

Razlika med Hadoopom in panjom
Hadoop:
Hadoop je okvir ali programska oprema, ki je bila izumljena za upravljanje ogromnih podatkov ali velikih podatkov. Hadoop se uporablja za shranjevanje in obdelavo velikih podatkov, razporejenih po kopici blagovnih strežnikov.
Hadoop shranjuje podatke z uporabo distribuiranega datotečnega sistema Hadoop in jih obdeluje / poizveduje s pomočjo programskega modela Map Reduce.
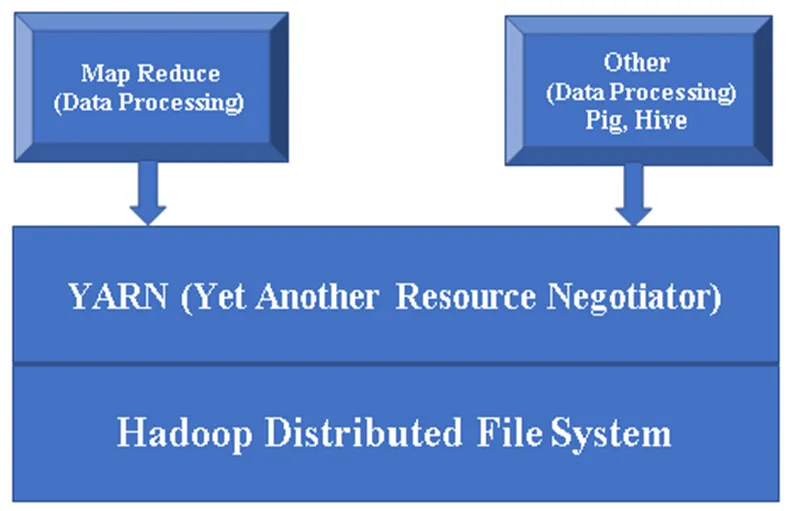
Slika 1, osnovna arhitektura komponente Hadoop.
Glavni sestavni deli Hadoopa:
Hadoop Base / Common: Hadoop common vam bo zagotovil eno platformo za namestitev vseh njegovih komponent.
HDFS (Hadoop Distributed File System): HDFS je glavni del okvira Hadoop, ki skrbi za vse podatke v Hadoop Clusterju. Deluje na glavni / podrejeni arhitekturi in podatke shranjuje z uporabo podvajanja.
Glavni / podrejena arhitektura in podvajanje:
- Glavno vozlišče / ime vozlišča: Ime vozlišča shrani metapodatke vsakega bloka / datoteke, shranjene v HDFS, HDFS ima lahko samo eno glavno vozlišče (v primeru HA drugo glavno vozlišče deluje kot sekundarno glavno vozlišče).
- Podrejeno vozlišče / podatkovno vozlišče: Podatkovna vozlišča vsebujejo dejanske podatkovne datoteke v blokih. HDFS ima lahko več podatkovnih vozlišč.
- Podvajanje: HDFS shranjuje svoje podatke tako, da jih deli na bloke. Privzeta velikost bloka je 64 MB. Podatki se zaradi podvajanja shranijo v 3 (privzeti faktor podvajanja se lahko poveča na zahtevo) različnih podatkovnih vozlišč, zato obstaja najmanj možnost izgube podatkov v primeru okvare vozlišča.
PRIJAZ (še en pogajalec o virih): V osnovi se uporablja za upravljanje virov Hadoop, pomembno vlogo pa ima tudi pri načrtovanju uporabnikove aplikacije.
MR (Zmanjšanje zemljevida): To je osnovni programerski model Hadoopa. Uporablja se za obdelavo / poizvedovanje podatkov v okviru Hadoop.
Panj:
Hive je aplikacija, ki deluje preko okvira Hadoop in ponuja vmesnik SQL za obdelavo / poizvedovanje podatkov. Hive je zasnoval in razvil Facebook, preden je postal del projekta Apache-Hadoop.
Hive izvede svojo poizvedbo z uporabo HQL (jezik poizvedbe Hive). Hive ima enako strukturo kot RDBMS, v panju pa se lahko uporabljajo skoraj enaki ukazi.
Hive lahko podatke shrani v zunanje tabele, tako da ni obvezno uporabljati HDFS, poleg tega pa podpira formate datotek, kot so ORC, datoteke Avro, datoteke zaporedja in besedilne datoteke itd.
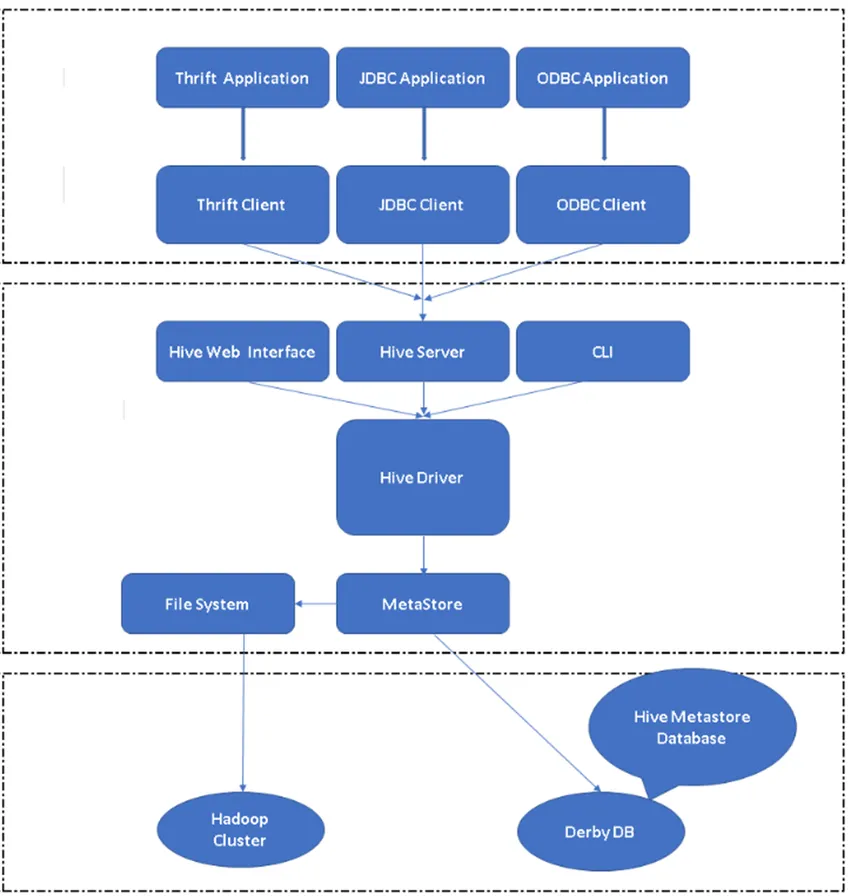
Slika 2, Hive's Architecture & Glavni sestavni deli.
Glavni sestavni del panj:
Odjemalci Hive: Ne le SQL, Hive podpira tudi programske jezike, kot so Java, C, Python z uporabo različnih gonilnikov, kot so ODBC, JDBC in Thrift. Eden lahko napiše katero koli aplikacijo za odjemalce pive v drugih jezikih in lahko te programe izvaja v Hive.
Storitve panja: V okviru Pive Services poteka izvajanje ukazov in poizvedb. Spletni vmesnik za panj ima pet podkomponent.
- CLI: Privzeti vmesnik ukazne vrstice, ki ga ponuja Hive za izvajanje poizvedb / ukazov Hive.
- Spletni vmesniki za panj: Je preprost grafični uporabniški vmesnik. Je alternativa ukazni vrstici Hive in se uporablja za izvajanje poizvedb in ukazov v aplikaciji Hive.
- Panj strežnik: Imenujejo ga tudi kot Apache Thrift. Odgovoren je za sprejemanje ukazov iz različnih - različnih vmesnikov ukazne vrstice in posredovanje vseh ukazov / poizvedb podjetju Hive ter pridobiva končni rezultat.
- Apache Hive Driver: Odgovoren je za to, da odjemalec vhodi iz vmesnikov CLI, spletnega uporabniškega vmesnika, ODBC, JDBC ali Thrift posreduje podatke v metastore, kjer so shranjene vse informacije o datoteki.
- Metastore: Metastore je shramba za shranjevanje vseh metapodatkov o Hive. Metapodatki podjetja Hive shranjujejo podatke, kot so struktura tabel, particij in vrste stolpcev itd…
Hive Storage: To je lokacija, kjer se izvajajo dejanske naloge. Vsa poizvedba, ki se izvajajo od Hive, je izvedla dejanje znotraj Hive storage.
Primerjava med Hadoopom in Hivejem (Infographics)
Spodaj je zgornjih 8 razlik med Hadoop proti Hive
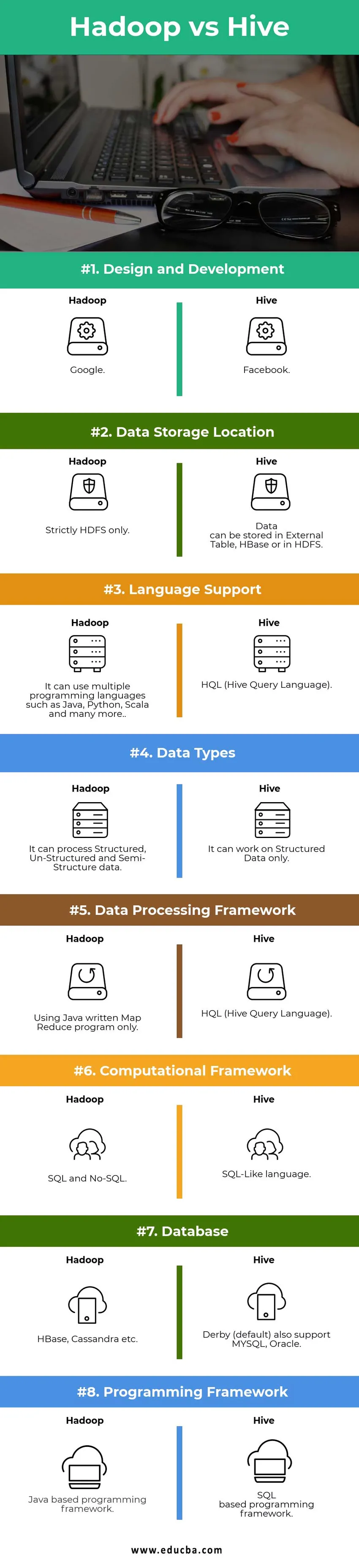
Ključne razlike med Hadoop in Hive:
Spodaj so seznami točk, opišite ključne razlike med Hadoopom in Pivem:
1) Hadoop je okvir za obdelavo / poizvedovanje velikih podatkov, medtem ko je Hive orodje, ki temelji na SQL, ki nadgradi Hadoop za obdelavo podatkov.
2) Hive obdeluje / poizveduje vse podatke z uporabo HQL (Hive Query Language), ki je podoben SQL jeziku, medtem ko Hadoop lahko razume samo zmanjšanje zemljevida.
3) Zmanjšanje zemljevida je sestavni del Hadoop-a, Hiveovo poizvedbo najprej pretvorite v pomanjšanje zemljevida, kot jo Hadoop obdela, da poizveduje po podatkih.
4) Hive deluje na poizvedbi SQL, medtem ko ga Hadoop razume samo z uporabo Java Reduced Map Reduce.
5) V Hive, prej uporabljene tradicionalne ukaze "Relacijska podatkovna baza", lahko uporabite tudi za poizvedovanje o velikih podatkih, medtem ko ste v Hadoopu, morate pisati zapletene programe za zmanjšanje zemljevida z uporabo Jave, ki ni podobna tradiciji Java.
6) Hive lahko obdeluje / poizveduje samo strukturirane podatke, medtem ko je Hadoop namenjen vsem vrstam podatkov, bodisi strukturiranim, nestrukturiranim ali polstrukturiranim.
7) S pomočjo Hive lahko človek obdela in poizveduje podatke brez zapletenega programiranja, medtem ko mora v ekosistemu Simple Hadoop napisati zapleten program Java za iste podatke.
8) Ena stran Hadoop okviri potrebujejo 100s vrstico za pripravo MR-programa, ki temelji na Javi, druga stran Hadoop s Hive pa lahko poizveduje iste podatke z uporabo 8 do 10 vrstic HQL.
9) V Hive je zelo težko vstaviti izhod ene poizvedbe kot vnos druge, medtem ko je isto poizvedbo mogoče enostavno opraviti z uporabo Hadoopa z MR.
10) Metastore ni znotraj skupine Hadoop, medtem ko Hadoop shranjuje vse svoje metapodatke v HDFS (Hadoop Distributed File System).
Hadoop vs Hive primerjalna tabela
| Primerjalne točke | Panj | Hadoop |
|
Oblikovanje in razvoj | ||
| Lokacija shranjevanja podatkov |
Podatki se lahko shranijo v Zunanji Tabela, HBase ali v HDFS. | Strogo samo HDFS. |
| Jezikovna podpora | HQL (jezik poizvedbe panj) |
Uporablja lahko več programskih jezikov, kot so Java, Python, Scala in še mnogo drugih. |
| Vrste podatkov | Deluje lahko samo na strukturirane podatke. |
Lahko obdeluje strukturirane, nestrukturirane in polstrukturne podatke. |
| Okvir za obdelavo podatkov |
HQL (jezik poizvedbe panj) | Uporaba samo programa Java Reduce Map Reduce. |
|
Računalniški okvir | SQL podoben jezik. | SQL in No-SQL. |
| Baza podatkov |
Derby (privzeto) podpira tudi MYSQL, Oracle… | HBase, Cassandra itd…. |
| Programski okvir |
Programiranje na osnovi SQL. | Programski okvir, ki temelji na Javi. |
Zaključek - Hadoop proti Hive
Hadoop in Hive se uporabljata za obdelavo velikih podatkov. Hadoop je okvir, ki ponuja platformo za druge aplikacije za poizvedovanje / obdelavo velikih podatkov, medtem ko je Hive le aplikacija, ki temelji na SQL-u in obdeluje podatke s pomočjo HQL-a (Hive Query Language)
Hadoop lahko uporabljate brez Hive za obdelavo velikih podatkov, medtem ko uporabe Hivea brez Hadoopa ni enostavno.
Za zaključek ne moremo tako ali tako v nobenem pogledu primerjati Hadoop in Hive. Tako Hadoop kot Hive sta si povsem različna. Če skupaj uporabljate obe tehnologiji, lahko postopek poizvedovanja po velikih podatkih postane veliko lažji in udobnejši za uporabnike velikih podatkov.
Priporočeni članki:
To je vodnik za Hadoop vs Pive, njihov pomen, primerjava med glavo, ključne razlike, tabela primerjave in sklep. Če želite izvedeti več, si oglejte tudi naslednje članke -
- Hadoop proti Apache Spark - zanimive stvari, ki jih morate vedeti
- HADOOP vs RDBMS | Poznajte 12 uporabnih razlik
- Kako veliki podatki spreminjajo obraz zdravstvenega varstva
- Top 12 primerjava Apache Hive z Apache HBase (Infographics)
- Amazing Guide on Hadoop vs Spark