

Uvod v funkcije v R
Funkcija je opredeljena kot sklop stavkov, ki izvaja in izvaja katero koli točno določeno logično nalogo. Funkcija prevzame nekaj vhodnih parametrov, ki so znani kot argumenti za izvajanje te naloge. Funkcije pomagajo pri razbijanju kode, v preprostejše kose, tako da jih logično orkestriramo, kar je lažje prebrati in razumeti. V tej temi bomo spoznali Funkcije v R.
Kako napisati funkcije v R?
Če želite napisati funkcijo v R, je tukaj sintaksa:
Fun_name <- function (argument) (
Function body
)
Tu lahko vidimo, da je v R uporabljena posebna rezervirana beseda "funkcija", ki definira katero koli funkcijo. Funkcija sprejme vhod, ki je v obliki argumentov. Funkcijsko telo je niz logičnih stavkov, ki se izvajajo prek argumentov in nato vrne izhod. "Fun_name" je ime funkcije, s pomočjo katere ga je mogoče poklicati kjer koli v programu R.
Poglejmo primer, ki bo bolj razumljiv pri razumevanju koncepta funkcije v R.
R koda
Multi <- function(x, y) (
# function to print x multiply y
result <- x*y
print(paste(x, "Multiply", y, "is", result))
)
izhod:
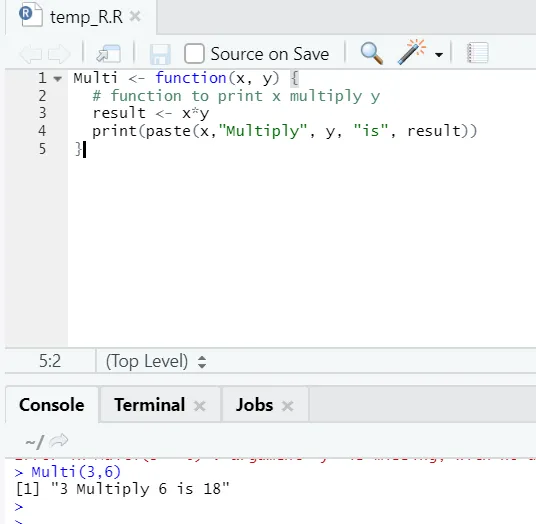
Tu smo ustvarili ime funkcije "Multi", ki ima dva vira kot vhode in zagotavlja pomnoženi izhod. Prvi argument je x, drugi argument pa y. Kot vidite, smo funkcijo poimenovali z imenom "Multi". Če nekdo želi, lahko argumente nastavite tudi na privzeto vrednost.
Različne vrste funkcij v R
Različne funkcije R s sintakso in primeri (vgrajena, matematika, statistika itd.)
1) Vgrajena funkcija -
To so funkcije, ki prihajajo skupaj z R za reševanje določene naloge tako, da vzamejo argument kot vhod in dajo izhod na podlagi danega vnosa. Tukaj razpravljamo o nekaterih pomembnih splošnih funkcijah R:
a) Razvrsti: Podatki so lahko vrstni po naraščajočem ali padajočem vrstnem redu. Podatki so lahko ne glede na to, ali je vektor nadaljevalne spremenljivke ali faktorska spremenljivka.
Sintaksa:

Tu je razlaga njegovih parametrov:
- x: To je vektor neprekinjene spremenljivke ali faktorske spremenljivke
- upada: To lahko nastavite bodisi True / False, da nadzorujete vrstni red z naraščajočo ali padajočo. Privzeto je FALSE`.
- nazadnje: Če ima vektor vrednosti NA, naj bo zadnji ali ne
R koda in izhod:
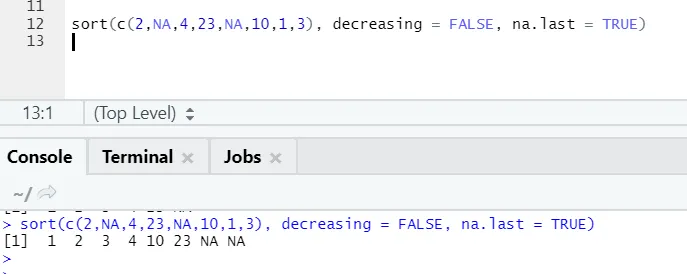
Tu lahko opazimo, kako se vrednosti „NA“ na koncu poravnajo. Kot je bil naš parameter na.last = True.
b) Seq: ustvari zaporedje števila med dvema določenima števkama.
Sintaksa
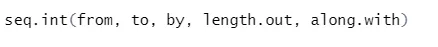
Tu je razlaga njegovih parametrov:
- od, do začetne in končne vrednosti zaporedja.
- za: Povečanje / razmik med dvema zaporednima števkama zaporedoma
- length.out: potrebna dolžina zaporedja.
- Along.with: Nanaša se na dolžino dolžine tega argumenta
R koda in izhod:
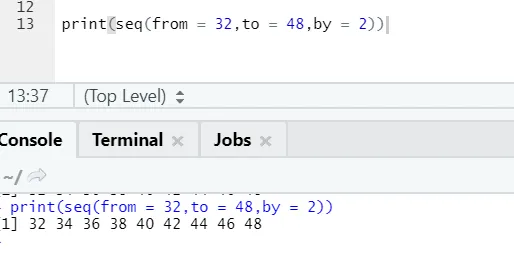
Tu lahko opazimo, da ima zaporedje ustvarjeno povečanje 2, ker je opredeljeno kot 2.
c) Toupper, tolower: Dve funkciji: toupper in tolower sta funkciji, ki sta na nizu uporabljeni za spreminjanje velikih črk v stavkih.
R koda in izhod:
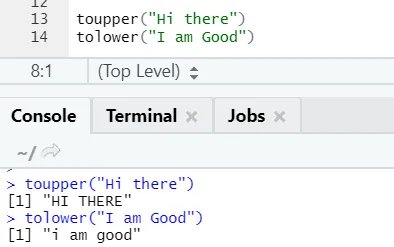
Lahko opazimo, kako se primeri črk spreminjajo, ko jih uporabimo za funkcijo.
d) Rnorm: To je vgrajena funkcija, ki ustvarja naključna števila.
R koda in izhod:
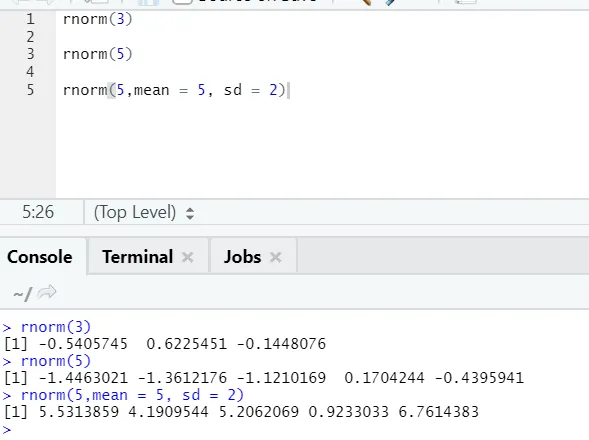
Funkcija rnorm ima prvi argument, ki pove, koliko številk je treba ustvariti.
e) Rep: Ta funkcija ponavlja vrednost tolikokrat, kot je določeno.
R sintaksa: rnorm (x, n)
Tukaj x predstavlja vrednost za ponovitev in n predstavlja število ponovitev.
R koda in izhod:
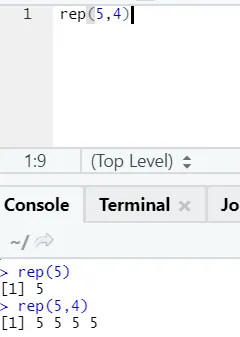
f) Prilepi: Ta funkcija je, da združi strune in nekaj posebnega znaka vmes.
skladnja
paste(x, sep = “”, collapse = NULL)
R koda
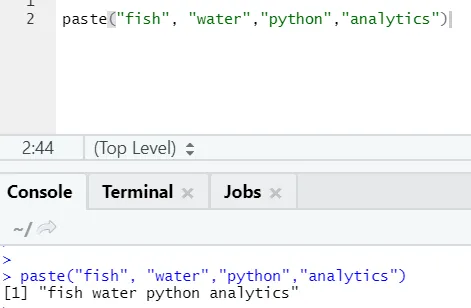
paste("fish", "water", sep=" - ")
R izhod:
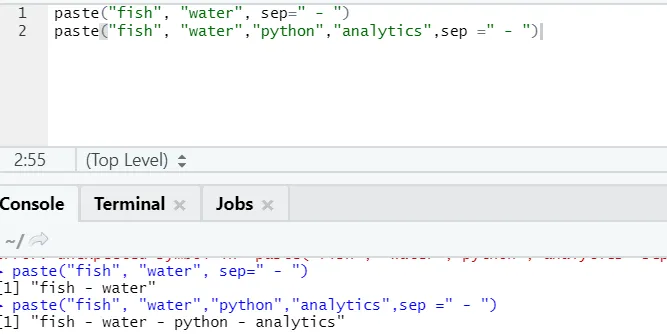
Kot vidite, lahko prilepimo tudi več kot dve struni. Sep je tisti poseben znak, ki smo ga dodali med nize. Sep je privzeto prostor.
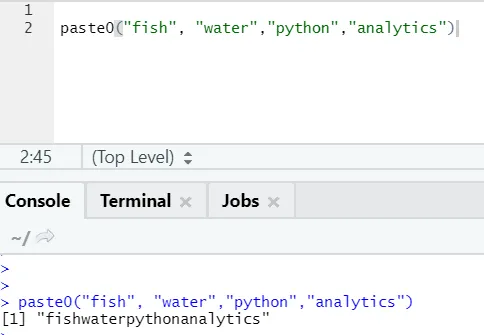
Še ena podobna funkcija obstaja, kot je ta, ki bi se je morali vsi zavedati, je paste0.
Funkcija paste0 (x, y, strni) deluje podobno kot prilepi (x, y, sep = "", strni)
Glejte spodnji primer:
Z enostavnimi besedami, če povzamemo paste in paste0:
Paste0 je hitrejši od lepljenja, če gre za povezovanje strun brez ločevalca. Ker paste vedno iščejo »sep« in je v njem privzeto prostor.
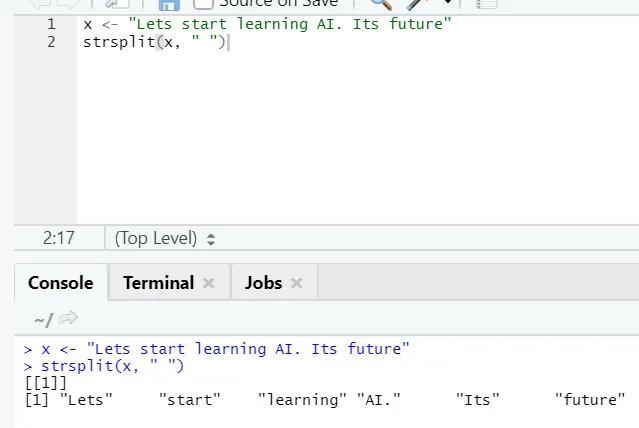
g) Strsplit: Ta funkcija je razdelitev niza. Poglejmo preproste primere:
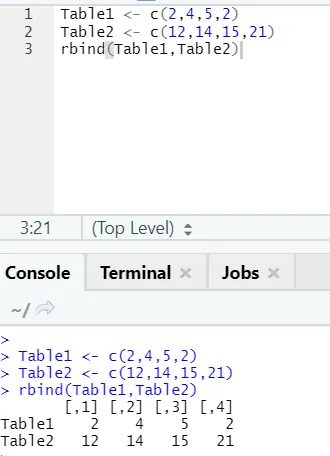
h) Rbind: funkcija rbind pomaga pri česanju vektorjev z enakim številom stolpcev, drug za drugim.
Primer
i) cbind: To združuje vektorje z enakim številom vrstic, drug ob drugem.
Primer
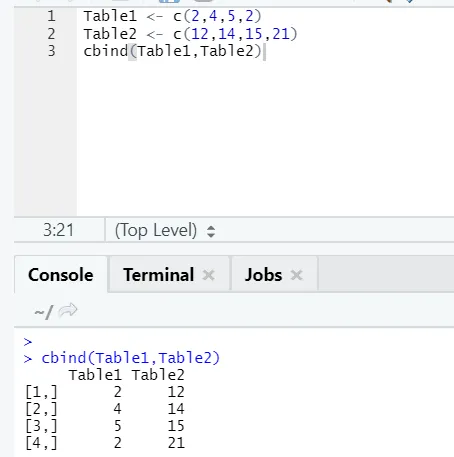
Če se število vrstic ne ujema, je spodaj navedena napaka:

Tako cbind kot rbind pomagata pri obdelavi in preoblikovanju podatkov.
2) Matematična funkcija -
R ponuja široko paleto funkcij Math. Poglejmo jih nekaj podrobno:
a) Sqrt: Ta funkcija izračuna kvadratni koren številčnega ali številčnega vektorja.
R koda in izhod:
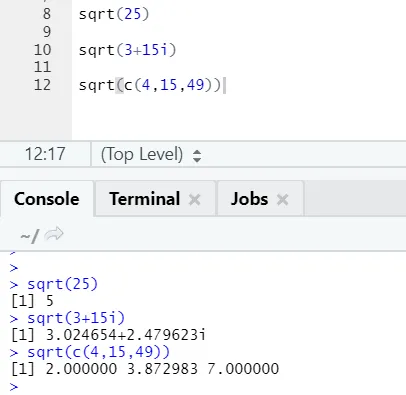
Lahko se vidi, kako je izračunano korenje števila, kompleksnega števila in zaporedja številčnega vektorja.
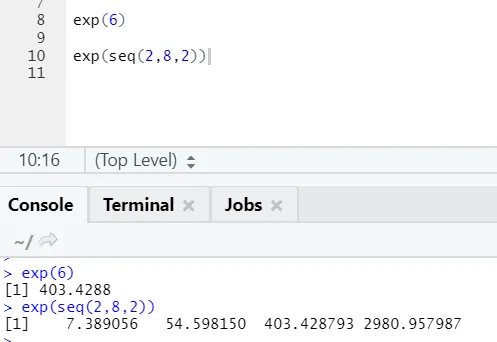
b) Exp: Ta funkcija izračuna eksponentno vrednost števila ali številčnega vektorja.
R koda in izhod:
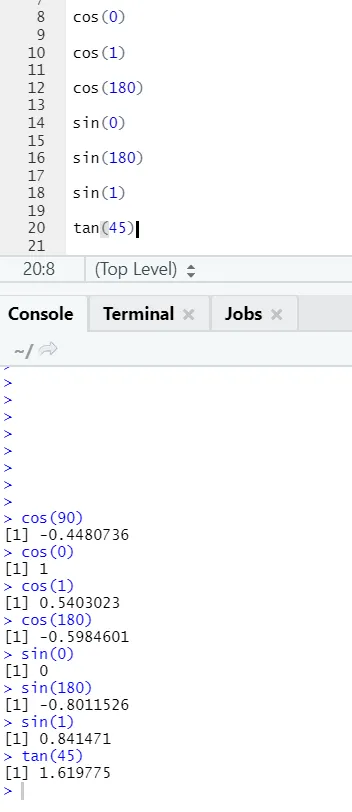
c) Cos, Sin, Tan: To so funkcije trigonometrije, izvedene v R tukaj.
R koda in izhod:
d) Abs: Ta funkcija vrne absolutno pozitivno vrednost števila.
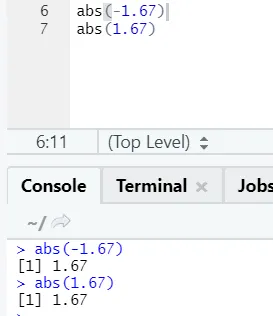
Kot lahko vidite, se bo negativno ali pozitivno število vrnilo v absolutni obliki. Poglejmo ga za kompleksno številko:
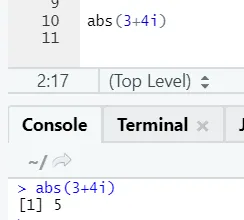
e) Dnevnik: s tem najdemo logaritem števila.
Tu je primer prikazan spodaj:
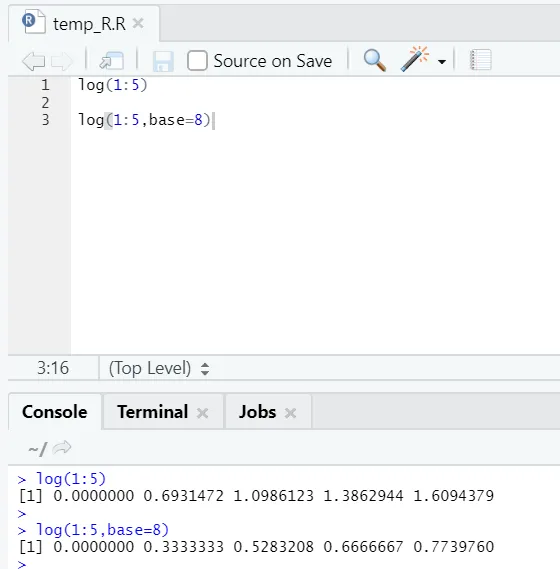
Tu dobiš prožnost za spreminjanje baze, kot je potrebno.
f) Cumsum: To je matematična funkcija, ki daje kumulativne vsote. Spodaj je primer:
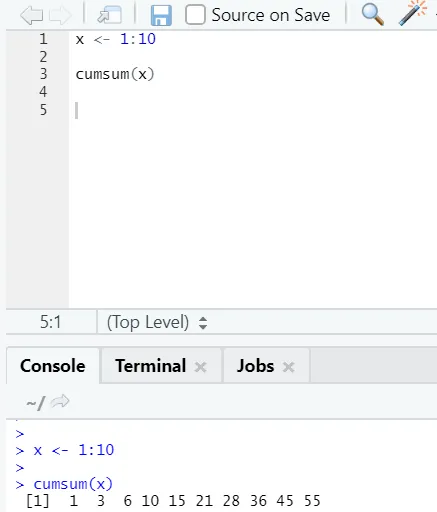
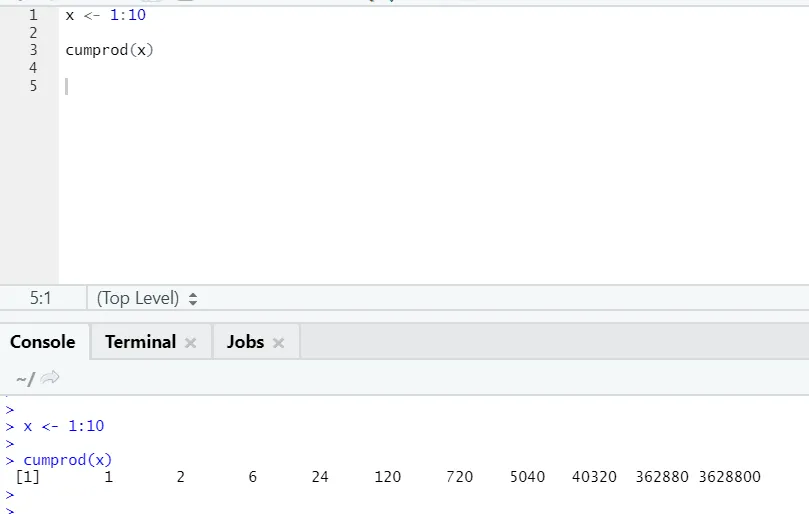
g) Cumprod: Tako kot Cumsumova matematična funkcija imamo tudi cumprod tam, kjer se zgodi kumulativno množenje.
Glejte spodnji primer:
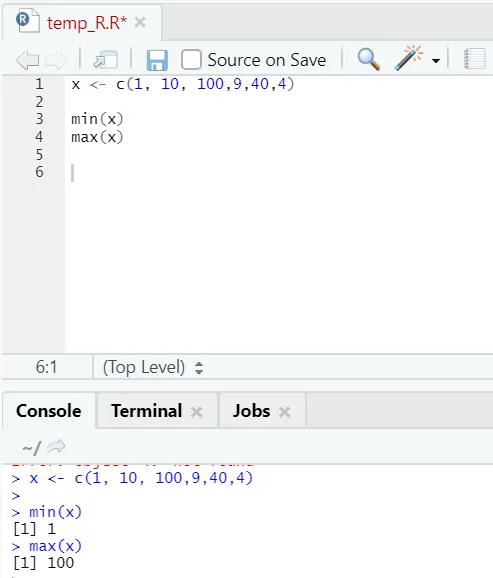
h) Max, Min: s tem boste našli največjo / najnižjo vrednost v množici števil. Glej spodaj primere v zvezi s tem:
i) Zgornja meja: zgornja meja je matematična funkcija, ki vrne najmanjše od celega števila, večjega od podanega.
Poglejmo primer:
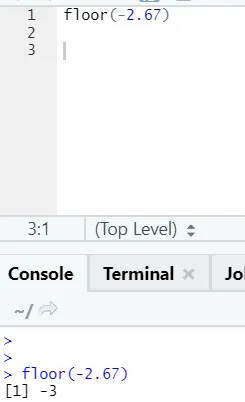
strop (2, 67)
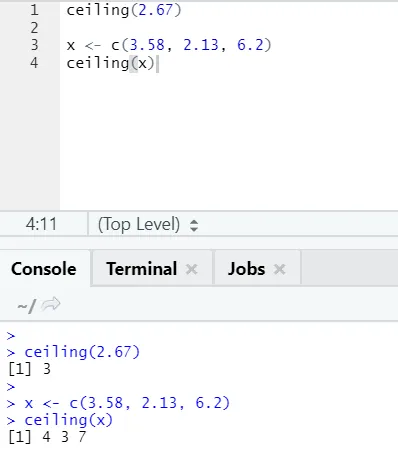
Kot lahko opazite, je zgornja meja uporabljena tako nad številom kot nad seznamom, dobljeni izhod pa je najmanjši od naslednjih višjih celih števil.
j) Nadstropje: Pod je matematična funkcija vrne celo najmanjšo vrednost celotnega števila od navedenega števila.
Spodnji primer vam bo pomagal razumeti:
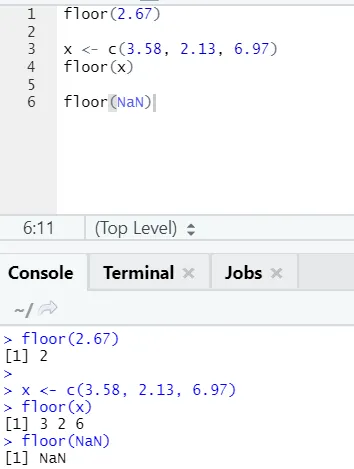
Enako deluje tudi za negativne vrednosti. Oglejte si:
3) Statistične funkcije -
To so funkcije, ki opisujejo povezano porazdelitev verjetnosti.
a) Mediana: izračunano je mediana iz zaporedja števil.
Sintaksa
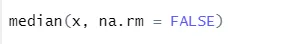
R koda in izhod:
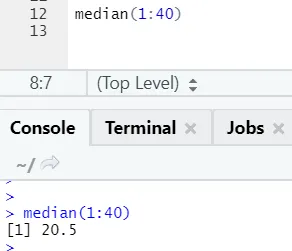
b) Dnorm: To se nanaša na normalno porazdelitev. Funkcija dnorm vrne vrednost funkcije gostote verjetnosti za normalno porazdelitev danih parametrov za x, μ in σ.
R koda in izhod:
c) Cov: Covariance pove, ali sta dva vektorja pozitivno, negativno ali popolnoma nepovezana.
R koda
x_new = c(1., 5.5, 7.8, 4.2, -2.7, -5.5, 8.9)
y_new = c(0.1, 2.0, 0.8, -4.2, 2.7, -9.4, -1.9)
cov(x_new, y_new)
R izhod:
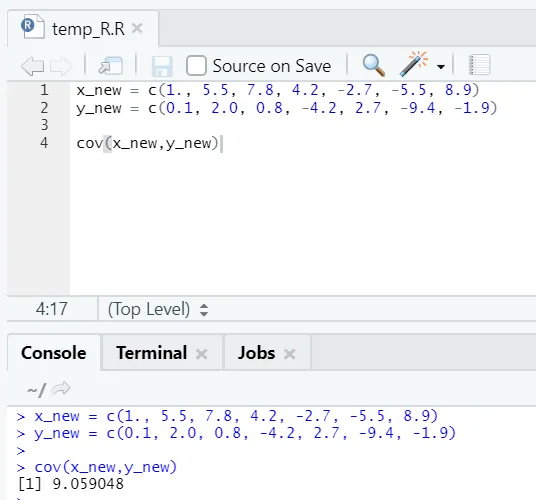
Kot vidite, sta dva vektorja pozitivno povezana, kar pomeni, da se oba vektorja premikata v isto smer. Če je kovarijanca negativna, pomeni, da sta x in y obratno povezana in se zato premika v nasprotni smeri.
d) Cor: To je funkcija za iskanje korelacije med vektorji. Dejansko daje faktor povezave med obema vektorjema, ki je znan kot "koeficient korelacije". Korelacija doda faktor stopnje glede kovariance. Če sta dva vektorja pozitivno povezana, vam bo korelacija tudi povedala, v kolikšni meri sta pozitivno povezana.
Te tri vrste metod, s katerimi je mogoče najti povezavo med dvema vektorjema:
- Pearsonova korelacija
- Kendall korelacija
- Spearmanova korelacija
V preprostem R formatu izgleda:
cor(x, y, method = c("pearson", "kendall", "spearman"))
Tu sta x in y vektorji.
Poglejmo praktični primer korelacije med vgrajenim naborom podatkov.
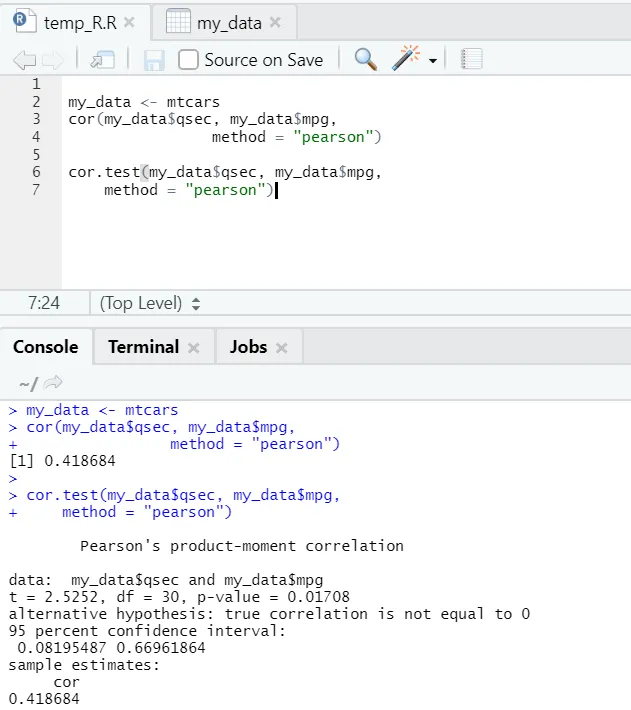
Tukaj lahko vidite, da je funkcija "cor ()" dala korelacijski koeficient 0, 41 med "qsec" in "mpg". Vendar je bila predstavljena še ena funkcija, tj. "Cor.test ()", ki ne pove le koeficienta korelacije, temveč tudi p-vrednost in t-vrednost, povezana z njo. Interpretacija postane veliko lažja s funkcijo cor.test.
Podobno je mogoče z drugimi dvema načinoma korelacije:
R koda za Pearsonovo metodo:
my_data <- mtcars
cor(my_data$qsec, my_data$mpg, method = " pearson ")
cor.test(my_data$qsec, my_data$mpg, method = " pearson")
R koda za Kendall metodo:
my_data <- mtcars
cor(my_data$qsec, my_data$mpg, method = " kendall")
cor.test(my_data$qsec, my_data$mpg, method = " kendall")
R koda za metodo Spearmana:
my_data <- mtcars
cor(my_data$qsec, my_data$mpg, method = "spearman")
cor.test(my_data$qsec, my_data$mpg, method = "spearman")
Koeficient korelacije se giblje med -1 in 1.
Če je koeficient korelacije negativen, to pomeni, da se x poveča y zmanjša.
Če je koeficient korelacije enak nič, to pomeni, da med x in y ni povezave.
Če je koeficient korelacije pozitiven, to pomeni, da se x poveča, se tudi poveča.
e) T-test: T-test vam bo povedal, ali dva nabora podatkov izhajata iz iste (ob predpostavki) običajne distribucije ali ne.
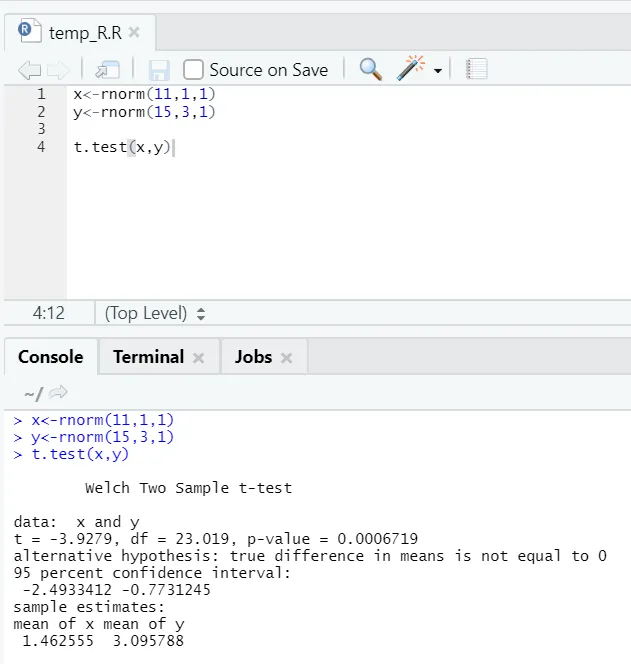
Tu bi morali zavrniti ničelno hipotezo, da sta obe srednji enaki, ker je vrednost p manjša od 0, 05.
Ta prikazani primerek je tipa: parni nabori podatkov z neenakomernimi odstopanji. Podobno je mogoče poskusiti s seznanjenim naborom podatkov.
f) Enostavna linearna regresija: Prikaže razmerje med napovednikom / neodvisno in spremenljivko, odvisno od odziva.
Preprost praktični primer bi lahko napovedoval težo osebe, če je znana višina.
R sintaksa
lm(formula, data)
Tukaj formula prikazuje razmerje med izhodno vrednostjo y in vhodno spremenljivko iex Podatki predstavljajo nabor podatkov, na katerem je treba formulo uporabiti.
Poglejmo si en praktičen primer, kjer je talna površina vhodna spremenljivka, najemnina pa izhodna spremenljivka.
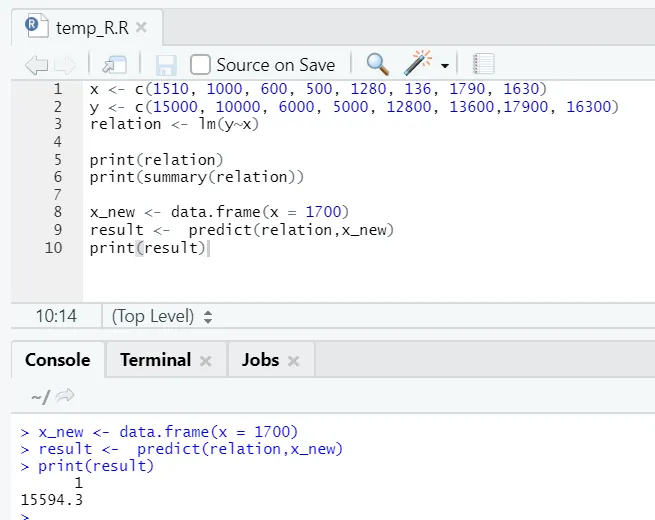
x <- c (1510, 1000, 600, 500, 1280, 136, 1790, 1630)
y <- c (15000, 10000, 6000, 5000, 12800, 13600, 17900, 16300)
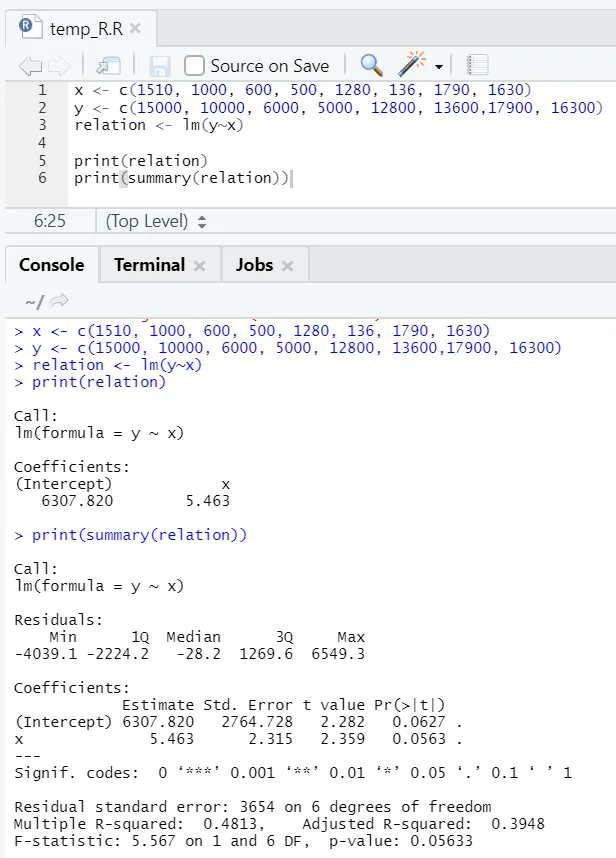
Tukaj P-vrednost ni manjša od 5%. Zato nične hipoteze ni mogoče zavrniti. Ni veliko pomena za dokazovanje razmerja med talno površino in najemnino.
Tukaj je vrednost R-kvadrata 0, 4813. To pomeni, da je le 48% razlike v izhodni spremenljivki mogoče razložiti z vhodno spremenljivko.
Recimo zdaj moramo predvideti vrednost talne površine na podlagi zgoraj nameščenega modela.
R koda
x_new <- data.frame(x = 1700)
result <- predict(relation, x_new)
print(result)
R izhod:
Po izvedbi zgornje kode R bo izhod videti naslednji:
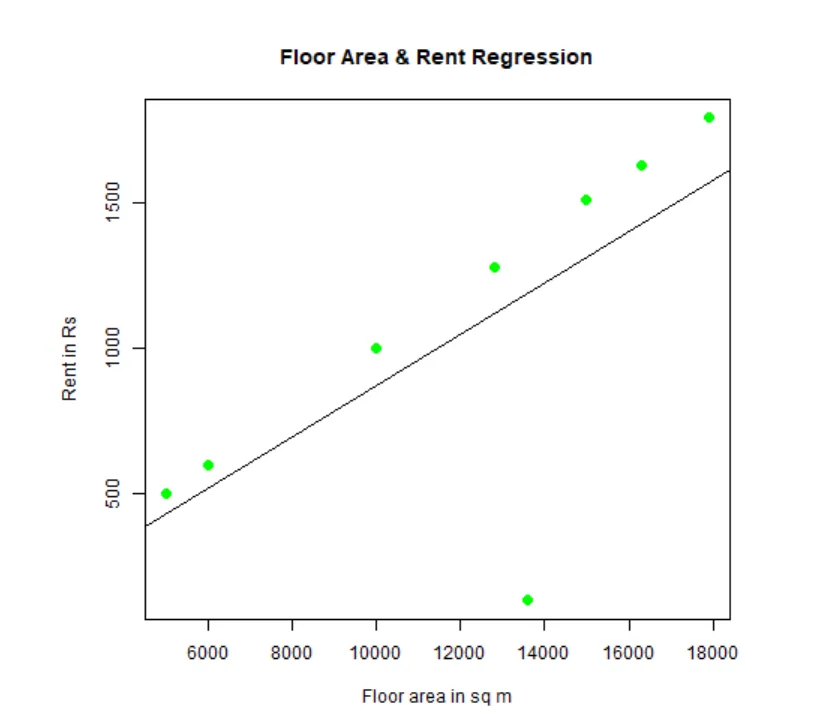
Posameznik lahko regresijo in prikaže. Tu je R koda:
# Ime datoteke png grafikona.
png(file = "LinearRegressionSample.png.webp")
# Narišite grafikon.
plot(y, x, col = "green", main = "Floor Area & Rent Regression",
abline(lm(x~y)), cex = 1.3, pch = 16, xlab = "Floor area in sq m", ylab = "Rent in Rs")
# Shranite datoteko.
dev.off()
Ta graf »LinearRegressionSample.png.webp« bo ustvarjen v vašem trenutnem delovnem imeniku.
g) test Chi-Square
To je statistična funkcija v R. Ta test ima svoj pomen, da bi dokazal, ali obstaja korelacija med dvema kategoričnimi spremenljivkami.
Tudi ta test deluje tako kot vsi drugi statistični testi, ki so temeljili na p-vrednosti, ničelno hipotezo je mogoče sprejeti ali zavrniti.
R sintaksa
chisq.test(data), /code>
Poglejmo en praktičen primer tega.
R koda
# Naložite knjižnico.
library(datasets)
data(iris)
# Ustvari podatkovni okvir iz glavnega nabora podatkov.
iris.data <- data.frame(iris$Sepal.Length, iris$Sepal.Width)
# Ustvari tabelo s potrebnimi spremenljivkami.
iris.data = table(iris$Sepal.Length, iris$Sepal.Width)
print(iris.data)
# Izvedite test Chi-Square.
print(chisq.test(iris.data))
R izhod:
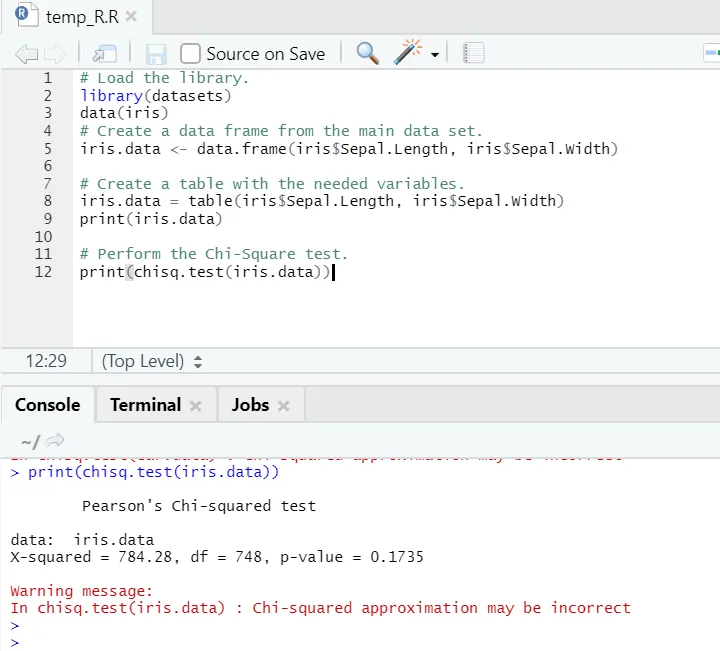
Kot je razvidno, je bil test chi-kvadrata izveden na naboru šarenice, upoštevajoč njegove dve spremenljivki „Sepal. Dolžina "in" Sepal.Width ".
Vrednost p ni manjša od 0, 05, zato korelacija med tema dvema spremenljivkama ne obstaja. Lahko pa rečemo, da ti dve spremenljivki nista odvisni drug od drugega.
Zaključek
Funkcije v R so preproste, enostavne za namestitev, enostavno razumevanje in hkrati zelo zmogljive. V R. smo videli številne funkcije, ki se kot del osnov uporabljajo v teh funkcijah. Ko se te funkcije ujemajo zgoraj, lahko raziskujemo druge vrste funkcij. Funkcije vam pomagajo, da kodo zaženete preprosto in jedrnato. Funkcije so lahko vgrajene ali uporabniško definirane, vse je odvisno od potrebe, ko se lotevate težave. Funkcije dajejo programu dobro obliko.
Priporočeni članki
To je priročnik za Funkcije v R., tukaj smo razpravljali o pisanju funkcij v R in različnih vrstah funkcij v R s skladnjo in primeri. Če želite izvedeti več, si oglejte tudi naslednji članek -
- R Nizke funkcije
- Funkcije nizov SQL
- Funkcije nizov T-SQL
- PostgreSQL String funkcije