

Razlika med pridobivanjem podatkov in strojnim učenjem
Izvajanje podatkov se nanaša na pridobivanje znanja iz velike količine podatkov. Izvajanje podatkov je postopek odkrivanja različnih vrst vzorcev, ki so podedovani v podatkih in ki so natančni, novi in uporabni. Rudarjenje podatkov je podvrsta poslovne analitike, podobno je eksperimentalnim raziskavam. Izvor podatkovnega rudarjenja so baze podatkov, statistika. Strojno učenje vključuje algoritem, ki se samodejno izboljša z izkušnjami na podlagi podatkov. Strojno učenje je način odkrivanja novega algoritma iz izkušenj. Strojno učenje vključuje preučevanje algoritmov, ki lahko samodejno pridobivajo informacije. Strojno učenje uporablja tehnike rudarjenja podatkov in drug algoritem učenja za oblikovanje modelov, kaj se dogaja za nekaterimi podatki, tako da lahko napoveduje prihodnje rezultate.
Naj v tej objavi podrobneje razumemo rudarjenje podatkov in strojno učenje.
Primerjava med nami med podatkovnim rudarjenjem in strojnim učenjem (Infographics)
Spodaj je 10 najboljših primerjav med podatkovnim rudarjenjem in strojnim učenjem
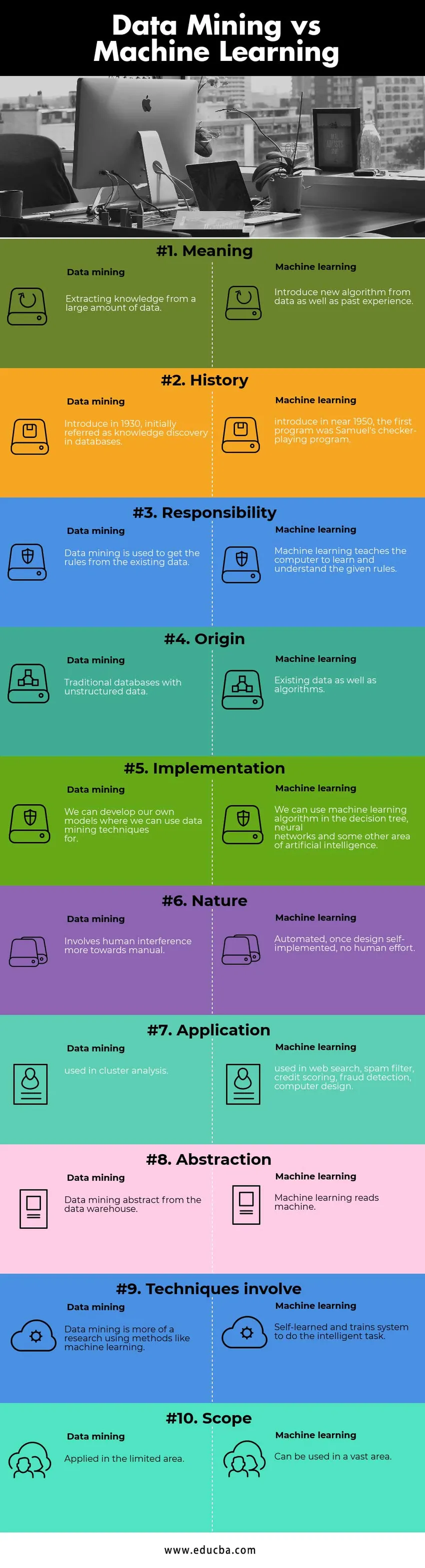 Ključna razlika med pridobivanjem podatkov in strojnim učenjem
Ključna razlika med pridobivanjem podatkov in strojnim učenjem
- Za izvajanje tehnik rudarjenja podatkov je bila uporabljena dvokomponentna, prva je baza podatkov, druga pa strojno učenje. Baza podatkov ponuja tehnike upravljanja podatkov, medtem ko strojno učenje ponuja tehnike analize podatkov. Toda za izvajanje tehnik strojnega učenja je uporabil algoritme.
- Podatkovno rudarjenje uporablja več podatkov za pridobivanje koristnih informacij in ti določeni podatki bodo pomagali napovedati nekatere prihodnje rezultate, na primer v prodajnem podjetju, ki ga lanski podatki uporabljajo za napovedovanje te prodaje, vendar se strojno učenje ne bo zanašalo veliko na podatke, ki jih uporabljajo algoritmi, na primer, OLA, UBER tehnike strojnega učenja za izračun ETA za vožnje.
- Zmogljivost samostojnega učenja ni prisotna pri pridobivanju podatkov, temveč sledi pravilom in vnaprej določeno. Ponujal bo rešitev za določen problem, vendar so algoritmi strojnega učenja samo definirani in lahko spremenijo svoja pravila glede na scenarij, našel bo rešitev za določen problem in ga rešil po svoje.
- Glavna in najpomembnejša razlika med pridobivanjem podatkov in strojnim učenjem je, da brez sodelovanja človeških podatkov ne more delovati, pri strojnem učenju pa človeški napor vključuje le čas, ko je algoritem opredeljen, potem bo vse zaključil z lastnimi sredstvi, ko bo izveden večno za uporabo, vendar to ni slučaj pri iskanju podatkov.
- Rezultat, ki ga dobimo s strojnim učenjem, bo v primerjavi z rudarjenjem podatkov natančnejši, saj je strojno učenje avtomatiziran proces.
- Za pridobivanje koristnih podatkov uporablja strežnik zbirke podatkov ali podatkovnega skladišča, mehanizem za rudarjenje podatkov in tehnike ocenjevanja vzorcev, medtem ko strojno učenje za sprejemanje odločitev uporablja nevronske mreže, napovedni model in avtomatizirane algoritme.
Primerjava podatkov v primerjavi s tabelo strojnega učenja
| osnovna za primerjavo | Izkopavanje podatkov | Strojno učenje |
| Pomen | Pridobivanje znanja iz velike količine podatkov | Uvedite nov algoritem iz podatkov in preteklih izkušenj |
| Zgodovina | Uveden leta 1930, sprva omenjen kot odkritje znanja v bazah podatkov | prvi program je bil Samuel-ov program igranja naključkov |
| Odgovornost | Izvajanje podatkov se uporablja za pridobivanje pravil iz obstoječih podatkov. | Strojno učenje uči računalnik, da se nauči in razume dana pravila. |
| Poreklo | Tradicionalne baze podatkov z nestrukturiranimi podatki | Obstoječi podatki in algoritmi. |
| Izvajanje | Lahko razvijemo lastne modele, v katerih lahko uporabimo tehnike rudarjenja podatkov | Algoritem strojnega učenja lahko uporabimo v drevesu odločitev, nevronskih omrežjih in nekaterih drugih področjih umetne inteligence. |
| Narava | Vključuje človeško vmešavanje bolj v smeri ročnega. | Avtomatizirano, nekoč samo-oblikovano, brez človeškega napora |
| Uporaba | uporablja se v grozdni analizi | uporablja se pri spletnem iskanju, nezaželenem filtru, kreditnem ocenjevanju, odkrivanju prevar, računalniškem oblikovanju |
| Abstrakcija | Povzetek podatkovnega rudarjenja iz podatkovnega skladišča | Strojno učenje bere stroj |
| Tehnike vključujejo | Rudarjenje podatkov je bolj raziskava z uporabo metod, kot je strojno učenje | Samostojno se nauči in usposablja sistem za inteligentno nalogo. |
| Obseg | Uporablja se na omejenem območju | Lahko se uporablja na velikem območju. |
Zaključek - Izvajanje podatkov v primerjavi s strojnim učenjem
V večini primerov se zdaj pridobivanje podatkov uporablja za napovedovanje rezultata iz preteklih podatkov ali iskanje nove rešitve iz obstoječih podatkov. Večina organizacij uporablja to tehniko za doseganje poslovnih rezultatov. Kjer tehnike strojnega učenja rastejo veliko hitreje, saj premaga težave s tehnikami rudarjenja podatkov. Ker je postopek strojnega učenja bolj natančen in manj nagnjen k napakam v primerjavi z iskanjem podatkov in je veliko bolj sposoben sam sprejeti svojo odločitev in rešiti težavo. Da pa podjetje še vedno poganja, moramo imeti postopek pridobivanja podatkov, ker bo opredelil težavo določenega podjetja in za rešitev te težave lahko uporabimo tehnike strojnega učenja. Z eno besedo lahko rečemo, da je za vodenje podjetja tako tehnik rudanja podatkov kot tudi strojno učenje potrebno delati z roko v roki, ena tehnika bo opredelila težavo, druga pa vam bo dala rešitev na veliko natančen način.
Priporočeni članek
To je vodnik za pridobivanje podatkov in strojno učenje, njihov pomen, primerjava med seboj, ključne razlike, primerjalna tabela in sklep. Če želite izvedeti več, si oglejte tudi naslednje članke -
- 8 Pomembne tehnike pridobivanja podatkov za uspešno poslovanje
- 7 pomembnih tehnik pridobivanja podatkov za najboljše rezultate
- 5 najboljših razlik med strojnimi učenjemi z velikimi podatki
- 5 Najbolj uporabna razlika med podatkovnim znanjem in strojnim učenjem