
Uvod v krepitev učenja
Okrepitveno učenje je vrsta strojnega učenja in je zato tudi del Umetne inteligence, kadar se uporabljajo za sisteme, sistemi izvajajo korake in se učijo na podlagi izida korakov, da dosežejo zapleten cilj, ki ga sistem želi doseči.
Razumevanje učenja ojačanja
Poskusimo s pomočjo dveh preprostih primerov uporabe:
Primer 1
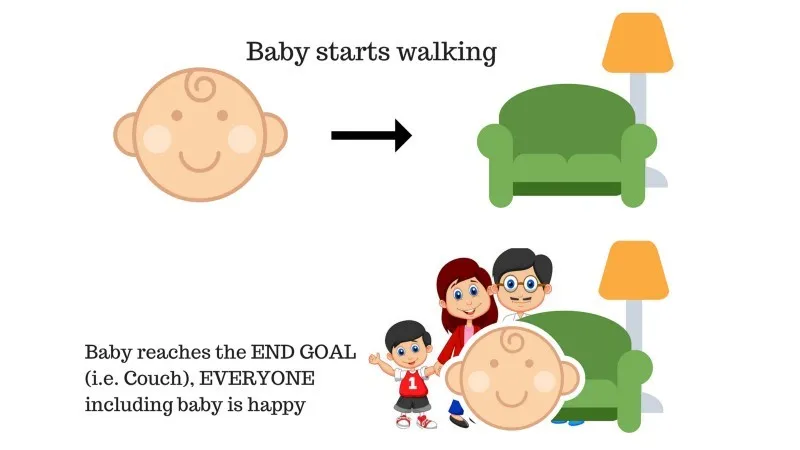
V družini je dojenček in pravkar je začela hoditi in vsi so zelo zadovoljni. Starši si nekega dne poskušamo postaviti cilj, dovolimo, da dojenček pride do kavča in preverimo, ali je dojenček to sposoben.
Rezultat primera 1: Dojenček uspešno doseže setto in zato so vsi v družini zelo veseli, da to vidijo. Izbrana pot zdaj prinaša pozitivno nagrado.
Točke: Nagrada + (+ n) → Pozitivna nagrada.
Vir: https://images.app.goo.gl/pGCXJ1N1bzLAer126
Primer št. 2
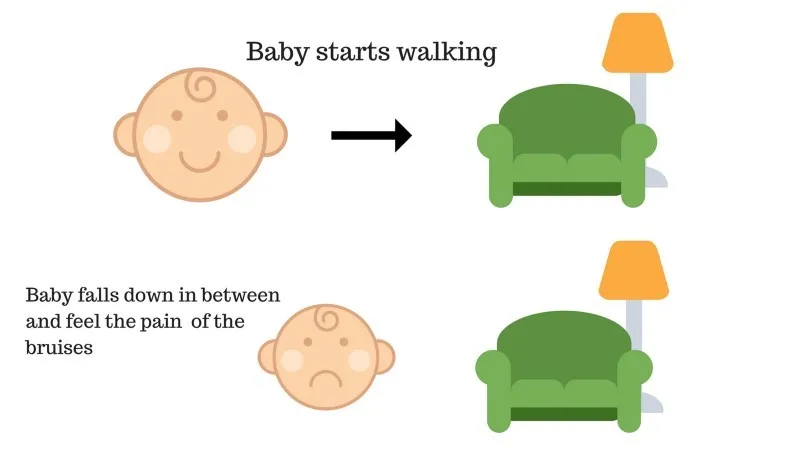
Dojenček ni mogel priti do kavča in dojenček je padel. Boli! Kaj bi lahko bil razlog? Na poti do kavča so lahko nekatere ovire in dojenček je padel na ovire.
Rezultat primera 2: Dojenček pade na nekaj ovir in joka! Oh, hudo je bilo, se je naučila, da ne bo naslednjič padla v past ovire. Izbrana pot zdaj prihaja z negativno nagrado.
Točke: Nagrade + (-n) → Negativna nagrada.
Vir: https://images.app.goo.gl/FRfd8cUqrQRLe6sZ7
Zdaj smo videli primera 1 in 2, krepitev učenja v konceptu deluje enako, razen da ni človeško, ampak se izvaja računalniško.
Uporaba okrepitve po korakih
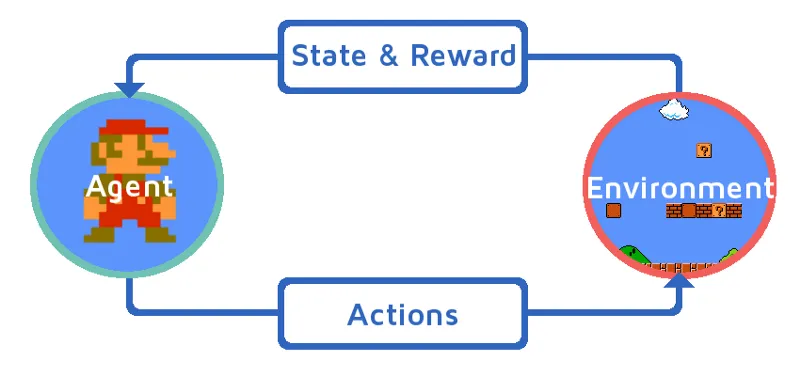
Dovolite nam, da se učimo ojačitve, tako da postopno uvedemo okrepitveno sredstvo. V tem primeru je naš učilni agent okrepitve Mario, ki se bo sam naučil igrati:
Vir: https://images.app.goo.gl/Kj44uvBzWzMw1QzE9
- Trenutno stanje v igralnem okolju Mario je S_0. Ker se igra še ni začela in je Mario na svojem mestu.
- Nato se igra začne in Mario se premakne, Mario tj. RL agent sprejme in ukrepa, recimo A_0.
- Zdaj je stanje v igralnem okolju postalo S_1.
- Tudi agent RL, tj. Mario, je zdaj dodeljen s pozitivno nagrado, R_1, verjetno zato, ker je Mario še vedno živ in ni bilo nevarnosti.
Zdaj bo zgornja zanka še naprej delovala, dokler Mario ne bo končno mrtev ali Mario ne doseže cilja. Ta model nenehno oddaja dejanje, nagrado in stanje.
Nagrade za maksimiranje
Cilj okrepljenega učenja je maksimirati nagrade z upoštevanjem nekaterih drugih dejavnikov, kot je popust na nagrade; v kratkem bomo razložili, kaj pomeni popust s pomočjo ilustracije.
Kumulativna formula za diskontirane nagrade je:
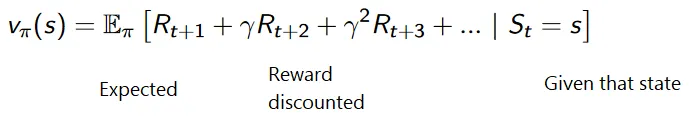
Nagrade s popustom
Naj to razumemo na primeru:
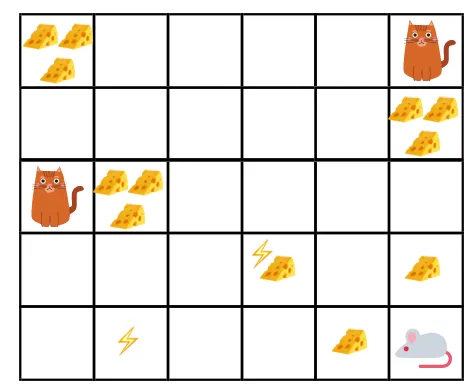
- Na sliki je cilj, da mora miš v igri pojesti toliko sira, preden jo mačka poje ali ne da bi bila elektrošokirana.
- Zdaj lahko domnevamo, da čim bližje smo mački ali električni pasti, večja je verjetnost, da miško pojemo ali šokiramo.
- To pomeni, da če imamo polno sira v bližini električnega udara ali v bližini mačke, bolj tvegano je, če gremo tja, je bolje jesti sir, ki je v bližini, da se izognemo kakršnemu koli tveganju.
- Čeprav imamo en sir "block1", ki je poln in je daleč od mačke in električnega udara, in drugi "block2", ki je poln, vendar je blizu mačke ali bloka električnega udara, kasnejši blok sira, tj. "block2", bo bolj ugodno znižan kot prejšnji.
Vir: https://images.app.goo.gl/8QrH78FjmRVs5Wxk8
Vir: https://cdn-images-1.medium.com/max/800/1*l8wl4hZvZAiLU56hT9vLlg.png.webp
Vrste okrepitvenega učenja
Spodaj sta opisani dve vrsti učbenega pouka s svojimi prednostmi in slabostmi:
1. Pozitiven
Ko se moč in pogostost vedenja povečata zaradi pojava nekega določenega vedenja, je to znano kot pozitivno okrepitveno učenje.
Prednosti: Zmogljivost je maksimirana in sprememba ostane dlje časa.
Slabosti: Rezultate lahko zmanjšamo, če imamo preveč okrepitve.
2. negativno
Gre za krepitev vedenja, predvsem zaradi negativnega izraza.
Prednosti: vedenje je povečano.
Slabosti: Le minimalno vedenje modela je mogoče doseči s pomočjo negativnega učvrstitvenega učenja.
Kje naj se uporablja okrepitveno učenje?
Stvari, ki jih je mogoče storiti z okrepljenim učenjem / primeri. Sledijo področja, kjer se danes uporablja okrepljeno učenje:
- Skrb za zdravje
- Izobraževanje
- Igre
- Računalniški vid
- Upravljanje podjetja
- Robotika
- Finance
- NLP (obdelava naravnega jezika)
- Prevoz
- Energija
Poklicne dejavnosti pri okrepljenem učenju
Resnično obstaja poročilo s spletnega mesta o delovnih mestih, saj je RL veja strojnega učenja, po poročilu pa je strojno učenje najboljše delo leta 2019. Spodaj je povzetek poročila. Glede na trenutne trende inženirji strojnega učenja prihajajo s povprečno plačo v višini 146.085 dolarjev in s 344-odstotno stopnjo rasti.
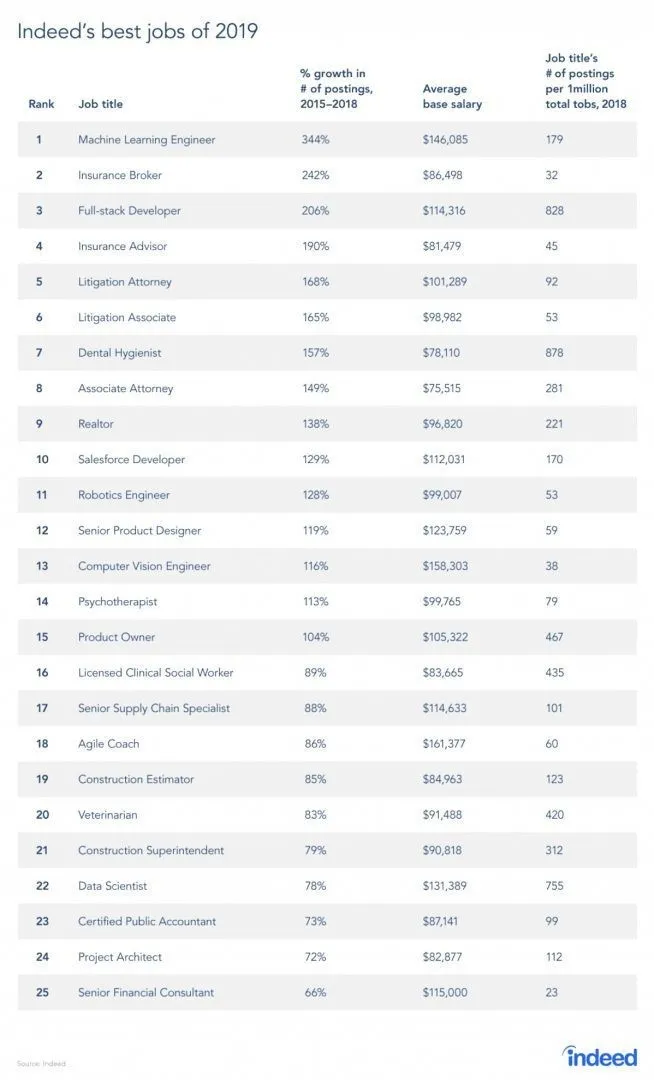
Vir: https://i0.wp.com/www.artificialintelligence-news.com/wp-content/uploads/2019/03/indeed-top-jobs-2019-best.jpg.webp?w=654&ssl=1
Spretnosti za krepitev učenja
Spodaj so spretnosti, potrebne za okrepitev učenja:
1. Osnovne spretnosti
- Verjetnost
- Statistika
- Podatkovno modeliranje
2. Spretnosti programiranja
- Osnove programiranja in računalništva
- Oblikovanje programske opreme
- Sposobnost uporabe knjižnic in algoritmov strojnega učenja
3. Strojni programski jeziki
- Python
- R
- Čeprav obstajajo tudi drugi jeziki, kjer se lahko oblikujejo modeli strojnega učenja, kot so Java, C / C ++, vendar sta Python in R najbolj priljubljena jezika.
Zaključek
V tem članku smo začeli s kratkim uvodom o okrepljenem učenju, nato pa smo se globoko poglobili v delovanje RL in različnih dejavnikov, ki sodelujejo pri delu modelov RL. Nato smo dali nekaj primerov iz resničnega sveta, da bi še bolje razumeli temo. Na koncu tega članka bi morali dobro razumeti delovanje okrepljenega učenja.
Priporočeni članki
To je vodnik o tem, kaj je okrepljeno učenje ?. Tukaj s primeri obravnavamo funkcijo in različne dejavnike, ki sodelujejo pri razvijanju modelov učilnega učenja. Obiščite lahko tudi druge naše sorodne članke, če želite izvedeti več -
- Vrste algoritmov strojnega učenja
- Uvod v umetno inteligenco
- Orodja za umetno inteligenco
- Platforma IoT
- Top 6 jezikov za strojno učenje