
Uvod v Data Lake vs Data Warehouse
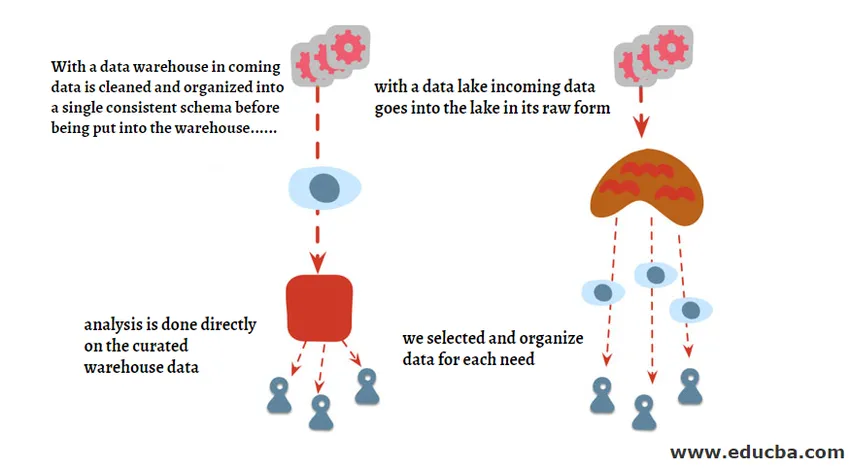
Data Lake vs Data Warehouse so izrazi, ki se medsebojno uporabljajo, vendar se med temi izrazi razlikujeta. Spodaj smo predstavili diagram, da bomo razumeli razliko na visoki ravni med tema dvema in zelo kmalu bomo podrobno opisali vsako od njih.
Kaj je podatkovno jezero?
Podatkovno jezero je neke vrste shramba, ki je sestavljena iz samo surovih podatkov, ki so v obliki strukturirane, polstrukturirane in nestrukturirane oblike. Podatkovno jezero večinoma uporabljajo podatki znanstveniki in inženirji strojnega učenja, saj jim pomagajo odgovoriti na vprašanja, na katera še niso odgovorili, ali morda ustvarijo vprašanje, ki še ni znano. Vsebuje veliko zbirko podatkov z različnimi vrstami in ko so integrirani, se izkažejo za zelo koristne v smislu napovednega modeliranja, ki se večinoma uporabljajo za izdelavo modelov strojnega učenja.
Kaj je shramba podatkov?
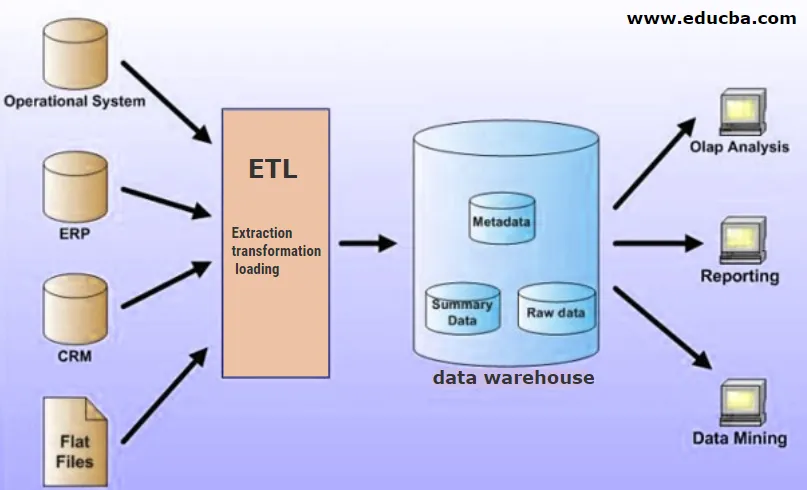
Skladišče podatkov je centralizirano mesto za shranjevanje transformiranih podatkov, ki so narejeni v strukturirani obliki, preden jih shranijo v podatkovno skladišče. Podatkovno skladišče lahko vsebuje podatke iz več virov, ki se s postopkom ETL naložijo v skladišče in nato uporabijo za namene poslovne inteligence.
Primerjava med podatki Data Lake in Data Warehouse (Infographics)
Spodaj je zgornjih 14 razlik med Data Lake in Data Warehouse 
Ključne razlike
Spodaj so podane glavne ključne razlike med podatkovnim skladiščem Data in Lake:
- Sestavljajo ga nestrukturirani in strukturirani podatki z različnih platform, kot so senzorji, aplikacije in spletna mesta itd. Večinoma so sestavljeni iz relacijskih podatkov iz RDBMS, sistemov DBMS ter drugih operativnih baz podatkov in aplikacij.
- Data Lake je obdelava, ki jo je mogoče prebrati po shemi. Shranjevanje podatkov je obdelava s shemo na zapis.
- Je zelo okretna. Je manj gibčen.
- Konfiguracija je enostavna in se lahko prilagodi spremembam. Ima fiksno konfiguracijo in jo je zelo težko spremeniti.
- Večinoma ga uporabljajo znanstveniki AI in strokovnjaki za strojno učenje. Uporabljajo ga poslovni strokovnjaki.
Primerjalna tabela med Data Lake in Data Warehouse:
Pogovorimo se o največji razliki med Data Lake in Data Warehouse
| Značilnosti | Data jezero | Podatkovno skladišče |
| Skladiščenje | Podatki se hranijo v surovi obliki v Data Lakeu in tukaj se vsi podatki hranijo ne glede na vir podatkov. Preoblikujejo se v druge oblike le, kadar je to potrebno. | Skladišče podatkov je sestavljeno iz podatkov, ki se pridobivajo iz transakcijskih in drugih sistemov meritev. Tu podatki niso v surovi obliki in so vedno preoblikovani in čisti. |
| Uporaba in namen | Glavni cilj Data Lake so znanstveniki podatkov, veliki razvijalci podatkov in inženirji strojnega učenja, ki morajo narediti poglobljeno analizo, da bi ustvarili modele za podjetja, kot je na primer napovedno modeliranje. | Glavni cilj skladišča podatkov so operativni uporabniki, saj so ti podatki strukturirani in lahko pripravijo poročila. Tako se večinoma uporabljajo za poslovno inteligenco. |
| Vnosi podatkov | Glavni vhodi v podatke Lake so vse vrste podatkov, kot so strukturirani, polstrukturirani in nestrukturirani podatki. Ti podatki v originalni obliki prebivajo v podatku Lake. | Glavni vhodi v podatkovno skladišče so strukturirani podatki, ki prihajajo iz transakcijskih in metričnih sistemov, ki so nato organizirani v obliki shem. |
| Kakovost podatkov | Vsebuje neobdelane podatke, ki jih je mogoče pripraviti ali ne. | Sestavljen je iz kuriranih podatkov, ki so centralizirani in so pripravljeni na tožbo zaradi poslovne inteligence in analitike. |
| Normalizacija | Tu podatki niso v normalizirani obliki. | Denormalizirane sheme |
| Zgodovina | Tehnologije, ki se uporabljajo v podatkovnih jezerih, kot sta Hadoop, Machine Learning, so v primerjavi s podatkovnim skladiščem razmeroma nove. | Tu je tehnologija, ki se uporablja za podatkovno skladišče, starejša. |
| Časovna premica podatkov | Podatkovno jezero ima vse vrste podatkov in jih je mogoče uporabiti, če upoštevamo preteklost, sedanjost in možnosti. | Kar zadeva skladišče podatkov, tukaj največ časa porabimo za analizo različnih virov podatkov. |
| Čas obdelave | Tu je čas obdelave, medtem ko analiziramo in dobimo rezultate iz podatkov Lake, precej manjši kot čas v skladišču podatkov, ker so tukaj podatki shranjeni v obliki neobdelanih podatkov in tisti, ki niso v preoblikovani obliki, zaradi česar smo skrajšali čas ki se lahko porabijo za preoblikovanje podatkov. Lahko le poberemo podatke takšne, kot so, in opravimo nekaj osnovnega čiščenja in začnemo graditi naše modele. | V primeru podatkovnega skladišča je čas, ki ga porabimo, v primerjavi s podatkovnim jezerom več. Razlog za to je, da je treba podatke v katerem koli podatkovnem skladišču najprej preoblikovati in nato analizirati. |
| Stroški skladiščenja | Stroški shranjevanja v tehnologijah podatkovnih jezer so sorazmerno nižji od stroškov skladišča podatkov in so tudi zamudni. | Stroški shranjevanja v tehnologijah za shranjevanje podatkov so v primerjavi s podatkovnim jezerom višji. To je zato, ker potrebuje več shranjenih podatkov za preoblikovane podatke, saj mora najprej shraniti surove podatke in jih nato preoblikovati za dodelitev različnih polj glede na strukturo skladišča podatkov. |
| Kompatibilnost | Tu se podatki vedno hranijo v surovi obliki in se transformirajo le, kadar je to potrebno ali ko so pripravljeni za uporabo. | Tu so podatki shranjeni v preoblikovani obliki, zato se lahko srečamo s težavami, ko poskušamo spremeniti kakršne koli spremembe. |
| Dostopnost | Podatki znotraj podatkovnega jezera so zelo dostopni in jih je mogoče hitro posodobiti. | Podatki v podatkovnem skladišču so bolj zapleteni in zahtevajo večje stroške, da se spremembe spremenijo, dostopnost je omejena tudi samo na pooblaščene uporabnike. |
| Položaj sheme | Shema je večinoma ustvarjena po shranjevanju podatkov. To prinaša visoko okretnost. | Tu je shema večinoma ustvarjena pred shranjevanjem podatkov. |
| Postopek obdelave | Podatkovno jezero uporablja postopek ELT, tj. Ekstrahiranje, nalaganje in preoblikovanje. | Skladišče podatkov uporablja tradicionalni pristop ETL, tj. Izvlečenje, preoblikovanje in nalaganje. |
| Prednosti | Podatkovno jezero vodi do novih izumov, saj integracija združuje različne vrste podatkov in prinaša odgovore na številna neodgovorjena vprašanja. | Večina organizacijskih uporabnikov je vključenih v operativne dejavnosti, skladišče podatkov pa ponuja eno tako briljantno platformo za ustvarjanje poročil in meritev na vrhu preoblikovanih podatkov. |
Zaključek
V tej objavi smo izvedeli o Data Lakes vs Data Warehouse. Tudi mi smo šli naprej in oba primerjali na podlagi različnih parametrov. To bi moralo pomagati vsem učencem, da dobijo osnovno predstavo o tehnologijah, ki podpirajo Data Lake in Data Warehouse.
Priporočeni članki
To je vodnik za največjo razliko med Data Lake in Data Warehouse. Tu smo razpravljali o ključnih razlikah Data Lake v primerjavi s skladiščem podatkov z infografiko in primerjalno tabelo. Za več informacij si lahko ogledate tudi naslednje članke -
- Scrum proti slapu - najboljše razlike
- MySQL vs MySQLi - Kateri je boljši?
- Mikroprocesor proti mikrokontrolerju
- Vprašanja o intervjuju za modeliranje podatkov