
Uvod v življenjski cikel podatkov
Življenjski cikel podatkov se vrti okoli uporabe strojnega učenja in drugih analitičnih metod za pripravo vpogledov in napovedi iz podatkov za dosego poslovnega cilja. Celoten postopek vključuje več korakov, kot so čiščenje podatkov, priprava, modeliranje, ocenjevanje modelov itd. Proces je dolg in lahko traja nekaj mesecev. Zato je zelo pomembno, da imamo za vsako težavo splošno strukturo. Globalno priznana struktura pri reševanju kakršnega koli analitičnega problema se imenuje medsektorski standardni postopek za pridobivanje podatkov ali okvir CRISP-DM.
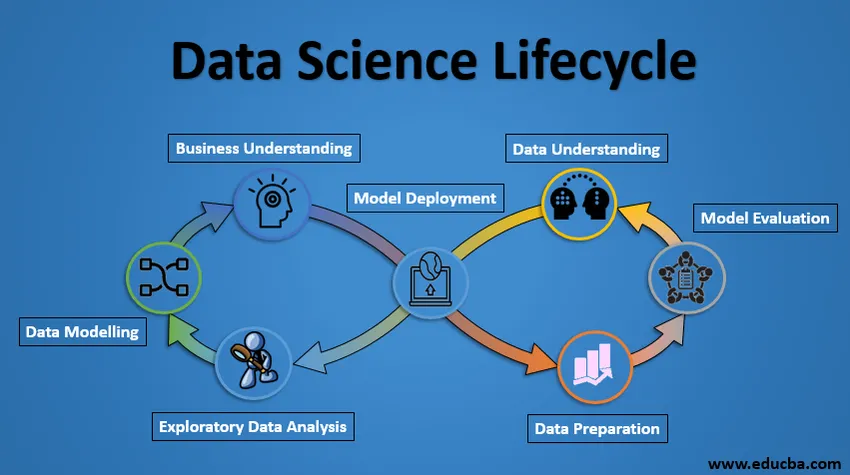
Življenjski cikel znanosti o podatkih
Spodaj je projekt Life Science of Data Science.
1. Poslovno razumevanje
Celoten cikel se vrti okoli poslovnega cilja. Kaj boste rešili, če nimate natančne težave? Izjemno pomembno je jasno razumeti poslovni cilj, ker bo to vaš končni cilj analize. Samo ob pravilnem razumevanju lahko postavimo poseben cilj analize, ki je usklajen s poslovnim ciljem. Vedeti morate, ali želi stranka zmanjšati kreditno izgubo ali če želi napovedati ceno blaga itd.
2. Razumevanje podatkov
Po poslovnem razumevanju je naslednji korak razumevanje podatkov. To vključuje zbiranje vseh razpoložljivih podatkov. Tukaj morate tesno sodelovati s poslovno ekipo, saj se dejansko zavedajo, kateri podatki so prisotni, katere podatke bi lahko uporabili za to poslovno težavo in druge informacije. Ta korak vključuje opis podatkov, njihovo strukturo, ustreznost, vrsto podatkov. Raziščite podatke s pomočjo grafičnih grafov. V bistvu črpanje vseh informacij, ki jih lahko dobite o podatkih, s samo raziskovanjem podatkov.
3. Priprava podatkov
Sledi faza priprave podatkov. To vključuje korake, kot je izbira ustreznih podatkov, integracija podatkov z združevanjem naborov podatkov, čiščenje, obdelava manjkajočih vrednosti tako, da jih odstranite ali jih vpišete, obdelavo napačnih podatkov z njihovo odstranitvijo, tudi preverite, ali ostajajo osebe s črtami polja in jih obdelite. . Z gradnjo novih podatkov pridobite nove funkcije iz obstoječih. Formatirajte podatke v želeno strukturo, odstranite neželene stolpce in funkcije. Priprava podatkov je najbolj zamuden, vendar zagotovo najpomembnejši korak v celotnem življenjskem ciklu. Vaš model bo tako dober kot vaši podatki.
4. Raziskovalna analiza podatkov
Ta korak vključuje pridobitev neke predstave o rešitvi in dejavnikih, ki nanjo vplivajo, preden zgradite dejanski model. Porazdelitev podatkov znotraj različnih spremenljivk funkcije se raziskuje grafično z uporabo črtnih grafov, odnosi med različnimi značilnostmi pa se ujamejo z grafičnimi predstavitvami, kot so raztresene ploskve in toplotni zemljevidi. Mnoge druge tehnike vizualizacije podatkov se široko uporabljajo za raziskovanje vsake funkcije posebej in tako, da jih kombiniramo z drugimi funkcijami.
5. Modeliranje podatkov
Modeliranje podatkov je osnova analize podatkov. Model vzame pripravljene podatke kot vhod in zagotovi želeni izhod. Ta korak vključuje izbiro ustrezne vrste modela, ne glede na to, ali je težava težava s klasifikacijo ali regresijska težava ali problem grozda. Po izbiri družine modelov moramo med različnimi algoritmi med to družino skrbno izbrati algoritme za njihovo izvajanje in izvajanje. Za dosego želenih lastnosti moramo prilagoditi hiperparametre vsakega modela. Prav tako moramo zagotoviti pravilno ravnovesje med uspešnostjo in splošnostjo. Ne želimo, da se model nauči podatkov in slabo deluje na novih podatkih.
6. Vrednotenje modela
Tu je ovrednoten model, da preveri, ali je pripravljen za uporabo. Model je preizkušen na nevidnih podatkih, ovrednoten je na skrbno premišljenem naboru meritev ocenjevanja. Poskrbeti moramo tudi za to, da bo model skladen z resničnostjo. Če pri ocenjevanju ne dobimo zadovoljivega rezultata, moramo ponoviti celoten postopek modeliranja, dokler ne dosežemo želene ravni meritev. Vsaka podatkovna rešitev, model strojnega učenja, tako kot človeški, naj se razvija, bi se morala izboljšati z novimi podatki, prilagoditi se novi ocenjevalni metriki. Za določen pojav lahko sestavimo več modelov, vendar je veliko njih morda nepopolnih. Ocenjevanje modela nam pomaga izbrati in sestaviti popoln model.
7. Razmestitev modela
Model po natančni oceni je končno razporejen v želeni obliki in kanalu. To je zadnji korak v življenjskem ciklu podatkovne znanosti. Vsak korak v zgoraj opisanem življenjskem ciklu podatkovne znanosti je treba skrbno delati. Če se kateri koli korak izvede neustrezno, bo posledično vplival na naslednji korak in celoten napor bo odpadel. Na primer, če podatki niso zbrani pravilno, boste izgubili informacije in ne boste zgradili popolnega modela. Če podatki niso očiščeni pravilno, model ne bo deloval. Če modela ne ocenimo pravilno, v realnem svetu ne bo uspel. Od poslovnega razumevanja do uvajanja modela, je treba vsakemu koraku nameniti ustrezno pozornost, čas in trud.
Priporočeni članki
To je vodnik za Podatkovni življenjski cikel. Tukaj obravnavamo pregled življenjskega cikla Data Science in korake, ki sestavljajo življenjski cikel podatkovne znanosti. Obiščite lahko tudi naše povezane članke, če želite izvedeti več -
- Uvod v algoritme znanosti o podatkih
- Data Science vs Programsko inženiring | Top 8 uporabnih primerjav
- Vrste razlik tehnik znanstvenih podatkov
- Znanosti podatkov s tipi