
Opredelitev algoritma povprečnega premika
Algoritem srednjega premika spada pod nenadzorovano učenje, ki je kategorizirano kot algoritem gruče. Ideologija algoritma Srednji premik je, da iterativno dodeli podatkovne točke grozdišču, tako da se premakne na točko, ki ima točko najvišje gostote (Način). Povprečna logika premika temelji na konceptu ocene gostote jedra, imenovanem KDE.
Srednje grozdanje algoritma premika
Nenadzorovana tehnika učenja, ki sta jo odkrila Fukunaga in Hostetler za iskanje skupin:
- Srednji premik je znan tudi kot algoritem iskanja načina, ki podatkovnim točkam dodeljuje grozde tako, da podatkovne točke premakne v območje z visoko gostoto. Največja gostota podatkovnih točk se v regiji imenuje kot model. Algoritem Mean Shift ima aplikacije, ki se pogosto uporabljajo na področju računalniškega vida in segmentacije slike.
- KDE je metoda za oceno porazdelitve podatkovnih točk. Deluje tako, da na vsako podatkovno točko postavi jedro. Jedro v matematičnem izrazu je funkcija uteži, ki bo uporabila uteži za posamezne podatkovne točke. Če dodate vse posamezno jedro, ustvarja verjetnost.
Funkcija jedra mora izpolnjevati naslednje pogoje:
- Prva zahteva je zagotoviti, da se ocena gostote jedra normalizira.
- Druga zahteva je, da je KDE dobro povezan s simetrijo prostora.
Dve priljubljeni funkciji jedra
Spodaj sta uporabljeni dve priljubljeni funkciji jedra:
- Ravno jedro
- Gaussovo jedro
- Na podlagi uporabljene paramele Kernel se funkcija nastale gostote razlikuje. Če ni omenjen noben parameter jedra, se privzeto prikliče Gaussovo jedro. KDE uporablja koncept funkcije gostote verjetnosti, ki pomaga najti lokalne maksime porazdelitve podatkov. Algoritem deluje tako, da podatkovne točke pritegnejo drug drugega in tako omogočijo podatkovnim točkam območje z visoko gostoto.
- Podatkovne točke, ki se poskušajo zbližati z lokalnimi maksimi, bodo iste skupine grozdov. V nasprotju z algoritmom združevanja K-Means izhod algoritma Srednji premik ni odvisen od predpostavk o obliki podatkovne točke in številu gruč. Število grozdov bo določeno z algoritmom glede na podatke.
- Za izvedbo algoritma Srednji premik uporabimo Python paket SKlearn.
Izvedba algoritma Srednji premik
Spodaj je izvedba algoritma:
Primer # 1
Na podlagi Sklearn Tutorial za algoritem povprečnega premika grozda. Prvi delček bo implementiral algoritem srednjega premika za iskanje skupin dvodimenzionalnega nabora podatkov. Paketi, uporabljeni za izvajanje algoritma srednjega premika.
Koda:
fromcluster importMeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs as mb
importpyplot as plt
fromitertools import cycle as cy
Pomembno je omeniti, da bomo s pomočjo sklearnove knjižnice make_blobs uporabili knjižnico sklearnov za generiranje podatkovnih točk s tremi lokacijami. Za uporabo algoritma Srednjega premika za ustvarjene točke moramo nastaviti pasovno širino, ki predstavlja interakcijo med dolžino. Sklearnova knjižnica ima vgrajene funkcije za oceno pasovne širine.
Koda:
#Sample data points
cen = ((1, .75), (-.75, -1), (1, -1)) x_train, _ = mb(n_samples=10000, centers= cen, cluster_std=0.6)
# Bandwidth estimation using in-built function
est_bandwidth = estimate_bandwidth(x_train, quantile=.1,
n_samples=500)
mean_shift = MeanShift(bandwidth= est_bandwidth, bin_seeding=True)
fit(x_train)
ms_labels = mean_shift.labels_
c_centers = ms_labels.cluster_centers_
n_clusters_ = ms_labels.max()+1
# Plot result
figure(1)
clf()
colors = cy('bgrcmykbgrcmykbgrcmykbgrcmyk')
fori, each inzip(range(n_clusters_), colors):
my_members = labels == i
cluster_center = c_centers(k) plot(x_train(my_members, 0), x_train(my_members, 1), each + '.')
plot(cluster_center(0), cluster_center(1),
'o', markerfacecolor=each,
markeredgecolor='k', markersize=14)
title('Estimated cluster numbers: %d'% n_clusters_)
show()
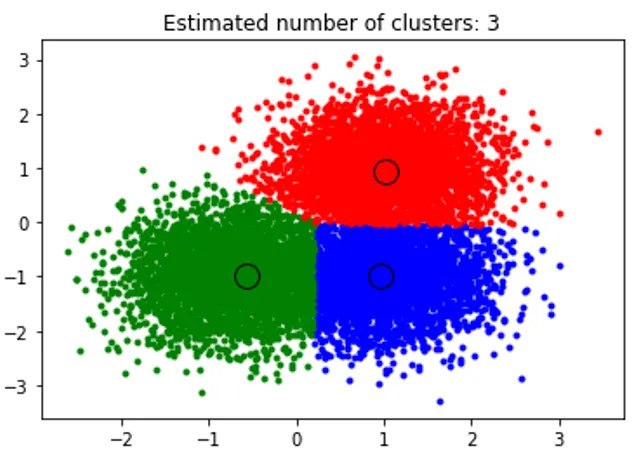
Zgornji delček izvaja združevanje, algoritem pa je našel grozde v središču vsakega ustvarjenega bloba. Iz spodnje slike, ki jo izriše delček, lahko vidimo, da algoritem Srednjega premika lahko prepozna število gruč, potrebnih v času izvajanja, in ugotovi ustrezno pasovno širino, ki predstavlja dolžino interakcije.
Izhod:
Primer # 2
Na podlagi segmentacije slike v računalniškem vidu. Drugi delček bo raziskal, kako se algoritem srednjega premika uporablja v globinskem učenju za izvajanje segmentacije barvne slike. Za identifikacijo prostorskih grozdov uporabljamo algoritem Srednji premik. Zgodnji delček smo uporabili dvodimenzionalni niz podatkov, medtem ko bomo v tem primeru raziskali tridimenzionalni prostor. Pixel slike bo obravnavan kot podatkovna točka (r, g, b). Sliko moramo pretvoriti v format matrike, tako da bo vsak slikovni pik predstavljal podatkovno točko v sliki, ki jo bomo odsekali. Grupiranje barvnih vrednosti v vesolje vrne serijo gruč, kjer bodo slikovne pike podobne prostoru v RGB. Paketi, ki se uporabljajo za izvajanje algoritma Srednji premik:
Koda:
importnumpy as np
fromcluster importMeanShift, estimate_bandwidth
fromdatasets.samples_generator importmake_blobs
importpyplot as plt
fromitertools import cycle
fromPIL import Image
Spodaj Snippet za izvedbo segmentacije izvirne slike:
#Segmentation of Color Image
img = Image.open('Sample.jpg.webp')
img = np.array(img)
#Need to convert image into feature array based
flatten_img=np.reshape(img, (-1, 3))
#bandwidth estimation
est_bandwidth = estimate_bandwidth(flatten_img,
quantile=.2, n_samples=500)
mean_shift = MeanShift(est_bandwidth, bin_seeding=True)
fit(flatten_img)
labels= mean_shift.labels_
# Plot image vs segmented image
figure(2)
subplot(1, 1, 1)
imshow(img)
axis('off')
subplot(1, 1, 2)
imshow(np.reshape(labels, (854, 1224)))
axis('off')
Ustvarjena slika navaja, da je ta pristop za prepoznavanje oblik slik in določitev prostorskih grozdov mogoče učinkovito brez kakršne koli obdelave slike.
Izhod:


Prednosti in aplikacije pomeni algoritem premika
Spodaj so prednosti in uporaba algoritma povprečja:
- Široko se uporablja za reševanje računalniškega vida, kjer se uporablja za segmentacijo slike.
- Grozd podatkovnih točk v realnem času brez navedbe števila grozdov.
- Učinkovito deluje na segmentaciji slike in sledenju videoposnetkov.
- Bolj trden do zunanjih ljudi.
Prednosti algoritma povprečnega premika
Spodaj so algoritmi premika povprečja prednosti:
- Izhod algoritma ni odvisen od inicializacij.
- Postopek je učinkovit, saj ima samo en parameter - pasovno širino.
- Brez predpostavk o številu skupin podatkov in obliki.
- Ima boljše delovanje kot K-Means Clustering.
Slabosti algoritma povprečnega premika
Spodaj so slabosti algoritma povprečnega premika:
- Draga za velike funkcije.
- V primerjavi s skupino K-Means je zelo počasen.
- Izhod algoritma je odvisen od pasovne širine parametra.
- Izhod je odvisen od velikosti okna.
Zaključek
Čeprav gre za preprost pristop, ki se je v prvi vrsti uporabljal za reševanje problemov, povezanih s segmentacijo slike, grozdenjem. Je sorazmerno počasnejši od K-Means in je računsko drag.
Priporočeni članki
To je vodnik po algoritmu Srednji premik. Tukaj razpravljamo o težavah, povezanih s segmentacijo slike, združevanjem v skupine, prednostmi in dvema funkcijama jedra. Obiščite lahko tudi druge naše sorodne članke, če želite izvedeti več -
- K- Pomeni algoritem grozda
- Algoritem KNN v R
- Kaj je genetski algoritem?
- Metode jedrca
- Metode jedrca v strojnem učenju
- Podrobna razlaga algoritma C ++