

Uvod v Pridružitev v Spark SQL
Kot vemo, se združitve v SQL uporabljajo za združevanje podatkov ali vrstic iz dveh ali več tabel, ki temeljijo na skupnem polju med njimi. V tej temi bomo spoznali Pridruži se v Spark SQL Pridruži se v Spark SQL.
V Spark SQL sta Dataframe ali Dataset tabelarna struktura v spominu, ki vsebuje vrstice in stolpce, razporejene po več vozliščih. Tako kot običajne tabele SQL lahko tudi v operacijskem sistemu Dataframe ali Dataset v Spark SQL izvajamo združitvene operacije na podlagi skupnega polja med njimi.
V SQL so na voljo različne vrste operacij pridruživanja. Glede na primer poslovne uporabe se odločimo za operacijo Join. V naslednjem razdelku bomo na primeru prikazali vsako vrsto združevanja.
Vrste pridruževanja v iskanju SQL
V Spark SQL so na voljo različne vrste združitev:
- UNUTAR PRIDRUŽITE SE
- CROSS PRIDRUŽITE se
- LEVO ZUNAJ PRIDRUŽITE se
- PRAVI ZDRUŽITE SE
- POPOLNI ZDRUŽITE SE
- LEVO SEMI PRIDRUŽITE SE
- LEVO ANTI PRIDRUŽITE se
Primer ustvarjanja podatkov
Naslednje podatke bomo uporabili za prikaz različnih vrst pridružitev:
Knjižni nabor podatkov:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
bookDS.show()

Nabor podatkov za Writer:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Vrste pridružitev
Spodaj je omenjenih 7 različnih vrst pridruživanja:
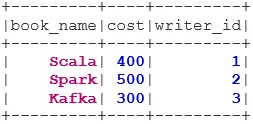
1. UNUTAR PRIDRUŽITE SE
INNER JOIN vrne nabor podatkov, ki ima vrstice, ki imajo ujemajoče se vrednosti v obeh nizih podatkov, tj. Vrednost skupnega polja bo enaka.
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. CROSS PRIDRUŽITE se
CROSS JOIN vrne nabor podatkov, ki je število vrstic v prvem naboru podatkov, pomnoženo s številom vrstic v drugem naboru podatkov. Takšen rezultat se imenuje kartuzijanski izdelek.
Predpogoj: Če želite uporabiti navzkrižno povezavo, mora biti spark.sql.crossJoin.enabled nastavljeno na true. V nasprotnem primeru bo vržena izjema.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
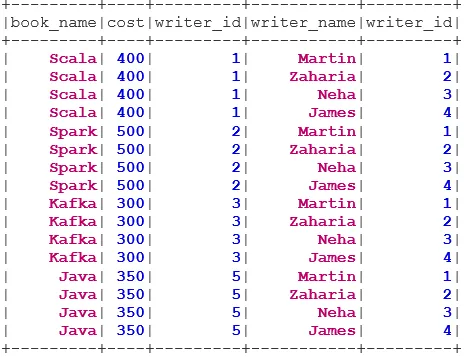
3. LEVO ZUNANJE PRIDRUŽITE se
LEFT OUTER JOIN vrne nabor podatkov, ki ima vse vrstice z levega nabora podatkov, in izravnane vrstice iz desnega nabora podatkov.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. PRAVI ZDRUŽI SE
RIGHT OUTER JOIN vrne nabor podatkov, ki ima vse vrstice z desnega nabora podatkov, in ujemajoče se vrstice z levega nabora podatkov.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. POPOLNI ZDRUŽITE SE
FULL OUTER JOIN vrne nabor podatkov, v katerem so vse vrstice, če se ujemajo levi ali desni nabor podatkov.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. LEVO SEMI PRIDRUŽITE se
LEFT SEMI JOIN vrne nabor podatkov, ki ima vse vrstice z levega nabora podatkov in njihovo korespondenco v desnem naboru podatkov. Za razliko od LEFT OUTER JOIN vrnjeni nabor podatkov v LEFT SEMI JOIN vsebuje le stolpce z levega nabora podatkov.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. LEVO ANTI PRIDRUŽITE se
ANTI SEMI JOIN vrne nabor podatkov, ki ima vse vrstice z levega nabora podatkov, ki se ne ujemajo v pravem naboru podatkov. Vsebuje tudi samo stolpce iz levega nabora podatkov.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Zaključek - Pridružite se Spark SQL
Pridružitev podatkov je ena najpogostejših in najpomembnejših operacij za izpolnjevanje primera naše poslovne uporabe. Spark SQL podpira vse osnovne vrste združitev. Medtem ko se pridružujemo, moramo upoštevati tudi uspešnost, saj bodo morda potrebni veliki omrežni prenosi ali celo ustvarili nabore podatkov, ki niso v skladu z našimi zmožnostmi. Za izboljšanje zmogljivosti Spark za ponovno naročilo ali potiskanje filtrov uporablja SQL optimizer. Iskra tudi omeji nevarno povezavo i. e CROSS PRIDRUŽITE se. Za uporabo navzkrižnega spajanja mora biti spark.sql.crossJoin.enabled izrecno nastavljeno na true.
Priporočeni članki
To je vodnik za Pridružitev v Spark SQL. Tukaj razpravljamo o različnih vrstah združitev, ki so na voljo v Spark SQL s primerom. Lahko pogledate tudi naslednji članek.
- Vrste združitev v SQL
- Tabela v SQL
- Poizvedba za vstavljanje SQL
- Transakcije v SQL
- PHP filtri | Kako preveriti uporabniški vnos z različnimi filtri?