

Razlika med MapReduce in Spark
Map Reduce je odprtokodni okvir za pisanje podatkov v HDFS in obdelavo strukturiranih in nestrukturiranih podatkov, ki so prisotni v HDFS. Zmanjšanje zemljevidov je omejeno na paketno obdelavo, na drugih Sparkih pa lahko izvajajo katero koli vrsto obdelave. SPARK je neodvisen procesor za obdelavo v realnem času, ki ga je mogoče namestiti v kateri koli sistem distribuirane datoteke, kot je Hadoop. SPARK zagotavlja zmogljivost, ki je 10-krat hitrejša od zmanjšanja zemljevidov na disku in 100-krat hitrejša od zmanjšanja zemljevidov v omrežju v pomnilniku.
Need for SPARK
- Iterative Analytics: Zmanjšanje zemljevidov ni tako učinkovito kot SPARK za reševanje težav, ki zahtevajo iterativno analitiko, saj mora iti na disk za vsako ponovitev.
- Interaktivna analitika: Zmanjšanje zemljevidov se pogosto uporablja za izvajanje ad-hoc poizvedb, za katere mora priti do diskovnega pomnilnika, ki spet ni tako učinkovit kot SPARK, ker se slednji sklicuje v pomnilnik, ki je hitrejši.
- Ni primerno za OLTP: Ker deluje na paketno naravnanem okviru, ni primeren za veliko število kratkih transakcij.
- Ni primerno za graf: Knjižnica Apache Graph obdeluje graf, ki doda večjo zapletenost zmanjšanju zemljevidov.
- Ni primerno za trivialne operacije: Pri operacijah, kot je filter in združuje, bomo morda morali prepisati opravila, ki postanejo bolj zapletena zaradi vzorca ključ-vrednost.
Primerjava med mestoma MapReduce proti Spark (Infographics)
Spodaj je zgornjih 15 razlik med MapReduce in Spark

Ključne razlike med MapReduce proti Spark
Spodaj so seznami točk, opišite ključne razlike med MapReduce in Spark:
- Spark je primeren za sprotni čas, ko obdeluje spomin, medtem ko je MapReduce omejen na paketno obdelavo.
- Spark ima RDD (Resilient Distributed Dataset), ki nam omogoča operaterje na visoki ravni, vendar v zmanjšanju Map moramo kodirati vsako operacijo, kar otežuje primerjavo.
- Spark lahko obdeluje grafe in podpira orodje Strojno učenje.
- Spodaj je razlika med ekosistemom MapReduce in Spark.
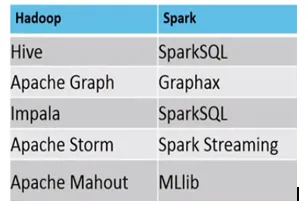
Primer, kjer je MapReduce proti Spark primeren, je naslednji
Iskra: odkrivanje goljufij s kreditno kartico
MapReduce: Pripravljanje rednih poročil, ki zahtevajo odločanje.
Tabela primerjave MapReduce proti iskri
| Osnova za primerjavo | MapReduce | Iskra |
| Okvir | Odprt okvir za pisanje podatkov v HDFS in obdelavo strukturiranih in nestrukturiranih podatkov, ki so prisotni v HDFS. | Odprt okvir za hitrejšo in splošno rabo podatkov |
| Hitrost | Map-Reduce procesiranje podatkov (branje in pisanje) z diska, tako da je iskalnik počasen v primerjavi z iskrico. | Spark je vsaj 10X hitrejši na disku in 100X hitrejši v pomnilniku kot kartica Map Reduce. |
| Težavnost | Vsak postopek moramo kodirati / obdelati. | Z razpoložljivostjo RDD (Resilient Distributed Dataset) je enostavno programiranje. |
| V realnem času | Ni primerno za transakcije OLTP samo za paketni način | Lahko prenese obdelavo v realnem času. Uporaba pretoka SPARK. |
| Zamuda | Okvir računalniškega zakasnitve na visoki ravni | Računalniški okvir z nizko stopnjo zakasnitve. |
| Toleranca napak | Glavni demoni preverijo srčni utrip demonov sužnjev in v primeru, da demoni suženj ne uspejo, glavni demoni prestaviti vse čakajoče in tekoče delovanje na drugega sužnja. | RDD-ji zagotavljajo odstopanje napak do sistema SPARK. Nanašajo se na niz podatkov, ki je prisoten v zunanji shrambi (HDFS, HBase) in delujejo vzporedno. |
| Planer | V programu Map Reduce uporabljamo zunanji planer, kot je Oozie. | Medtem ko SPARK deluje z računalništvom v pomnilniku, deluje kot lasten razporejevalec. |
| Cena | Zmanjšanje zemljevida je v primerjavi s sistemom SPARK razmeroma cenejše. | Ker deluje v pomnilniku, zato potrebuje veliko RAM-a, zato je sorazmerno dražji. |
| Platforma, razvita naprej | Map Reduce je razvit s pomočjo Jave. | SPARK je bil razvit z uporabo Scale. |
| Podprt jezik | Map Reduce v osnovi podpira C, C ++, Ruby, Groovy, Perl, Python. | Spark podpira Scala, Java, Python, R, SQL. |
| Podpora za SQL | Map Reduce izvaja poizvedbe z jezikom poizvedb. | Spark ima svoj poizvedbeni jezik, znan kot Spark SQL. |
| Prilagodljivost | V zmanjšanju zemljevida lahko dodamo do n število vozlišč. Največji grozd Hadoop ima 14000 vozlišč. | Tudi v Spark lahko dodamo n število vozlišč. Največji skupin Spark ima 8000 vozlišč. |
| Strojno učenje | Map Reduce podpira orodje Apache Mahout za strojno učenje. | Spark podpira MLlib orodje za strojno učenje. |
| Predvajanje | Zmanjšanje zemljevidov ne more predpomniti pomnilniških podatkov, zato ni tako hitro kot v primerjavi s Sparkom. | Spark shrani podatke v pomnilniku za nadaljnje iteracije, tako da je zelo hiter v primerjavi z zmanjšanjem zemljevida. |
| Varnost | Map Reduce podpira več varnostnih projektov in funkcij v primerjavi s Spark | Varnost iskric še ni zrela kot varnost zmanjšanja zemljevidov |
Zaključek - MapReduce proti Spark
Glede na zgornjo razliko med MapReduce in Spark je povsem jasno, da je SPARK v primerjavi z Map Reduce bistveno naprednejši računalniški motor. Spark je združljiv s katero koli obliko zapisa datoteke in je tudi precej hitrejši od zmanjšanja zemljevidov. Iskra ima poleg tega tudi obdelavo grafi in zmogljivosti strojnega učenja.
Po eni strani je zmanjšanje zemljevidov omejeno na paketno obdelavo, na drugi pa je Spark sposoben izvesti katero koli vrsto obdelave (paketna, interaktivna, iterativna, pretočna grafika). Zaradi velike združljivosti je Spark najljubši Data Scientist in zato nadomešča Map Zmanjšaj in hitro raste. Še vedno pa moramo podatke shraniti v HDFS in tudi kdaj bomo morda potrebovali HBase. Zato moramo zagnati tako Spark kot Hadoop, da dosežemo najboljše.
Priporočeni članki:
To je vodnik za MapReduce vs Spark, njihov pomen, primerjava med seboj, ključne razlike, tabela primerjave in sklep. Če želite izvedeti več, si oglejte tudi naslednje članke -
- 7 pomembnih stvari o Apache Spark (vodnik)
- Hadoop proti Apache Spark - zanimive stvari, ki jih morate vedeti
- Apache Hadoop in Apache Spark | Top 10 primerjav, ki jih moraš vedeti!
- Kako deluje MapReduce?
- Sotočje tehnologije in poslovne analitike