
Uvod v vrečko in spodbudo
Vrekanje in krepitev sta dve priljubljeni metodi ansambla. Preden razumemo Bagging in krepitev, si omislimo, kaj je ansambel Učenje. Uporaba več algoritmov učenja za usposabljanje modelov z istim naborom podatkov je metoda, s pomočjo katere lahko predvidimo strojno učenje. Po prejemu napovedi za vsak model bomo uporabili tehnike povprečenja modelov, kot so tehtano povprečje, odstopanje ali največje glasovanje, da bomo dobili končno napoved. Cilj te metode je doseči boljše napovedi kot posamezni model. Tako se doseže boljša natančnost, s čimer se prepreči prekomerno opremljanje in zmanjša pristranskost in ko-variance. Dve priljubljeni metodi ansambla sta:
- Vrečka (združevanje ob zagonu)
- Povečanje
Vrečka:
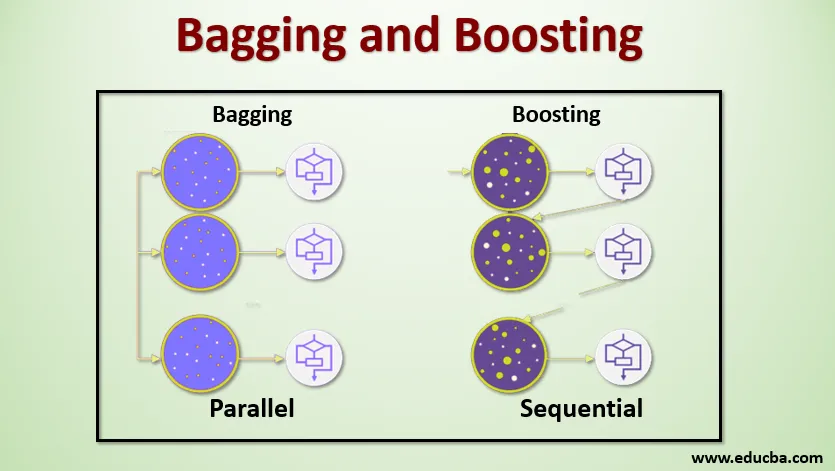
Vrečka, imenovana tudi Bootstrap Aggregating, se uporablja za izboljšanje natančnosti in model bolj posplošuje z zmanjšanjem odstopanja, tj. Z izogibanjem pretiranemu opremljanju. Pri tem vzamemo več podskupov baze podatkov o vadbi. Za vsako podmnožico vzamemo model z enakimi algoritmi učenja, kot so odločitveno drevo, logistična regresija itd., Ki napovedujejo rezultate za isti niz testnih podatkov. Ko imamo napoved za vsak model, potem uporabimo tehniko povprečnega modela, da dobimo končni rezultat napovedi. Ena izmed znanih tehnik, ki se uporablja v vrečah, je naključni gozd . V naključnem gozdu uporabljamo več dreves odločitev.
Povečanje :
Spodbujanje se uporablja predvsem za zmanjšanje pristranskosti in razlike v nadzorovani učni tehniki. Nanaša se na družino algoritmov, ki šibke učence (osnovni učenec) pretvori v močne učence. Šibki učenec so klasifikatorji, ki so le v majhni meri pravilni z dejansko klasifikacijo, medtem ko so močni učenci klasifikatorji, ki so dobro povezani z dejansko razvrstitvijo. Nekaj znanih tehnik povečevanja so AdaBoost, GRADIENT BOOSTING, XgBOOST (Extreme Gradient Boosting). Torej zdaj vemo, kaj pomenijo vrečanje in spodbujanje in kakšne so njihove vloge v strojnem učenju.
Delo vrečke in spodbude
Zdaj pa si razumemo, kako delujeta vrečanje in pospeševanje:
Vrečka
Da bi razumeli delovanje Baginga, predpostavimo, da imamo N število modelov in niz podatkov D. Kjer je m število podatkov in n število funkcij v vsakem podatku. In bi morali narediti binarno klasifikacijo. Najprej bomo razdelili nabor podatkov. Za zdaj bomo ta nabor podatkov razdelili samo na vadbeni in testni nabor. Kličimo nabor podatkov o treningu, kjer je skupno število primerov usposabljanja.
Vzemite vzorec zapisov iz nabora za vadbo in ga uporabite za urjenje prvega modela recimo m1. Za naslednji model m2 ponovno prilagodite vadbeni komplet in vzemite še en vzorec iz vadbe. To bomo storili za N število modelov. Ker prenastavimo nabor podatkov o vadbi in odvzamemo vzorce iz njega, ne da bi odstranili ničesar iz nabora podatkov, je mogoče, da imamo dva ali več zapisov podatkov o vadbi, skupnih v več vzorcih. Ta tehnika preoblikovanja nabora podatkov o usposabljanju in podajanju vzorca vzorcu se imenuje vzorčenje vrst z nadomestitvijo. Recimo, da smo usposobili vsak model in zdaj želimo videti napoved na testnih podatkih. Ker delamo na izhodu binarne klasifikacije, je lahko 0 ali 1. Testni podatkovni niz se prenese na vsak model in od vsakega modela dobimo napoved. Recimo iz N modelov, da je več kot N / 2 modelov predvidevalo, da bo 1, zato z uporabo tehnike povprečenja modelov, kot je največje število glasov, lahko rečemo, da je predvideni rezultat za testne podatke 1.
Povečanje
Pri spodbuditvi vzamemo zapise iz nabora podatkov in jih zaporedoma posredujemo osnovnim učencem, tukaj je lahko osnovni učencem kateri koli model. Recimo, da imamo v zbirki podatkov m število zapisov. Nato posredujemo nekaj zapisov, da osnujemo BL1 učenca in ga izurimo. Ko se BL1 usposobi, prenesemo vse zapise iz nabora podatkov in vidimo, kako deluje osnovni učenec. Za vse zapise, ki jih osnovni učenec napačno razvrsti, jih vzamemo samo in jih posredujemo drugemu učencu, recimo BL2, hkrati pa posredujemo napačne zapise, ki jih je klasificiral BL2, za usposabljanje BL3. To bo nadaljevalo, razen če bomo določili določeno število osnovnih modelov učencev, ki jih potrebujemo. Končno združimo izhod iz teh učencev in ustvarimo močan učenec, posledično se moč napovedovanja modela izboljša. V redu. Torej zdaj vemo, kako delujeta vreča in pospeševanje.
Prednosti in slabosti vrečke in ojačanja
Spodaj so navedene glavne prednosti in slabosti.
Prednosti vrečke
- Največja prednost pakiranja je, da lahko več šibkih učencev deluje bolje kot en sam močan učenec.
- Zagotavlja stabilnost in povečuje natančnost algoritma strojnega učenja, ki se uporablja pri statističnem razvrščanju in regresiji.
- Pomaga pri zmanjševanju odstopanja, tj. Preprečuje prekomerno opremljanje.
Slabosti vrečke
- Če ni pravilno modelirana, lahko pride do velike pristranskosti, kar lahko povzroči premalo prilagajanje.
- Ker moramo uporabljati več modelov, postane računalniško drago in v različnih primerih uporabe morda ni primerno.
Prednosti pospeševanja
- Gre za eno najuspešnejših tehnik pri reševanju dvovrstnih težav s klasifikacijo.
- Dobro je obdelati manjkajoče podatke.
Slabosti povečanja
- Zaradi povečane zapletenosti algoritma je izboljšanje v realnem času težko izvedljivo v realnem času.
- Velika fleksibilnost teh tehnik ima za posledico več število parametrov, kot da neposredno vplivajo na vedenje modela.
Zaključek
Glavni korak je, da sta Bagging in Boosting paradigma strojnega učenja, v katerem uporabljamo več modelov, da rešimo isti problem in dosežemo boljšo uspešnost. Če pravilno kombiniramo šibke učence, potem lahko pridobimo stabilen, natančen in trden model. V tem članku sem podal osnovni pregled Baging and Boosting. V prihodnjih člankih boste spoznali različne tehnike, ki se uporabljajo v obeh. Na koncu bom še opomnil, da sta bagaštvo in pospeševanje med najpogosteje uporabljenimi tehnikami učenja ansambla. Prava umetnost izboljšanja zmogljivosti je v vašem razumevanju, kdaj uporabiti model in kako prilagoditi hiperparametre.
Priporočeni članki
To je priročnik za Vrekanje in krepitev. Tukaj razpravljamo o uvodu v vrečko in povečanje in deluje skupaj s prednostmi in slabostmi. Če želite izvedeti več, lahko preberete tudi druge naše predlagane članke -
- Uvod v ansambelske tehnike
- Kategorije algoritmov strojnega učenja
- Algoritem ojačanja gradienta s kodo vzorca
- Kaj je spodbujevalni algoritem?
- Kako ustvariti odločitveno drevo?