

Pregled arhitekture podatkovnega rudarjenja
Izvajanje podatkov je način iskanja in raziskovanja vzorcev osnovne ali napredne ravni v zapletenem naboru velikih podatkovnih nizov, ki vključuje metode, nameščene na presečišču statistik, strojnega učenja in tudi sistemov baz podatkov. Lahko bi rekli, da gre za interdisciplinarno področje statistike in računalniških ved, kjer je cilj pridobiti informacije z uporabo inteligentnih metod in tehnik iz določenega niza podatkov z ekstrakcijo in s tem preoblikovanje podatkov. Upoštevane so tudi dejavnosti upravljanja podatkov in dejavnosti predobdelave podatkov ter zaključki. V tem članku se bomo poglobili globoko v arhitekturo podatkovnega rudarjenja.
Arhitektura podatkovnega rudarjenja
Izkopavanje podatkov je tehnika pridobivanja zanimivega znanja iz nabora ogromnih količin podatkov, ki se nato shranijo v številne vire podatkov, kot so datotečni sistemi, skladišča podatkov, podatkovne baze. Primarne komponente arhitekture rudarjenja podatkov vključujejo -
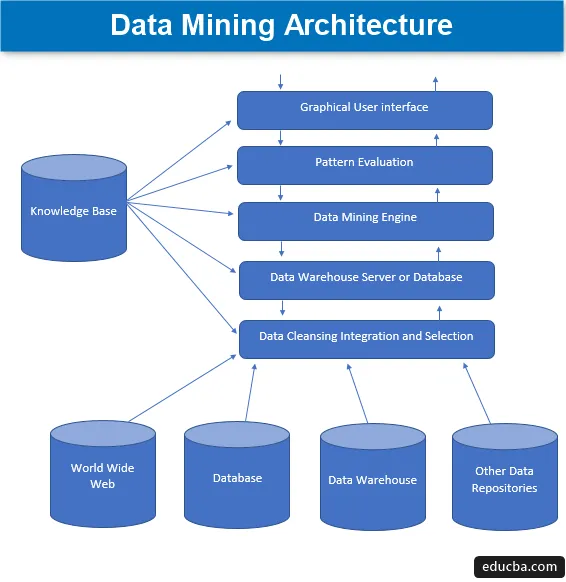
1. Viri podatkov
Ogromna raznolikost obstoječih dokumentov, kot so podatkovno skladišče, baza podatkov, www ali popularno imenovani splet po vsem svetu, ki postanejo dejanski viri podatkov. V večini primerov se lahko zgodi tudi, da podatki niso v nobenem od teh zlatih virov, ampak le v obliki besedilnih datotek, navadnih datotek ali zaporednih datotek ali preglednic, nato pa je treba podatke zelo obdelati podoben način, kot bi bila obdelava podatkov, prejetih iz zlatih virov. Danes je večina večine podatkov prejetih iz interneta ali svetovnega spleta, saj so vse, kar je danes na internetu, podatki v takšni ali drugačni obliki, ki tvorijo neko obliko podatkovnih enot.
Pred vnaprejšnjo obdelavo podatkov različni procesi, skozi katere gre, vključujejo čiščenje, integracijo in izbiro podatkov, preden se končno pošljejo v bazo podatkov ali na katerega koli strežnika EDW (poslovnega skladišča podatkov). Glavni izziv, ki se včasih pojavlja pri tem naboru podatkov, so različne ravni virov in širok razpon formatov podatkov, ki tvorijo komponente podatkov. Zato podatkov ni mogoče neposredno uporabiti za obdelavo v naivnem stanju, ampak jih obdelamo, preoblikujemo in oblikujemo na veliko bolj uporaben način. Tako sta zagotovljeni tudi zanesljivost in popolnost podatkov. Torej, prvi korak vključuje zbiranje, čiščenje in integracijo podatkov ter objaviti, da se posredujejo naprej samo ustrezni podatki. Vsa ta dejavnost je del ločenega nabora orodij in tehnik.
2. strežnik ali zbirka podatkov
Strežnik baz podatkov je dejanski prostor, v katerem so podatki vsebovani, ko jih prejmejo iz različnih številnih virov. Strežnik vsebuje dejanski nabor podatkov, ki so pripravljeni za obdelavo in zato strežnik upravlja z iskanjem podatkov. Vsa ta dejavnost temelji na zahtevi osebe za pridobivanje podatkov.
3. Data Mining Engine
V primeru rudarjenja podatkov motor predstavlja osnovno komponento in je najpomembnejši del oziroma, če rečem, gonilna sila, ki obravnava vse zahteve in jih upravlja in se uporablja, da vsebuje številne module. Število prisotnih modulov vključuje rudarske naloge, kot so klasifikacijska tehnika, asociacijska tehnika, regresijska tehnika, karakterizacija, napovedovanje in združevanje, analiza časovnih vrst, naivni Bayes, podporni vektorski stroji, ansambelske metode, tehnike povečevanja in vreče, naključni gozdovi, drevesa odločanja itd. itd.
4. Moduli za ocenjevanje vzorcev
Ta tehnika ocenjevanja modulov je v glavnem odgovorna za merjenje zanimivosti vseh tistih vzorcev, ki se uporabljajo za izračun osnovne ravni mejne vrednosti in se uporablja tudi za interakcijo z motorjem za rudarjenje podatkov za koordinacijo pri ocenjevanju drugih modulov. Glavni namen te komponente je iskati in iskati vse zanimive in uporabne vzorce, s katerimi bi lahko bili podatki sorazmerno boljši.
5. Grafični uporabniški vmesnik
Ko se podatki komunicirajo z motorji in med različnimi vzorčnimi ocenami modulov, postane nujna interakcija z različnimi prisotnimi komponentami in bolj uporabniku prijazna, tako da je mogoče učinkovito in učinkovito uporabljati vse prisotne komponente in zato nastane potreba po grafičnem uporabniškem vmesniku, ki je splošno znan kot GUI.
To se uporablja za vzpostavljanje občutka za stik med uporabnikom in sistemom za pridobivanje podatkov, s čimer se uporabnikom pomaga, da dostopajo do sistema in ga učinkovito in enostavno uporabljajo, da ne ostanejo zapleteni v procesu. To je oblika abstrakcije, pri kateri so uporabnikom prikazane samo ustrezne komponente in so vse kompleksnosti in funkcionalnosti, odgovorne za gradnjo sistema, zaradi preprostosti skrite. Kadar koli uporabnik poda poizvedbo, potem modul poseže v celoten niz sistema rudarjenja podatkov, da ustvari ustrezen izhod, ki bi ga lahko uporabniku enostavno prikazali na veliko bolj razumljiv način.
6. Baza znanja
To je komponenta, ki je osnova celotnega procesa pridobivanja podatkov, saj pomaga pri usmerjanju iskanja ali ocenjevanju zanimivosti oblikovanih vzorcev. Ta baza znanja je sestavljena iz prepričanj uporabnikov in tudi podatkov, pridobljenih iz uporabniških izkušenj, ki so v pomoč pri postopku pridobivanja podatkov. Motor lahko dobi nabor vhodov iz ustvarjene baze znanja in s tem zagotavlja bolj učinkovite, natančne in zanesljive rezultate.
Rudarjenje podatkov je ena najpomembnejših tehnik danes, ki se ukvarja z upravljanjem in obdelavo podatkov, kar je hrbtenica katere koli organizacije. Analiza podatkov v kateri koli organizaciji bo prinesla koristne rezultate. Vsak sestavni del tehnike in arhitekture podatkovnega rudarjenja ima svoj način opravljanja odgovornosti in tudi učinkovito dokončanje podatkovnega rudarjenja. Za pravilno medsebojno delovanje so potrebni različni moduli, da dobimo dragocen rezultat in uspešno zaključimo zapleten postopek rudarjenja podatkov z zagotavljanjem pravega nabora informacij podjetju.
Priporočeni članki
To je vodnik za arhitekturo podatkovnega rudarjenja. Tukaj razpravljamo o glavnih sestavnih delih arhitekture podatkovnega rudarjenja. Če želite izvedeti več, lahko preberete tudi druge naše predlagane članke -
- Orodje za rudarjenje podatkov
- Prednosti Data Mining
- Kaj je združevanje v podatkovno rudarjenje?
- Vprašanja in odgovori za intervju z HTML5
- Najpogosteje uporabljene tehnike ansambelskega učenja
- Algoritmi modelov v podatkovnem rudarstvu