnji nivo sestavljajo predvsem viri podatkov, orodje ETL in shramba podatkov.
1. Viri podatkov
Viri podatkov so sestavljeni iz izvornih podatkov, ki so pridobljeni in posredovani orodjem Staging in ETL za nadaljnji postopek.
2. Orodja ETL
- Orodja ETL so zelo pomembna, saj pomagajo pri združevanju logike, surovih podatkov in sheme v eno in naložijo podatke v skladišče podatkov ali podatkovne marke.
- Včasih ETL naloži podatke v podatkovne karte in nato se informacije shranijo v shrambo podatkov. Ta pristop je znan kot spodnji pristop.
- Pristop, pri katerem ETL neposredno naloži informacije v shrambo podatkov, je znan kot pristop od zgoraj navzdol.
Razlika med pristopom od zgoraj navzdol in pristopom od spodaj navzgor
| Pristop od zgoraj navzdol | Pristop od spodaj navzgor |
| Zagotavlja natančen in dosleden pogled na informacije, saj se podatki iz podatkovnega skladišča uporabljajo za ustvarjanje podatkovnih podatkov | Poročila je mogoče ustvariti enostavno, saj so podatki izdelani prvi in je razmeroma enostavno komunicirati s podatkovnimi grafi. |
| Močan model in zato velika podjetja | Ni tako močno, vendar se lahko skladišče podatkov razširi in ustvari se število podatkovnih mest |
| Čas, stroški in vzdrževanje so visoki | Čas, stroški in vzdrževanje so nizki. |
Podatkovni grafi
- Data Mart je tudi shranjevalna komponenta, ki se uporablja za shranjevanje podatkov o določeni funkciji ali delu, ki ga posamezni organ povezuje s podjetjem.
- Data mart zbira podatke iz Data Warehouse in zato lahko rečemo, da data mart shrani podmnožico podatkov v Data Warehouse.
- Podatkovni podatki so prilagodljivi in majhni.
3. Skladišče podatkov
- Data Warehouse je osrednja komponenta celotne arhitekture Data Warehouse.
- Deluje kot shramba za shranjevanje informacij.
- Velike količine podatkov so shranjene v skladišču podatkov.
- Te podatke uporablja več tehnologij, kot je Big Data, ki zahtevajo analizo velikih podskupin informacij.
- Data Mart je tudi model Data Warehouse.
Različni sloji arhitekture skladišča podatkov
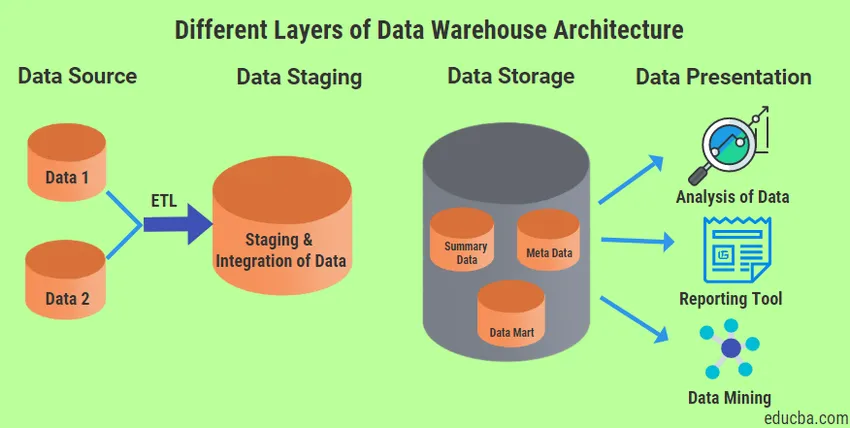
V Arhitekturi podatkovnih skladišč bodo vedno prisotni štirje različni tipi slojev.
1. Sloj virov podatkov
- Podatkovni vir podatkov je sloj, na katerem se srečajo podatki iz vira in jih nato pošljejo drugim slojem za želene operacije.
- Podatki so lahko poljubne vrste.
- Izvorni podatki so lahko baza podatkov, preglednica ali katere koli druge vrste besedilne datoteke.
- Izvorni podatki so lahko poljubne oblike. Ne moremo pričakovati, da bomo dobili podatke v enaki obliki, glede na to, da so viri zelo različni.
- V resničnem življenju je lahko nekaj primerov izvornih podatkov
- Datoteke dnevnika posamezne vloge ali delovnega mesta ali vpisa delodajalcev v podjetje.
- Anketni podatki, podatki o borzi itd.
- Podatki spletnega brskalnika in še veliko več.
2. Podatkovni sloj podatkov
Naslednji koraki se izvajajo v sloju podatkovne faze.
1. Pridobivanje podatkov
Podatki, ki jih prejme izvorni sloj, se vnesejo v stopenjski sloj, kjer je prvi postopek, ki poteka s pridobljenimi podatki, pridobivanje.
2. pristajalna baza podatkov
- Pridobljeni podatki so začasno shranjeni v pristajalni bazi.
- Ko pridobi podatke, pridobi podatke.
3. Območje uprizarjanja
- Vzame se zbirka Podatki v pristajalni bazi in na območju uprizoritve se izvede več preverjanj kakovosti in postopnih postopkov.
- Prav tako sta identificirana struktura in shema, prilagajanje podatkov, ki niso urejeni, pa poskuša povzročiti skupno med pridobljenimi podatki.
- Namestitev ali nastavitev podatkov tik pred preoblikovanjem in spremembami je dodatna prednost, zaradi česar je postopek postopnega uprizarjanja zelo pomemben.
- Olajša obdelavo podatkov.
4. ETL
- To je ekstrakcija, preoblikovanje in obremenitev.
- Orodja ETL se uporabljajo za integracijo in obdelavo podatkov, pri čemer se logika uporablja za precej surove, a nekoliko urejene podatke.
- Ti podatki se pridobivajo v skladu z analitično naravo, ki se zahtevajo, in pretvorijo v podatke, za katere se šteje, da so shranjeni v shrambi podatkov.
- Po preoblikovanju se podatki ali bolje informacije končno naložijo v podatkovno skladišče.
- Nekaj primerov orodij ETL so Informatica, SSIS itd.
3. Sloj za shranjevanje podatkov
- Obdelani podatki so shranjeni v skladišču podatkov.
- Ti podatki se očistijo, preoblikujejo in pripravijo z točno določeno strukturo in tako delodajalcem omogočajo uporabo podatkov, kot jih zahteva podjetje.
- Podatki bodo odvisno od pristopa arhitekture shranjeni v Data Warehouse in Data Marts. Podatkovni podatki bodo obravnavani v kasnejših fazah.
- Nekateri vključujejo tudi operativno shrambo podatkov.
4. Sloj predstavitve podatkov
- Ta plast, kjer uporabniki pridejo v interakcijo s podatki, shranjenimi v podatkovnem skladišču.
- Za pridobivanje različnih vrst informacij na podlagi podatkov bomo uporabili poizvedbe in več orodij.
- Informacije pridejo do uporabnika s pomočjo grafične predstavitve podatkov.
- Orodja za poročanje se uporabljajo za pridobivanje poslovnih podatkov, poslovna logika pa se uporablja tudi za zbiranje več vrst informacij.
- V tem sloju se vzdržujejo in gledajo tudi informacije o meta podatkih in delovanje sistema ter uspešnost sistema.
Zaključek
Pomembna točka Data Warehouse je njegova učinkovitost. Za ustvarjanje učinkovitega skladišča podatkov oblikujemo okvir, znan kot okvir poslovne analize. Glede zasnove podatkovnega skladišča obstajajo štiri vrste stališč.
1. Pogled od zgoraj navzdol: Ta pogled omogoča izbiro samo določenih informacij, potrebnih za shranjevanje podatkov.
2. Pogled vira podatkov: Ta pogled prikazuje vse informacije od vira podatkov do tega, kako se transformirajo in shranjujejo.
3. Pogled skladišča podatkov: Ta pogled prikazuje informacije, ki so prisotne v podatkovnem skladišču skozi tabele dejstev in dimenzijske tabele.
4. Pogled poslovnih poizvedb: to je prikaz, ki prikazuje podatke z uporabnikovega stališča.
Priporočeni članki
To je vodnik za arhitekturo skladišča podatkov. Tu smo razpravljali o različnih vrstah pogledov, slojev in stopenj arhitekture skladišča podatkov. Če želite izvedeti več, lahko preberete tudi druge naše predlagane članke -
- Poklicna zbirka podatkov
- Kako deluje JavaScript
- Intervjuja glede skladišča podatkov
- Kaj je Panda