
Pregled algoritmov nevronske mreže
- Naj najprej vemo, kaj pomeni nevronska mreža? Nevronske mreže se zgledujejo po bioloških nevronskih mrežah v možganih ali lahko rečemo živčnem sistemu. Vzbujalo je veliko navdušenja in raziskave še vedno potekajo v tej podskupini Strojnega učenja v industriji.
- Osnovna računska enota nevronske mreže je nevron ali vozlišče. Sprejema vrednosti od drugih nevronov in izračuna izhod. Vsako vozlišče / nevron je povezano s težo (w). Ta teža je dana glede na relativni pomen določenega nevrona ali vozlišča.
- Torej, če vzamemo f kot funkcijo vozlišča, bo funkcija vozlišča f zagotovila izhod, kot je prikazano spodaj: -
Izhod nevrona (Y) = f (w1.X1 + w2.X2 + b)
- Če sta w1 in w2 teža, sta X1 in X2 numerični vhodi, medtem ko je b odklon.
- Zgornja funkcija f je nelinearna funkcija, imenovana tudi funkcija aktiviranja. Njegov osnovni namen je uvesti nelinearnost, saj so skoraj vsi podatki v resničnem svetu nelinearni in želimo, da se nevroni naučijo teh predstavitev.
Različni algoritmi nevronske mreže
Poglejmo zdaj štiri algoritme nevronske mreže.
1. Gradient spust
Gre za enega najbolj priljubljenih algoritmov za optimizacijo na področju strojnega učenja. Uporablja se med usposabljanjem modela strojnega učenja. Z enostavnimi besedami: v osnovi se uporablja za iskanje vrednosti koeficientov, ki preprosto zmanjšajo stroškovno funkcijo v največji možni meri. Najprej začnemo z določitvijo nekaterih vrednosti parametrov in nato z izračunom začnemo iterativno prilagoditi vrednosti, tako da izgubljena funkcija se zmanjša.
Zdaj pa pojdimo na del, kaj je naklon? Torej, gradient pomeni, da se bo izhod katere koli funkcije spreminjal, če se bo vhod zmanjšalo za malo ali z drugimi besedami, ga lahko pokličemo na pobočje. Če je pobočje strmo, se bo model hitreje učil, podobno se model preneha učiti, ko je naklon nič. To je zato, ker je algoritem minimizacije minimiziran določen algoritem.
Spodaj je prikazana formula za iskanje naslednjega položaja v primeru naklona naklona.
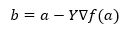
Kjer je naslednji položaj b
a je trenutni položaj, gama pa je čakalna funkcija.
Kot lahko vidite, je spust po naklonu zelo zvočna tehnika, vendar obstaja veliko področij, kjer spust po naklonu ne deluje pravilno. Spodaj so navedeni nekateri:
- Če algoritem ni pravilno izveden, lahko naletimo na nekaj, kot je problem izginjajočega gradienta. Pojavijo se, kadar je gradient premajhen ali prevelik.
- Težave nastanejo, če razporeditev podatkov predstavlja težavo z nekonveksno optimizacijo. Gradient spodobno deluje samo s težavami, ki so konveksno optimizirane težave.
- Eden zelo pomembnih dejavnikov, ki jih je treba iskati pri uporabi tega algoritma, so viri. Če imamo za aplikacijo dodeljeno manj pomnilnika, bi se morali izogibati algoritmu spuščanja z naklonom.
2. Newtonova metoda
Gre za algoritem optimizacije drugega reda. Imenuje se po drugem redu, ker uporablja hesejevo matrico. Torej, Hessova matrika ni nič drugega kot kvadratna matrica delnih izpeljank drugega reda skalarne funkcije. Pri Newtonovem algoritmu za optimizacijo metode se uporablja za prvo izpeljanko dvojne diferencirane funkcije f, tako da lahko najde korenine / stacionarne točke. Poglejmo zdaj korake, ki jih zahteva Newtonova metoda za optimizacijo.
Najprej oceni indeks izgube. Nato preveri, ali so merila za zaustavitev resnična ali napačna. Če je napačno, nato izračuna Newtonovo smer treninga in stopnjo vadbe, nato pa izboljša parametre ali uteži nevrona in spet se nadaljuje isti cikel. Torej, zdaj lahko rečete, da je potrebno manj korakov v primerjavi s spustom gradienta, da dosežete minimum vrednost funkcije. Čeprav je v primerjavi z algoritmom naklona naklona potrebno manj korakov, se še vedno ne uporablja na široko, saj sta natančen izračun hessiana in njegove obratne računsko zelo drage.
3. Konjugirajte gradient
To je metoda, ki jo lahko obravnavamo kot nekaj med naklonom naklona in Newtonovo metodo. Glavna razlika je v tem, da pospešuje počasno konvergenco, ki jo na splošno povezujemo z naklonom. Drugo pomembno dejstvo je, da se lahko uporablja tako za linearne kot nelinearne sisteme in je iterativni algoritem.
Razvila sta jo Magnus Hestenes in Eduard Stiefel. Kot smo že omenili, da ustvarja hitrejšo konvergenco kot spust z gradientom. Razlog, da to lahko storimo, je, da se v algoritmu Conjugate Gradient iskanje izvede skupaj s konjugiranimi smernicami, zaradi katerih se konvergira hitreje kot algoritmi za spuščanje gradienta. Pomembno je poudariti, da se γ imenuje konjugirani parameter.
Smer treninga se občasno ponastavi na negativni nagib. Ta metoda je bolj učinkovita od gradientnega spuščanja pri treniranju nevronske mreže, saj ne potrebuje Hessove matrice, ki poveča računsko obremenitev, poleg tega pa se zbliža hitreje kot gradientski spust. Primerno je za uporabo v velikih nevronskih mrežah.
4. Quasi-Newtonova metoda
Gre za alternativni pristop k Newtonovi metodi, saj se zdaj zavedamo, da je Newtonova metoda računsko draga. Ta metoda rešuje te pomanjkljivosti do te mere, da namesto izračuna hezijske matrice in nato neposrednega izračuna inverzne metode pri vsaki ponovitvi tega algoritma ustvari približek inverznemu Hesanu.
Zdaj se ta približek izračuna na podlagi informacij iz prvega izvoda funkcije izgube. Torej lahko rečemo, da je verjetno najbolj primerna metoda za ravnanje z velikimi omrežji, saj prihrani čas računanja in je tudi veliko hitrejši od spuščanja naklona ali metode konjugiranja gradientov.
Zaključek
Preden zaključimo ta članek, primerjajmo računsko hitrost in pomnilnik za zgoraj omenjene algoritme. Glede na potrebe po pomnilniku je za spuščanje v gradientu potrebnega najmanj pomnilnika in je tudi najpočasnejši. Nasprotno od tega Newtonova metoda zahteva več računske moči. Če upoštevamo vse to, je Quasi-Newtonova metoda najbolj primerna.
Priporočeni članki
To je vodnik po algoritmih nevronske mreže. Tu bomo razpravljali tudi o algoritmu nevronske mreže in štirimi različnimi algoritmi. Če želite izvedeti več, lahko preberete tudi druge naše predlagane članke -
- Strojno učenje proti nevronski mreži
- Okviri strojnega učenja
- Nevronske mreže vs poglobljeno učenje
- K- Pomeni algoritem grozda
- Vodnik po klasifikaciji nevronske mreže