
Razlika med strojnim učenjem in prediktivno analitiko
Strojno učenje je področje računalništva, ki v teh dneh narašča. Nedavni napredek na področju strojnih tehnologij, ki je povzročil ogromno povečanje računalniške moči, kot sta GPU (grafične procesne enote) in napredek v nevronskih omrežjih, je strojno učenje postalo grozljiva beseda. V bistvu s pomočjo tehnik strojnega učenja lahko sestavimo algoritme za pridobivanje podatkov in iz njih vidimo pomembne skrite podatke. Napovedna analitika je tudi del področja strojnega učenja, ki je omejen na napovedovanje prihodnjih rezultatov iz podatkov na podlagi predhodnih vzorcev. Medtem ko se napovedna analitika uporablja že več kot dve desetletji, predvsem v bančnem in finančnem sektorju, je uporaba strojnega učenja v zadnjem času postala pomembna z algoritmi, kot so zaznavanje predmetov iz slik, besedilna klasifikacija in sistem priporočil.
Strojno učenje
Strojno učenje interno uporablja statistike, matematiko in osnove računalništva za izdelavo logike za algoritme, ki lahko klasificirajo, napovedujejo in optimizirajo tako v realnem času kot tudi v paketnem načinu. Razvrstitev in regresija sta dva glavna razreda problema strojnega učenja. Podrobneje razumemo tako strojno učenje kot napovedno analitiko.
Razvrstitev
V teh ved težavah ponavadi predmet glede na različne lastnosti razvrstimo v enega ali več razredov. Na primer, razvrščanje komitenta banke, da je upravičen do stanovanjskega posojila ali ne, na podlagi njegove kreditne zgodovine. Običajno bi imeli za stranko na voljo podatke o transakcijah, kot so njegova starost, dohodek, izobrazba, njegove delovne izkušnje, industrija, v kateri dela, število vzdrževanih članov, mesečni stroški, prejšnja posojila, če obstajajo, njegov način porabe, kreditna zgodovina itd. Na podlagi teh informacij bi izračunali, ali mu je treba dati posojilo ali ne.
Obstaja veliko standardnih algoritmov strojnega učenja, ki se uporabljajo za reševanje problema klasifikacije. Logistična regresija je ena takšnih metod, verjetno najbolj razširjena in najbolj znana, tudi najstarejša. Poleg tega imamo tudi nekaj najnaprednejših in najbolj zapletenih modelov, od drevesa odločanja do naključnega gozda, AdaBoost, XP boost, podporne vektorske stroje, naivne baize in nevronske mreže. Od zadnjih nekaj let poglobljeno učenje teče v ospredju. Za razvrščanje slik se običajno uporabljajo nevronske mreže in globoko učenje. Če je na stotine tisoč slik mačk in psov in želite napisati kodo, s katero lahko samodejno ločite slike mačk in psov, boste morda želeli iskati metode globokega učenja, kot je konvolucijsko nevronsko omrežje. Torch, kavarna, pretok senzorjev itd. So nekatere izmed priljubljenih knjižnic pythona, ki se ukvarjajo s poglobljenim učenjem.
Za merjenje natančnosti regresijskih modelov se uporabljajo meritve, kot so lažno pozitivna hitrost, napačno negativna stopnja, občutljivost itd.
Regresija
Regresija je še en razred težav v strojnem učenju, kjer poskušamo napovedati stalno vrednost spremenljivke namesto razreda, za razliko od klasičnih problemov. Regresijske tehnike se običajno uporabljajo za napovedovanje cene delnice, prodajne cene hiše ali avtomobila, povpraševanja po določenem predmetu itd. Ko se začnejo pojavljati tudi lastnosti časovnih vrst, postanejo regresijski problemi zelo zanimivi za reševanje. Linearna regresija z navadnim najmanjšim kvadratom je eden izmed klasičnih algoritmov strojnega učenja na tej domeni. Za vzorec, ki temelji na časovnih vrstah, se uporabljajo ARIMA, eksponentno drsno povprečje, tehtano drseče povprečje in preprosto drsno povprečje.
Za merjenje natančnosti regresijskih modelov se uporabljajo meritve, ki pomenijo povprečno kvadratno napako, absolutno povprečno kvadratno napako, korensko meritev kvadratne napake itd.
Predvidevanje Analytics
Med strojnim učenjem in napovedno analitiko obstaja nekaj področij. Medtem ko običajne tehnike, kot sta logistična in linearna regresija, sodijo tako v strojno učenje kot v napovedno analitiko, so napredni algoritmi, kot je drevo odločanja, naključni gozd itd., V bistvu strojno učenje. Pod napovedno analitiko je cilj težav še vedno zelo ozek, kjer je namen izračunati vrednost določene spremenljivke v prihodnjem obdobju. Napovedna analitika je močno obremenjena s statistiko, medtem ko je strojno učenje bolj kombinacija statistike, programiranja in matematike. Tipični napovedni analitik porabi čas za računanje t kvadrata, f statistike, Innova, chi-kvadrat ali navadni najmanjši kvadrat. Vprašanja, na primer, ali so podatki običajno razporejeni ali nagnjeni, ali se uporablja študentska t distribucija ali se uporablja krivulja zvončkov, če bi alfa sprejemali 5% ali 10% hrošč. Hudiča podrobno iščejo. Strojni inženir učenja se pri teh veliko težavah ne trudi. Njihov glavobol je popolnoma drugačen, zato se znajdejo pri izboljšanju natančnosti, lažnem pozitivnem zmanjševanju hitrosti, zunanjem upravljanju, normalizaciji območja ali potrjevanju k krat.
Napovedni analitik večinoma uporablja orodja, kot so excel. Scenarij ali cilj so najljubši. Občasno uporabljajo VBA ali micros in komaj napišejo kakšno dolgotrajno kodo. Inženir strojnega učenja ves svoj čas porabi za pisanje zapletene kode, ki presega splošno razumevanje, uporablja orodja, kot so R, Python, Saas. Programiranje je njihovo glavno delo, odpravljanje napak in testiranje različnih pokrajin vsakodnevna rutina.
Te razlike prinašajo tudi veliko razliko v povpraševanju in plači. Medtem ko so napovedni analitiki tako včeraj, je strojno učenje prihodnost. Tipični inženir strojnega učenja ali podatkovni znanstvenik (kot ga danes večinoma imenujejo) so plačani 60-80% več kot tipični programski inženir ali napovedni analitik za to zadevo in so ključni dejavnik v današnjem tehnološkem svetu. Uber, Amazon in zdaj samovozeči avtomobili so možni tudi samo zaradi njih.
Primerjava med računalniki med strojnim učenjem in napovedovalno analitiko (Infographics)
Spodaj je zgornjih 7 primerjav med strojnim učenjem in napovedno analitiko
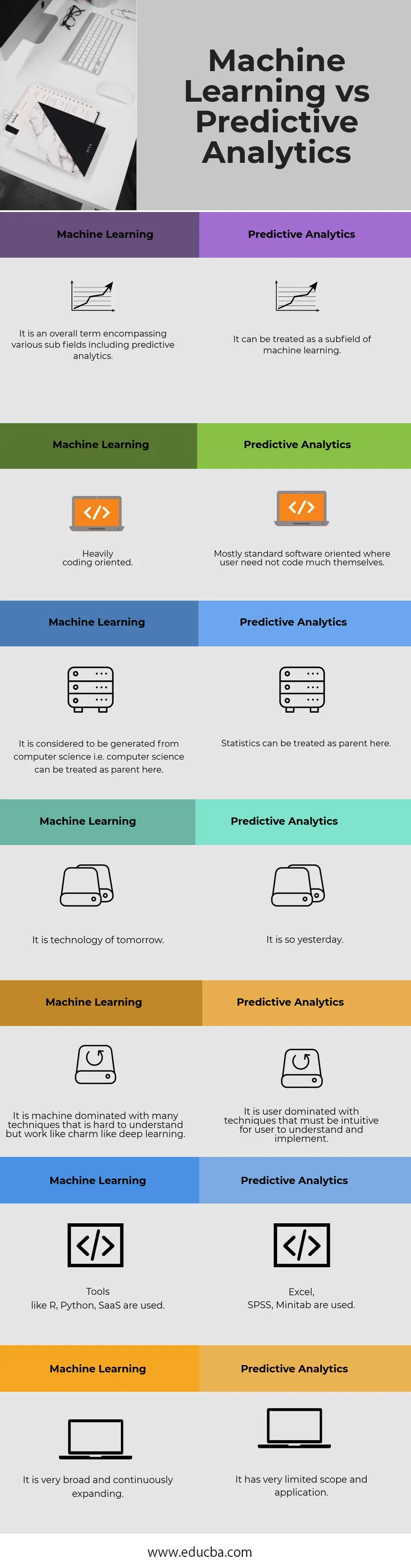
Tabela strojnega učenja v primerjavi s predvidevanjem analitične analitike
Spodaj je podrobna razlaga strojnega učenja pred napovedovalno analitiko
| Strojno učenje | Predvidevanje Analytics |
| Gre za celoten izraz, ki vključuje različna podpolja, vključno s prediktivno analitiko. | Lahko ga obravnavamo kot podpolje strojnega učenja. |
| Močno kodiran. | Večinoma standardno programsko usmerjene, kjer uporabniku ni treba veliko kodirati |
| Šteje se, da je nastala iz računalništva, tj. Računalništvo se lahko tu obravnava kot starš. | Tukaj lahko statistiko obravnavamo kot starša. |
| To je tehnologija jutrišnjega dne. | Včeraj je tako. |
| To je stroj, v katerem prevladujejo številne tehnike, ki jih je težko razumeti, vendar delujejo kot čar kot globoko učenje. | Uporabniki prevladujejo s tehnikami, ki morajo biti intuitivne za razumevanje in izvajanje uporabnika. |
| Uporabljajo se orodja kot so R, Python, SaaS. | Uporabljajo se Excel, SPSS, Minitab. |
| Je zelo široka in se nenehno širi. | Ima zelo omejen obseg in uporabo. |
Zaključek - Strojno učenje v primerjavi z napovedno analitiko
Iz zgornje razprave o strojnem učenju in prediktivni analitiki je razvidno, da je napovedna analitika v bistvu podpolje strojnega učenja. Strojno učenje je bolj vsestransko uporabno in lahko reši široko paleto težav.
Priporočeni članek
To je vodnik za strojno učenje in napovedno analitiko, njihov pomen, primerjava med seboj, ključne razlike, tabela primerjave in sklep. Če želite izvedeti več, si oglejte tudi naslednje članke -
- Naučite se velikih podatkov o strojnem učenju
- Razlika med podatkovnim znanjem in strojnim učenjem
- Primerjava med Predictive Analytics in Data Science
- Data Analytics Vs Predictive Analytics - Kateri je uporaben