
Pregled samodejnega skaliranja v AWS
Samodejno skaliranje, zapisano tudi kot samodejno skaliranje ali včasih samodejno skaliranje, je tehnika v računalništvu v oblaku, kjer je količina virov, ki so potrebna za učinkovito delovanje kmetije strežnikov, običajno izmerjena tako, da se število aktivnih strežnikov poveča ali zmanjša, če je potrebno. na obremenitev celotne strežniške kmetije. To lahko tesno povežemo z uravnavanjem obremenitve. Običajno je samodejno skaliranje nekakšna avtomatizacija za ročni postopek. Vzemimo scenarij, v katerem imate spletno mesto za e-trgovino, ki učinkovito deluje in strankam učinkovito, nobena stranka se ne pritožuje zaradi zamude na spletnem mestu niti ne izgubljate uporabnikov zaradi uspešnosti spletnega mesta. Ker je podjetje raslo, ste se tržili in ljudje so se iz dneva v dan bolj poznavali vaše spletne strani, promet na spletni strani se je povečeval. Na eni strani ste bili zadovoljni, da ste povečali posel, vendar morate videti, da mora spletno mesto služiti vsem strankam in ne zaostajati. Recimo, da trenutno lahko služi 100 strankam, kar pomeni, da če se 100 uporabnikov prijavi na vaše spletno mesto, potem lahko vsi brez težav plujejo in kupujejo, in vse to deluje prek neke fiksne konfiguracije, recimo t2.micro primera AWS. Ker je spletno mesto postalo priljubljeno, pričakujete približno 250 - 300 uporabnikov naenkrat, očitno potrebujete še dva strežnika, na katerih lahko razdelite promet in potem lahko vsi pravilno krmarite.
Ročno delo, ki je izračunati, koliko virov bi potrebovali za svoje stranke in določanje obsega na podlagi obremenitve na strežniški kmetiji in delitve prometa, se opravi ročno za zgornji scenarij. Lahko rečemo, da je to dejansko skaliranje, ne pa samodejno skaliranje, ker je bilo to narejeno ročno, vendar lahko uporabite storitev samodejnega skaliranja z izravnalnikom obremenitve v AWS, ki bo avtomatiziral zgoraj navedeno nalogo in temu pravite samodejno skaliranje ali samodejno skaliranje v oblaku računalništvo.
Kako deluje samodejno skaliranje v AWS?
V sistemu AWS je v postopku samodejnega skaliranja vključenih več subjektov, ki so: - Balancer za nalaganje in AMI sta dve glavni komponenti, ki sodelujeta v tem procesu. Najprej morate ustvariti AMI svojega trenutnega strežnika, preprosteje lahko rečemo, da je predloga vaše trenutne konfiguracije sestavljena iz vseh sistemskih nastavitev in trenutnega spletnega mesta. To lahko storite v razdelku AMI AWS. Če gremo po našem zgornjem scenariju in ste konfigurirali samodejno skaliranje, tako da je vaš sistem pripravljen za prihodnji promet.
Ko bi se promet začel povečevati, storitev AWS za samodejno skaliranje samodejno sproži začetek drugega primerka z isto konfiguracijo vašega trenutnega strežnika s pomočjo AMI vašega strežnika.
Nato sledi naslednji del, kjer moramo svoj promet enakomerno razdeliti ali usmeriti med primere, ki so na novo začeli, za to bi poskrbel izravnalnik obremenitve v AWS. Teža, ki uravnoteži promet, razdeli promet na podlagi obremenitve v določenem sistemu, opravijo notranji postopek, da se odločijo, kam usmeriti promet.
Ustvarjanje novega primerka je odvisno samo od niza pravil, ki jih določi uporabnik, ki konfigurira samodejno spreminjanje. Pravila so lahko tako preprosta, kot je na primer uporaba CPU-ja, konfigurirate lahko samodejno prilagajanje, ko poraba CPE-ja doseže 70 -80%, nato pa želite zagnati nov primerek za obdelavo prometa. Obstajajo lahko tudi pravila za zmanjšanje obsega.
Komponente za samodejno skaliranje v AWS
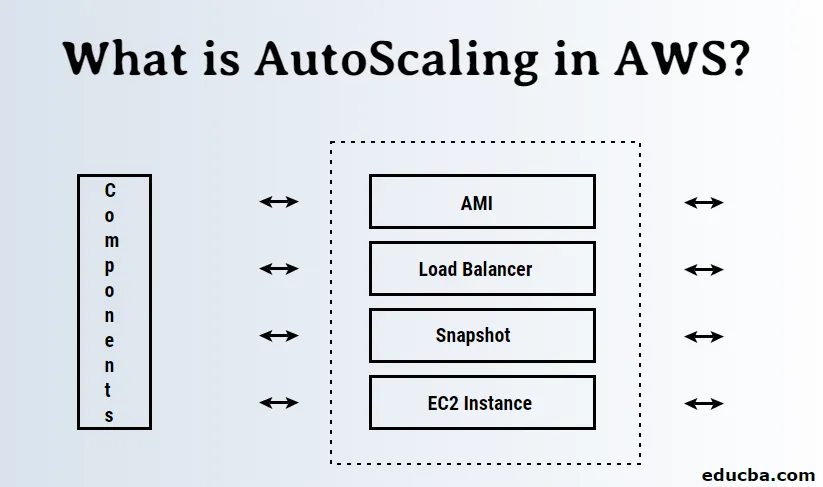
V proces samodejnega označevanja je vključenih veliko komponent, nekatere smo že poimenovali kot AMI, Load balancers in obstajajo tudi nekatere druge.
Sestavni deli, vključeni v samodejno skaliranje:
- AMI (slika računalnika Amazon)
- Izravnava obremenitve
- Posnetek
- Primerek EC2
- Skupine za samodejno razvrščanje
Lahko je več komponent, vendar lahko rečete, da je večina komponent, ki jih je mogoče spremeniti v velikost, del avtomatskega skaliranja.
1. AMI
AMI je izvršljiva slika vašega primerka EC2, ki jo lahko uporabite za ustvarjanje novih primerkov. Če želite spremeniti svoje vire, potrebujete nov strežnik, da ima vso konfiguracijo vaših spletnih strani in je pripravljen za zagon. V AWS lahko to dosežete s AMI-ji, ki ni nič drugega kot identična izvedljiva slika sistema, ki ga lahko uporabite za ustvarjanje novih slik in bi ga isti AWS uporabil v primeru samodejnega skaliranja za zagon novih primerkov.
2. Naloži uravnoteženje
Ustvarjanje primerkov je le en del samodejnega označevanja, ki ga potrebujete tudi za razdelitev prometa med novimi primerki in to delo upravlja Balancer za obremenitev. Izravnava obremenitve lahko samodejno prepozna promet po sistemih, na katere je povezan, in lahko zahteve preusmeri na podlagi pravil ali klasično na primere z manj obremenitve. Postopek razdelitve prometa med primerki, ki mu rečemo izravnava obremenitve. Težave za obremenitev se uporabljajo za povečanje zanesljivosti aplikacije in učinkovitosti ravnanja s sočasnimi uporabniki.
Uravnavanje obremenitve daje zelo pomembno vlogo pri samodejnem merjenju. Običajno so lahko tehtnice za obremenitev dve vrsti: -
- Klasični uravnotežilec obremenitve.
- Izravnalnik obremenitve aplikacije.
Classic Load Balancer: - Klasični uravnotežilec obremenitve sledi zelo preprostemu pristopu, saj bo promet enakomerno porazdelil na vse primere. Je zelo osnovna in dandanes nihče ne uporablja klasičnega regulatorja obremenitve. Lahko bi bila dobra izbira za preprosto spletno stran s statično html stranjo, vendar v trenutnih scenarijih obstajajo hibridne aplikacije ali večkomponentne aplikacije in aplikacije za visoko računanje, ki vsebuje številne komponente, namenjene določenemu delu.
Izravnalnik obremenitve aplikacije
- Najpogosteje uporabljena vrsta izravnalnika obremenitve, pri katerem se preusmeri promet na podlagi določenih preprostih ali zapletenih pravil, ki lahko temeljijo na "poti" ali "gostitelju" ali kot je določeno uporabniku.
- Bolje bi bilo, če vzamemo scenarij vloge za obdelavo dokumentov.
- Recimo, da imate aplikacijo, ki temelji na mikroservisni arhitekturi ali monolitni, pot "/ dokument" pa je značilna za storitev obdelave dokumentov in druge poti "/ poročila", ki prikazuje le poročila dokumentov, ki se obdelujejo, in statistiko o obdelanih podatkih. Za en strežnik imamo lahko skupino za samodejno spreminjanje vrednosti, ki je odgovorna za obdelavo dokumentov, druga pa samo za prikazovanje poročil.
- V orodju za uravnoteženje obremenitev aplikacije lahko konfigurirate in nastavite pravilo v skladu s potjo, ki se, če se pot ujema z "/ dokumentom", nato preusmeri v skupino za samodejno povezovanje za strežnik 1 ali če se ujema s potjo "/ poročila", nato pa jo preusmeri v skupino za samodejno skali strežnik 2. Notranjost ene skupine ima lahko več primerkov, obremenitev pa bo razdeljena v klasični obliki, pomeni enakovredno med instancami.
3. Posnetek
Kopija podatkov, ki jih imate na trdem disku, je ponavadi slika vaše shrambe. Značilna razlika med posnetkom in AMI je izvršljiva slika, ki jo lahko uporabite za ustvarjanje novega primerka, vendar je posnetek le kopija podatkov, ki jih imate v vašem primerku. Če imate posnetek posnetka primerka EC2, bi bil posnetek kopije tistih blokov, ki so spremenjeni od prejšnjega posnetka.
4. Primerek EC2 (elastični računalniški oblak)
Primer EC2 je virtualni strežnik v Amazonovem računalniškem oblaku Elastic (EC2), ki se uporablja za nameščanje vaših aplikacij na infrastrukturi Amazon Web Services (AWS). Storitev EC2 vam omogoča povezavo z virtualnim strežnikom s ključem za preverjanje pristnosti prek povezave SSH in omogoča namestitev različnih komponent vaše aplikacije skupaj z vašo aplikacijo.
5. Skupina za samodejno skaliranje
Je skupina primerkov EC2 in jedro Amazon EC2 AutoScaling. Ko ustvarite skupino za samodejno skaliranje, morate navesti podatke o podomrežjih in začetno število primerkov, s katerimi želite začeti.
Zaključek
Iz zgornje vsebine smo dobili dobro predstavo, kaj je samodejno skaliranje in kako pomembno je v današnjem svetu.
- Če vidimo, da se tehnologija in zahteve uporabnikov iz dneva v dan povečujejo, pa tudi njihova pričakovanja glede hitre in učinkovite uporabe.
- Odlična aplikacija je hitra, nudi vam dobro uporabniško izkušnjo in počne stvari, za katere je zgrajena, za dosego tega pa potrebujete zelo robustno podporo in tehnološki nabor.
- Potem ko se ukvarjate s podjetjem in je to hit, se bo vaša uporabniška baza verjetno povečala in prišlo bo do situacij, s katerimi boste sočasno uporabnikom kos, ko boste potrebovali samodejno skaliranje, da se lahko povečate in zmanjšate glede na okoliščine, da uporabnikom zagotovite brezhibno izkušnjo.
Z mojega vidika je skaliranje zelo pomemben vidik v današnjem svetu in danes ali jutri moramo to storiti, pojdite z AWS samodejnim skaliranjem in povečajte svoje izdelke.
Priporočeni članki
To je priročnik Kaj je samodejno skaliranje v AWS? Tu smo razpravljali o njeni definiciji, delujočih in različnih sestavnih delih samodejnega označevanja v AWS. Če želite izvedeti več, si oglejte tudi naslednji članek -
- Kaj je AWS RedShift?
- Kaj je StringBuilder v C #
- Popoln priročnik za funkcionalno testiranje
- Kaj je Back End Developer?
- Storitve skladiščenja AWS