
Uvod v ansambelske tehnike
Ansambelno učenje je tehnika strojnega učenja, ki pomaga s pomočjo več osnovnih modelov in združi njihove rezultate, da ustvari optimiziran model. Ta vrsta algoritma strojnega učenja pomaga pri izboljšanju splošne učinkovitosti modela. Tu je osnovni model, ki se najpogosteje uporablja, klasifikator drevesa odločitve. Drevo odločitev v bistvu deluje na več pravilih in zagotavlja napovedni izhod, kjer so pravila vozlišča in bodo njihove odločitve njihovi otroci, listna vozlišča pa bodo končna odločitev. Kot je prikazano v primeru odločitvenega drevesa.
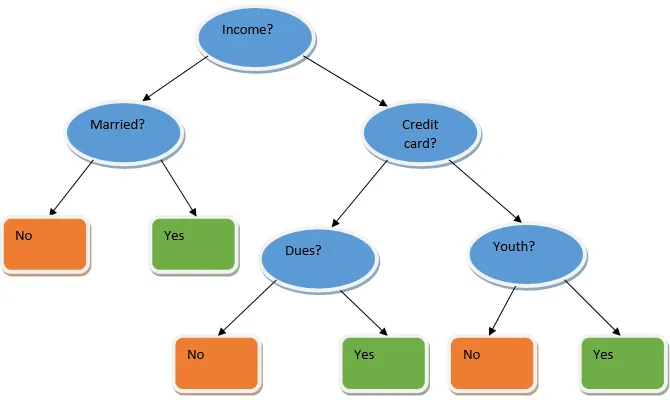
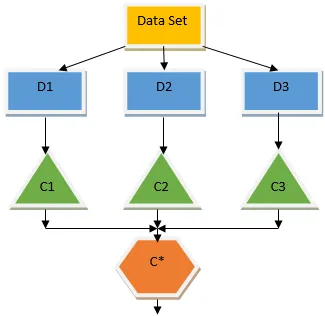
Zgornje drevo odločitev v bistvu govori o tem, ali lahko oseba / stranka dobi posojilo ali ne. Eno od pravil za upravičenost do posojila je, da če (dohodek = Da && Poročeni = Ne) Posojilo = Da, tako deluje klasifikator drevesa odločitve. Te klasifikatorje bomo vključili kot več osnovni model in združili njihovo proizvodnjo, da bomo zgradili en optimalen napovedni model. Slika 1.b prikazuje celotno sliko algoritma za učenje ansambla.
Vrste tehnik ansamblov
Različne vrste ansamblov, naš glavni poudarek pa bo na spodnjih dveh vrstah:
- Vrečka
- Povečanje
Te metode pomagajo zmanjšati odstopanje in pristranskost v modelu strojnega učenja. Zdaj pa poskusimo razumeti, kaj je pristranskost in odstopanje. Pristranskost je napaka, ki se pojavi zaradi napačnih predpostavk v našem algoritmu; visoka pristranskost kaže, da je naš model preveč preprost / premalo. Variacija je napaka, ki je posledica občutljivosti modela na zelo majhna nihanja v naboru podatkov; velika odstopanje pomeni, da je naš model zelo zapleten / preobsežen. Idealen model ML mora imeti ustrezno ravnovesje med pristranskostjo in odstopanjem.
Agregiranje / zapiranje zagonske kopice
Vrečka je tehnika ansambla, ki pomaga zmanjšati odstopanje v našem modelu in se tako izogne pretiranemu opremljanju. Vrekanje je primer algoritma vzporednega učenja. Torbe delujejo po dveh principih.
- Zagon zagona: Iz prvotnega nabora podatkov se z nadomestnimi štejejo različne vzorčne populacije.
- Združevanje: povprečenje rezultatov vseh klasifikatorjev in zagotavljanje enotnega izida za to uporablja večino glasov v primeru razvrščanja in povprečenja v primeru regresijske težave. Eden izmed znanih algoritmov strojnega učenja, ki uporablja koncept razvadovanja odpadkov, je naključni gozd.
Naključni gozd
V naključnem gozdu iz naključnega vzorca, umaknjenega iz populacije z nadomestitvijo in podmnožica lastnosti, je izbrana iz nabora vseh funkcij, ki je zgrajeno drevo odločitve. Iz teh podskupin funkcij, ki od vsake funkcije daje najboljši razcep, je izbran kot koren za odločitveno drevo. Podmnožico funkcij je treba izbrati naključno za vsako ceno, sicer bomo ustvarili le korelirane trese in variacija modela se ne bo izboljšala.
Zdaj smo zgradili naš model na vzorcih, odvzetih iz populacije, vprašanje pa je, kako potrjujemo model? Ker razmišljamo o vzorcih z nadomestnimi, torej vsi vzorci ne bodo upoštevani, nekateri pa ne bodo vključeni v nobeno vrečko, se ti izvzamejo iz vzorcev vrečk. Naš model lahko potrdimo s temi vzorci OOB (izven vreče). Pomembni parametri, ki jih je treba upoštevati v naključnem gozdu, so število vzorcev in število dreves. Upoštevajmo 'm' kot podmnožico funkcij, 'p' pa je celoten nabor funkcij, zdaj kot pravilo za palec je vedno idealno izbrati
- m as√ in najmanjša velikost vozlišča kot 1 za težavo s klasifikacijo.
- m kot P / 3 in najmanjša velikost vozlišča, ki naj bo 5 za regresijsko težavo.
Ko se ukvarjamo s praktičnim problemom, je treba m in p obravnavati kot nastavitve parametrov. Izobraževanje se lahko prekine, ko se napaka OOB stabilizira. Ena pomanjkljivost naključnega gozda je, da če imamo v svojem podatkovnem nizu 100 funkcij in je pomembnih le nekaj funkcij, potem bo ta algoritem deloval slabo.
Povečanje
Spodbujanje je zaporedni algoritem učenja, ki pomaga zmanjšati pristranskost našega modela in odstopanje v nekaterih primerih nadzorovanega učenja. Pomaga tudi pri pretvorbi šibkih učencev v močne učence. Pospeševanje deluje na principu zaporednega razporejanja šibkih učencev in vsaki tečaj dodeli utež za vsako podatkovno točko; večja teža je dodeljena napačno razvrščeni podatkovni točki v prejšnjem krogu. Ta zaporedna utežena metoda treninga našega podatkovnega niza je ključna razlika do metode pakiranja.
Fig3.a prikazuje splošni pristop pri spodbujanju
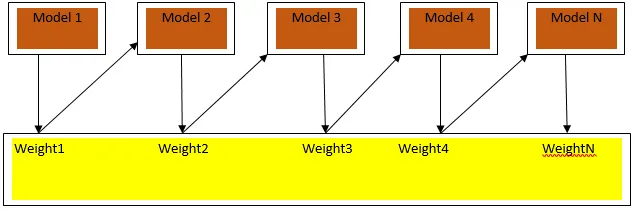
Končne napovedi so združene na podlagi glasovanja s tehtano večino v primeru razvrstitve in tehtane vsote v primeru regresije. Najpogosteje uporabljeni algoritem za povečanje je prilagodljivo povečanje (Adaboost).
Prilagodljivo povečanje
Korak za algoritem Adaboost je naslednji:
- Za dane n podatkovne točke določimo ciljni razred in inicializiramo vse uteži na 1 / n.
- Klasifikatorje prilagodimo naboru podatkov in izberemo klasifikacijo z najmanj tehtano napako klasifikacije
- Uteži klasifikatorja dodelimo s pravilom palca na podlagi natančnosti, če je natančnost več kot 50%, je teža pozitivna in obratno.
- Posodobimo uteži klasifikatorjev na koncu iteracije; posodobimo večjo težo za napačno razvrščeno točko, tako da jo v naslednji ponovitvi pravilno razvrstimo.
- Po vseh iteracijah dobimo končni rezultat napovedi na podlagi večinskega glasovnega / tehtanega povprečja.
Adaboosting učinkovito deluje s šibkimi (manj zapletenimi) učenci in z visokimi klasifikatorji pristranskosti. Najpomembnejše prednosti Adaboostinga so, da je hitro, ni parametrov uglaševanja, podobnih primeru pakiranja, in ne dajemo nobenih predpostavk za šibke učence. Ta tehnika ne zagotavlja natančnega rezultata, kdaj
- V naših podatkih je več odpuščenih oseb.
- Nabor podatkov ni dovolj.
- Šibki učenci so zelo zapleteni.
Občutljivi so tudi na hrup. Odločitvena drevesa, ki nastanejo zaradi spodbude, bodo imela omejeno globino in visoko natančnost.
Zaključek
Ansambelske tehnike učenja se pogosto uporabljajo pri izboljšanju natančnosti modela; na podlagi našega nabora podatkov se moramo odločiti, katero tehniko bomo uporabili. Toda te tehnike niso prednostne v nekaterih primerih, ko je interpretacija pomembna, saj izgubljamo interpretacijo s ceno izboljšanja učinkovitosti. Ti imajo izjemen pomen v zdravstveni industriji, kjer je majhno izboljšanje učinkovitosti zelo dragoceno.
Priporočeni članki
To je vodnik za Ansambelske tehnike. Tukaj razpravljamo o uvodu in dveh glavnih vrstah tehnik ansambla. Obiščite lahko tudi druge naše sorodne članke, če želite izvedeti več -
- Tehnike steganografije
- Tehnike strojnega učenja
- Tehnike team buildinga
- Algoritmi znanosti o podatkih
- Najpogosteje uporabljene tehnike ansambelskega učenja