

Uvod v RDBMS Intervju Vprašanja in odgovori
Če se torej pripravljate na razgovor za službo v RDBMS. Prepričan sem, da želite vedeti najpogostejša vprašanja o intervjuju za RDBMS za leto 2019 in odgovore, ki vam bodo pomagali z lahkoto razbiti RDBMS intervju. Spodaj je seznam najboljših vprašanj in odgovorov o RDBMS, ki so vam na voljo.
Zato ponavadi dodamo najbolj priljubljena vprašanja o RDBMS za leto 2019, ki jih zastavljamo večinoma v intervjuju
1.Kaj so različne funkcije RDBMS?
Odgovor:
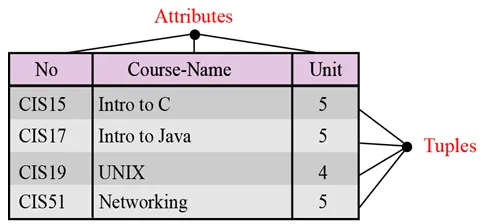
Ime. Vsak odnos v relacijski podatkovni bazi mora imeti ime, ki je edinstveno med vsemi drugimi odnosi.
Lastnosti. Vsak stolpec v relaciji se imenuje atribut.
Tuple. Vsaka in vsaka vrstica v odnosu se imenuje tuple. Tuple definirajo zbirko vrednosti atributa.
2. Pojasnite model ER?
Odgovor:
Model ER je model entiteta-odnos. Model ER temelji na resničnem svetu, ki ga sestavljajo subjekti in objekti odnosov. Entitete so v bazi podatkov prikazane z nizom atributov.
3.Definiran objektno orientiran model?
Odgovor:
Objektno orientiran model temelji na zbirkah predmetov. Predmet vsebuje vrednosti, ki so shranjene v primerkih spremenljivk znotraj predmeta. Predmeti z enakim tipom vrednosti in popolnoma enakimi metodami so združeni v razrede.
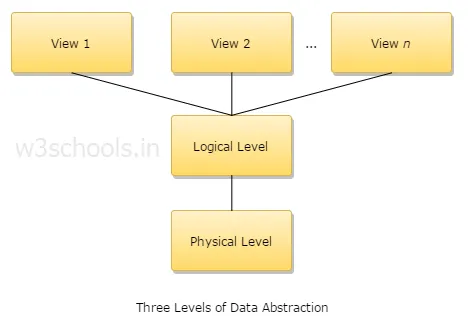
4. Pojasnite tri stopnje odvzema podatkov?
Odgovor:
1. Fizična raven: To je najnižja stopnja abstrakcije in opisuje, kako se podatki hranijo.
2. Logična raven: Naslednja raven abstrakcije je logična, opisuje, kakšne vrste podatkov so shranjene v bazi podatkov in kakšen je odnos med temi podatki.
3. Raven pogleda: najvišja stopnja abstrakcije in opisuje edino celotno bazo podatkov.
 https://www.w3schools.in/dbms/data-schemas/
https://www.w3schools.in/dbms/data-schemas/
5.Kakšna so različna Coddova 12 pravila za relacijske baze podatkov?
Odgovor:
Codd's 12 pravil je niz trinajstih pravil (oštevilčenih od nič do dvanajst), ki jih je predlagal Edgar F. Codd.
Coddova pravila: -
Pravilo 0: Sistem se lahko šteje za relacijski, kot bazo podatkov in tudi kot sistem upravljanja.
Pravilo 1: Pravilo o informacijah: Vsak podatek v bazi podatkov mora biti predstavljen enotno, v glavnem vrednosti imen v položajih stolpcev v drugi vrstici tabele.
2. pravilo: Pravilo zajamčenega dostopa: Vsi podatki morajo biti vpadljivi. Pravi, da mora biti vsaka skalarna vrednost v bazi podatkov pravilno / logično naslovljiva.
3. pravilo: Sistematična obdelava ničelnih vrednosti: DBMS mora dovoliti, da ostane vsak nič.
Pravilo 4: Aktivni spletni katalog (struktura baze podatkov), ki temelji na relacijskem modelu: Sistem mora podpirati spletno, relacijsko itd strukturo, ki je z običajnimi poizvedbami nedovoljena do dovoljenih uporabnikov.
5. pravilo: Obsežno podjezik podatkov: Sistem mora pomagati vsaj enemu relacijskemu jeziku, ki:
1. Ima linearno skladnjo
2. ki se lahko uporablja tako v interakciji kot znotraj aplikativnih programov,
3. Podpira operacije definiranja podatkov (DDL), operacije manipulacije podatkov (DML), omejitve varnosti in integritete ter operacije upravljanja transakcij (začetek, prevzem in vrnitev).
Pravilo 6: Pravilo za posodabljanje pogleda : Sistem mora nadgraditi vsa stališča, ki se teoretično izboljšajo.
7. pravilo: Vstavljanje, posodabljanje in brisanje na visoki ravni: Sistem mora podpirati operaterje za vstavljanje, posodobitev in brisanje.
8. pravilo: Neodvisnost fizičnih podatkov: Če želite spremeniti fizično raven (način shranjevanja podatkov z uporabo nizov ali povezanih seznamov itd.) Ne sme zahtevati spremembe aplikacije.
Pravilo 9: Neodvisnost logičnih podatkov: Če spremenite logično raven (tabele, stolpci, vrstice itd.), Aplikacija ne sme spremeniti.
Pravilo 10: Neodvisnost integritete: Omejitve integritete je treba določiti posamično iz aplikativnih programov in jih shraniti v katalogu.
11. pravilo: Neodvisnost distribucije: Razdelitev delov baze podatkov na različne lokacije ne sme biti vidna uporabnikom baze podatkov.
12. pravilo: Pravilo, ki ne uporablja subverzije : Če sistem ponuja vmesnik nizke ravni (tj . Zapisov ), tega vmesnika ni mogoče uporabiti za podrejanje sistema.
6.Kaj je normalizacija? in kaj pojasnjuje različne oblike normalizacije.
Odgovor:
Normalizacija baz podatkov je postopek organiziranja podatkov za zmanjšanje odvečnosti podatkov. Kar posledično zagotavlja doslednost podatkov. Obstaja veliko težav, povezanih z odvečnostjo podatkov, kot so zapravljanje prostora na disku, neskladnost podatkov, poizvedbe DML (Data Manipulation Language) postanejo počasne. Obstajajo različne normalizacijske oblike: - 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, ONF, DKNF.
1. 1NF: - Podatki v vsakem stolpcu morajo biti večkratne vrednosti atomske številke, ločene z vejico. Tabela ne vsebuje nobenih ponavljajočih se skupin stolpcev. Vsak zapis enolično uporabite s primarnim ključem.
2. 2NF: - Tabela mora ustrezati vsem pogojem 1NF in presežne podatke premakniti v ločeno tabelo. Poleg tega ustvari odnos med temi tabelami s pomočjo tujih ključev.
3. 3NF: - za tabelo 3NF bi morali izpolnjevati vse pogoje 1NF in 2NF. 3NF ne vsebuje atributov, ki so delno odvisni od primarnega ključa.
7.Definirajte primarni ključ, tuji ključ, kandidatni ključ, super ključ?
Odgovor:
Primarni ključ: primarni ključ je ključ, ki ne dovoljuje podvojenih vrednosti in ničelnih vrednosti. Primarni ključ lahko določite na ravni stolpcev ali tabele. Dovoljen je samo en primarni ključ na tabeli.
Tuji ključ: tuji ključ dovoljuje vrednosti, ki so prisotne samo v referenčnem stolpcu. Omogoča podvojene ali nične vrednosti. Opredelimo jo lahko kot raven stolpcev ali tabelo. Lahko se sklicuje na stolpec edinstvenega / primarnega ključa.
Kandidatski ključ: Kandidatski ključ je minimalni super ključ, ni ustrezne podskupine atributov Ključni kandidat lahko super ključ.
Super tipka: Superkey je niz atributov relativne sheme, od katerih so delno odvisni vsi atributi sheme. Nobeni dve vrstici ne moreta imeti enake vrednosti atributov super ključev.
8.Kaj je drugačna vrsta indeksov?
Odgovor:
Indeksi so: -
Indeks v gruči: - To je indeks, s katerim se podatki fizično shranijo na disk. Zato je mogoče v tabelo podatkovnih baz ustvariti samo en združeni indeks.
Indeks, ki ni v gručah: - Ne definira fizičnih podatkov, ampak definira logični vrstni red. Običajno so v ta namen ustvarjena B-drevo ali B + drevo.
9.Kaj so prednosti RDBMS?
Odgovor:
• Nadzor nad odpuščanjem.
• Integriteta se lahko uveljavi.
• Neprimernosti se je mogoče izogniti.
• Podatki se lahko delijo.
• Standard se lahko uveljavi.
10.Imete nekatere podsisteme RDBMS?
Odgovor:
Vhod-izhod, Varnost, Jezikovna obdelava, Upravljanje pomnilnika, Zapisovanje in obnavljanje, Nadzor distribucije, Nadzor transakcij, Upravljanje spomina.
11.Kaj je upravitelj vmesnikov?
Odgovor:
Buffer Manager uspe zbrati podatke iz diskovnega pomnilnika v glavni pomnilnik in določiti, katere podatke naj bo v predpomnilniku za hitrejšo obdelavo.
Priporočeni članek
To je vodnik za seznam vprašanj in odgovorov o intervjujih za RDBMS, tako da lahko kandidat brez težav razreši ta vprašanja za razgovor z RDBMS. Če želite izvedeti več, si oglejte tudi naslednje članke -
- Najpomembnejša vprašanja o intervjuju glede podatkov
- 13 neverjetna vprašanja in odgovori za intervju z bazo podatkov
- Najboljših 10 vprašanj in odgovorov za oblikovanje vzorcev
- 5 uporabnih vprašanj in odgovorov o SSIS