

Uvod v Pridružitev zemljevidu v panju
Pridruževanje zemljevidu je funkcija, ki se uporablja v poizvedbah Hive za povečanje njene učinkovitosti glede hitrosti. Pridružitev je pogoj, ki se uporablja za združevanje podatkov iz dveh tabel. Ko opravimo normalno združevanje, se opravilo pošlje nalogi Map-Reduce, ki razdeli glavno nalogo na dve stopnji - "Stopnja zemljevida" in "Zmanjšanje stopnje". Stopnja Map razlaga vhodne podatke in vrne izhod na stopnjo zmanjšanja v obliki parov ključ-vrednost. Naslednji korak gre skozi fazo mešanja, kjer jih razvrstimo in kombiniramo. Reduktor prevzame to razvrščeno vrednost in dokonča opravilo združevanja.
Tabelo lahko v pomnilnik vstavite v celoti v zemljevid in brez uporabe zemljevida / reduktorja. Podatke prebere iz manjše tabele in jih shrani v razpršilno tabelo v pomnilniku, nato pa jih serializira v pomnilniško datoteko hash in tako znatno zmanjša čas. Znan je tudi pod imenom Map Side Join in Hive. V bistvu vključuje izvedbo združevanja med dvema tabelama z uporabo samo faze Zemljevid in preskoka faze zmanjšanja. Če se redno uporabljajo majhne pridružene tabele, je mogoče opaziti časovno zmanjšanje izračuna poizvedb.
Sintaksa za pristop k zemljevidu v panj
Če želimo izvesti pridružitveno poizvedbo s pomočjo pridruživanja zemljevidu, moramo v spodnjem stavku določiti ključno besedo "/ * + MAPJOIN (b) * /":
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
Za ta primer moramo ustvariti 2 tabeli z imeni tablename1 in tablename2, ki imata dva stolpca: emp_id in emp_name. Ena bi morala biti večja datoteka in ena manjša.
Pred zagonom poizvedbe moramo spodaj navedeno lastnost nastaviti na true:
hive.auto.convert.join=true
Poizvedba o pridružitvi zemljevidu je napisana kot zgoraj, rezultat pa dobimo:
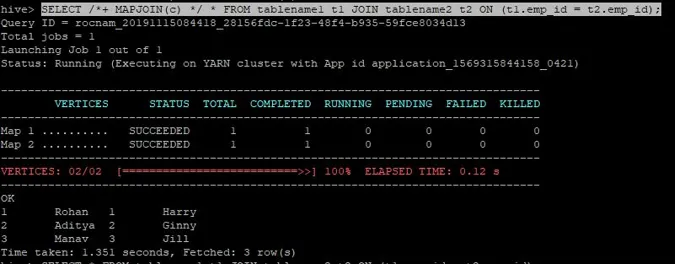
Poizvedba se je zaključila v 1.351 sekundah.
Primeri pridruževanja zemljevidu v panju
Spodaj so navedeni naslednji primeri
1. Primer pridruževanja zemljevidov
Za ta primer ustvarimo 2 tabeli z imenom table1 in table2 s 100 in 200 zapisi. Spodnji ukaz in posnetke zaslona lahko uporabite za izvajanje istega:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

Zdaj naložimo zapise v obe tabeli s pomočjo spodnjih ukazov:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
Izvedemo običajno poizvedbo o pridruževanju zemljevidu na njihovih ID-jih, kot je prikazano spodaj, in preverimo čas, potreben za isto:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
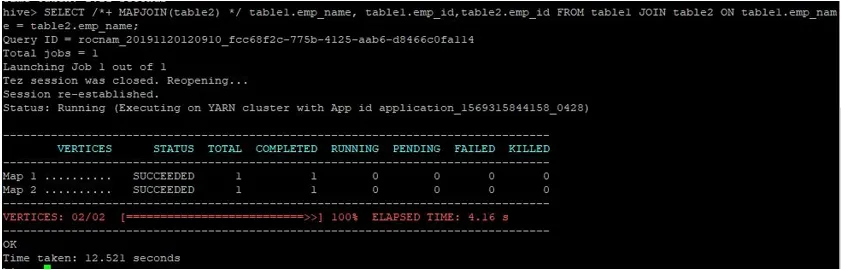
Kot lahko vidimo, je običajna poizvedba za združevanje zemljevidov trajala 12.521 sekund.
2. Primer združevanja z vedrovnimi kartami
Zdaj uporabimo za združevanje z Bucket-mapjem. Obstaja nekaj omejitev, ki jih je treba upoštevati pri žlice:
- Žlice lahko združite med seboj samo, če je skupno vedro katere koli ene tabele večkratno od števila vedra v drugi tabeli.
- Za izvajanje vedrov morajo imeti napolnjene mize. Zato ustvarimo isto.
Sledita ukaza, ki se uporabljata za ustvarjanje zaporednih tabel table1 in table2:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

V te izrezane tabele vstavimo iste zapise iz tabele1:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
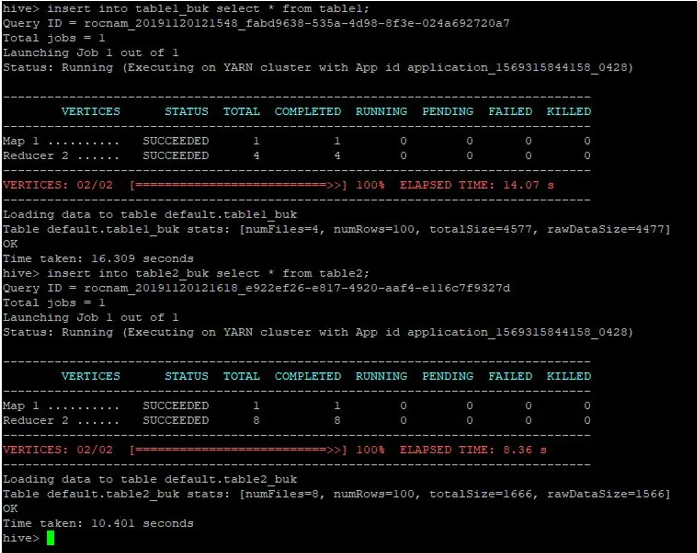
Zdaj, ko imamo dve tabeli z vrečami, opravimo povezavo z zemljevidom vedra. Prva tabela ima 4 vedra, medtem ko druga tabela vsebuje 8 vedra v istem stolpcu.
Da bi poizvedba o pridruževanju zemljevida za delovanje delovala, bi morali v panju nastaviti spodnjo lastnost, da je resnična:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
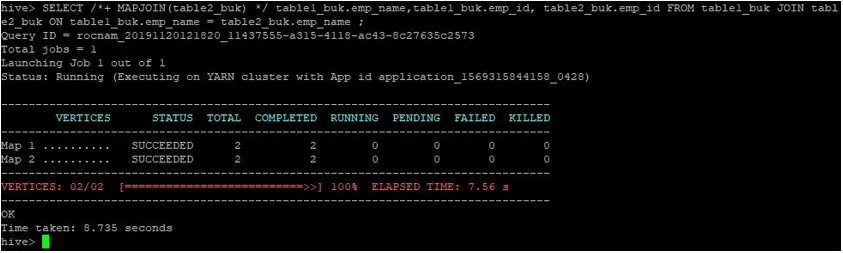
Kot lahko vidimo, smo poizvedbo zaključili v 8.735 sekundah, kar je hitrejše od običajnega združevanja zemljevidov.
3. Razvrstite primer pridruževanja zemljevida združitve vedra (SMB)
SMB se lahko izvede na bucket tabelah z enakim številom veder in če je treba tabele razvrstiti in zapečati na pridruženih stolpcih. Temu vedru se ustrezno pridruži tudi Mapperjev nivo.
Enako kot pri združevanju z vedri na zemljevidu sta tudi 4 vedra za mizo1 in 8 vedra za mizo2. Za ta primer bomo ustvarili drugo tabelo s 4 vedri.
Za izvedbo SMB poizvedbe moramo nastaviti naslednje lastnosti panja, kot je prikazano spodaj:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = res;
hive.optimize.bucketmapjoin.sortedmerge = res;
Za izvedbo združitve v SMB je treba podatke razvrstiti po stolpcih za združevanje. Podatke v zapisu tabele1 prepišimo tako, kot je spodaj:
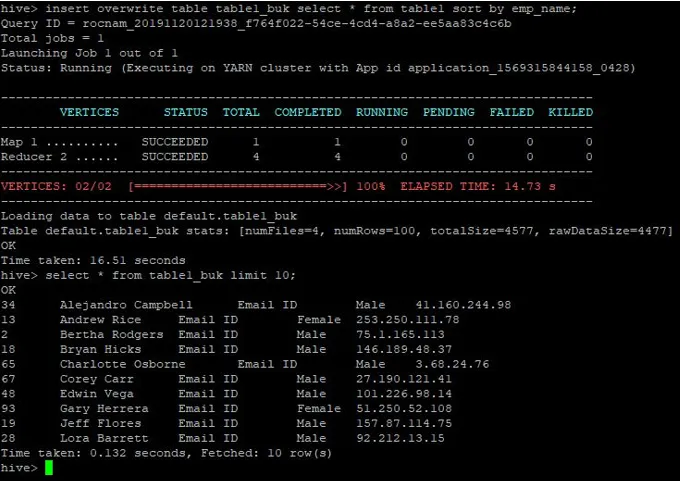
>insert overwrite table table1_buk select * from table1 sort by emp_name;
Podatki so zdaj razvrščeni, kar lahko vidite na spodnjem posnetku zaslona:
Podatke v zapisano tabelo2 bomo prepisali tudi spodaj:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Pridružimo se zgornji dve tabeli na naslednji način:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
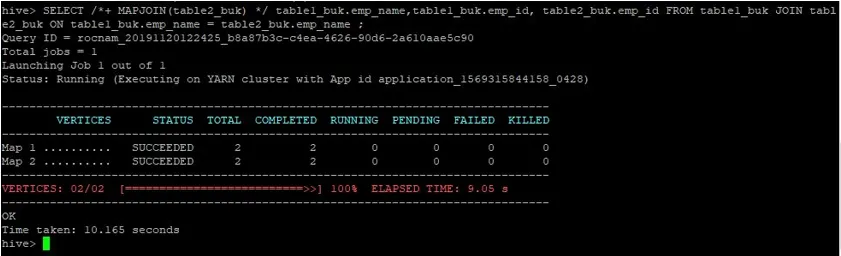
Vidimo, da je poizvedba trajala 10.165 sekund, kar je spet boljše od običajnega pridruževanja zemljevidu.
Ustvarimo še eno tabelo za table2 s 4 vedri in enakimi podatki, razvrščenimi z imenom em_name.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
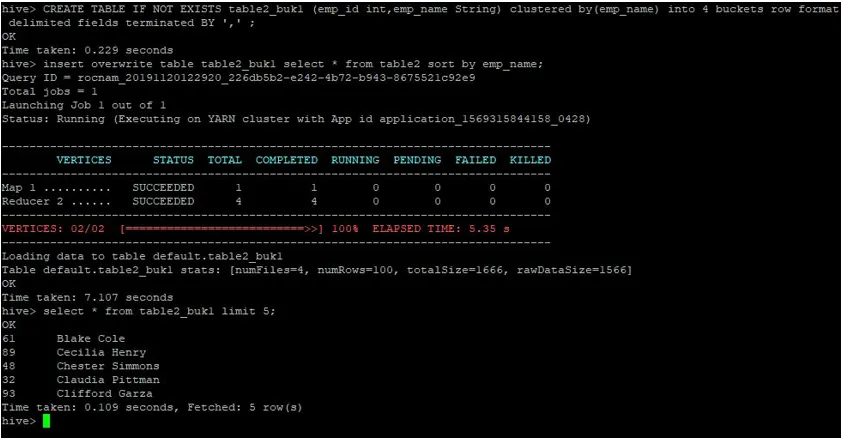
Glede na to, da imamo zdaj obe tabeli s 4 vedri, ponovno izvedemo poizvedbo o pridruževanju.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
Poizvedba je spet trajala 8.851 sekund hitreje kot običajna poizvedba o pridruževanju zemljevidu.
Prednosti
- Združevanje zemljevidov zmanjša čas, potreben za postopke razvrščanja in združevanja, ki potekajo v premestitvi, in zmanjša stopnje, s čimer zmanjšate tudi stroške.
- Povečuje uspešnost naloge.
Omejitve
- Ista tabela / vzdevek ni dovoljena za povezavo različnih stolpcev v isti poizvedbi.
- Poizvedba po združitvi zemljevida ne more pretvoriti celotnih zunanjih povezav v stranske povezave strani.
- Združevanje zemljevidov je mogoče izvesti le, če je ena od tabel dovolj majhna, da se lahko prilega spominu. Zato je ni mogoče izvesti tam, kjer je podatkov tabele ogromno.
- Levo združevanje je mogoče narediti za združitev zemljevida le, če je desna velikost tabele majhna.
- Desno združevanje je mogoče narediti za združitev zemljevida le, če je velikost leve tabele majhna.
Zaključek
Poskusili smo vključiti najboljše možne točke Map Join v Hive. Kot smo videli zgoraj, združitev na strani zemljevida deluje najbolje, če ima ena tabela manj podatkov, tako da se opravilo hitro zaključi. Čas, potreben za tukaj prikazane poizvedbe, je odvisen od velikosti nabora podatkov, zato je tukaj prikazan čas samo za analizo. Združevanje zemljevidov je enostavno izvajati v aplikacijah v realnem času, saj imamo ogromno podatkov in tako zmanjšamo mrežni I / O promet.
Priporočeni članki
To je vodnik za Map Join in Hive. Tukaj razpravljamo o primerih Map Join in Hive skupaj s prednostmi in omejitvami. Če želite izvedeti več, si oglejte tudi naslednji članek -
- Pridružuje se v Pive
- Vgrajene funkcije panja
- Kaj je panj?
- Ukazi panj