

Razlika med Apache Nifi in Apache Spark
Do dolgo časa, ko je bilo treba opraviti težko delo, so se ljudje zanašali na konje za vleko težkih tovorov, vzdrževanje hitrosti ali česar koli drugega vmes. Vendar niso bili vsi konji primerni za vsako opravilo. Enako je danes s tehnologijo. S pojavom novih tehnologij, ki se pojavljajo vsak dan, postaja izredno pomembno poznati njihove resnične aplikacije. Dve takšni tehnologiji sta Apache Nifi in Apache Spark in o njih se bomo v tej objavi preučili.
Apache Spark je odprtokodni okvir z grozdovimi računi, katerega namen je zagotoviti vmesnik za programiranje celotnega niza grozdov z implicitno odstopanjem napak in paralelizmom podatkov. Uporablja RDD (Resilient Distributed Nets) in obdeluje podatke v obliki Diskretiziranih tokov, ki se nadalje uporabljajo v analitične namene.
Apache Nifi (ki je kratka oblika NiagaraFiles) je še en program, katerega namen je avtomatizirati pretok podatkov med programskimi sistemi. Zasnova temelji na modelu programiranja na osnovi pretoka, ki zagotavlja funkcije, ki vključujejo delovanje z zmogljivostjo grozdov. Je enostaven za uporabo, zanesljiv in močan sistem za obdelavo in distribucijo podatkov. Podpira skalabilne usmerjene grafe za usmerjanje podatkov, sistemsko posredovanje in logiko transformacije. Pogovorimo se o primerjavah obeh tem.
Primerjava med glavo Apache Nifi proti Apache Spark (Infographics)
Spodaj je zgornjih 9 primerjav med Apache Nifi in Apache Spark
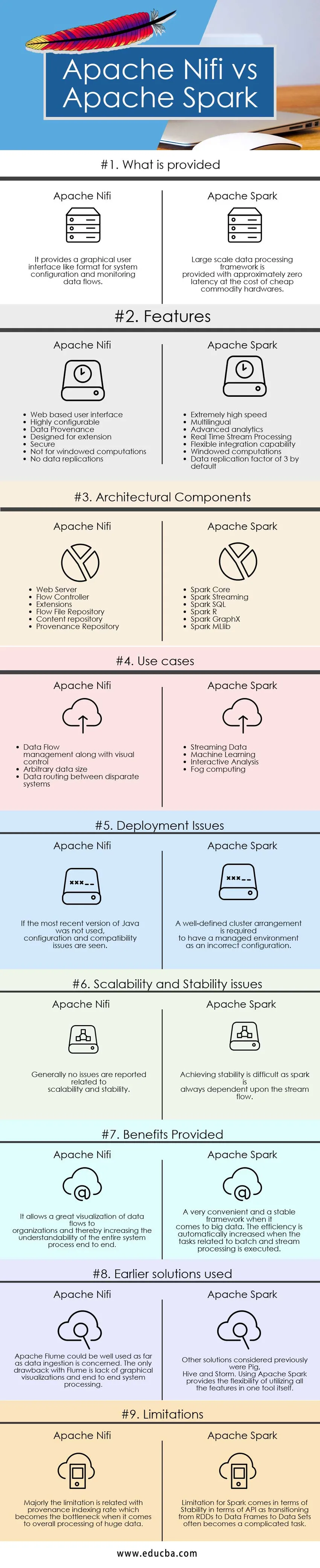
Ključne razlike med Apache Nifi proti Apache Spark
Razlike med Apache Nifi in Apache Spark so razložene v spodnjih točkah:
- Apache Nifi je orodje za zaužitje podatkov, ki se uporablja za zagotavljanje enostavnega, zmogljivega in zanesljivega sistema, tako da obdelava in distribucija podatkov po virih postane enostavna, medtem ko je Apache Spark izjemno hitra računalniška tehnologija, ki je zasnovana za hitrejše računanje s strani učinkovito izkoriščanje interaktivnih poizvedb pri upravljanju pomnilnika in zmožnosti obdelave tokov.
- Apache Nifi deluje v samostojnem načinu in v grozdnem načinu, medtem ko Apache Spark deluje dobro v lokalnem ali samostojnem načinu, Mesosu, Preji in drugih vrstah velikih podatkovnih skupin.
- Značilnosti Apache Nifi vključujejo zajamčeno dostavo podatkov, učinkovito združevanje podatkov, prednostno čakalno čakanje, specifični QoS, protokol podatkov, obnavljanje varnostnega blažilnika, vizualni ukaz in nadzor, predloge pretoka, varnost, zmožnosti vzporednega pretakanja, medtem ko funkcije apache iskre vključujejo strelovodenje hitrost obdelave, večjezičnost, računalništvo v pomnilniku, učinkovita uporaba strojnih sistemov blaga, napredna analitika, učinkovita sposobnost integracije.
- Apache Nifi omogoča boljšo berljivost in splošno razumevanje sistema z zagotavljanjem vizualizacijskih zmogljivosti in funkcij povleci in spusti. Pretok podatkov je mogoče enostavno upravljati in upravljati z običajnimi tehnikami in postopki, medtem ko je v primeru Apache Spark za ogled tovrstnih vizualizacij potreben sistem upravljanja grozdov, kot je Ambari. Apache Spark sam po sebi ne omogoča vizualizacijskih zmogljivosti in je dober le, kar se tiče programiranja. Daleč je zelo priročen in stabilen sistem za obdelavo ogromnih količin podatkov.
- Omejitev z Apache Nifi je povezana s tem, kaj je njegova prednost. Edina funkcija povleci in spusti zagotavlja omejitev, da ne moremo spreminjati obsega in zagotoviti robustnosti, ko gre za njegovo integracijo z drugimi komponentami in orodji, medtem ko v primeru Apache Spark primarna omejitev prihaja do uporabe obsežne strojne opreme in upravljanja z njimi na trenutke postane dolgočasna naloga. Druga omejitev, o kateri je poročano, prihaja skupaj z zmogljivostmi pretakanja, povezanimi z diskretiziranim tokom in okenskim ali paketnim tokom, kjer transformacija RDD-jev v okvir podatkov in naborov podatkov včasih povzroči nestabilnost.
Primerjalna tabela Apache Nifi proti Apache Spark
| Osnove primerjave | Apache Nifi | Apache iskrica |
| Kaj je zagotovljeno | Ponuja grafični uporabniški vmesnik, kot je oblika za konfiguracijo sistema in spremljanje pretokov podatkov. | Okvir za obsežno obdelavo podatkov je zagotovljen s približno nič zamudnimi stroški za ceno poceni strojne opreme. |
| Lastnosti |
|
|
| Arhitekturne komponente |
|
|
| Uporabite primere |
|
|
| Vprašanja uvajanja | Če najnovejša različica Jave ni bila uporabljena, so vidne težave s konfiguracijo in združljivostjo | Za pravilno upravljano okolje kot napačno konfiguracijo je potrebna natančno določena skupina grozdov |
| Težave z razširljivostjo in stabilnostjo | Na splošno ni poročil o težavah, povezanih z razširljivostjo in stabilnostjo | Doseganje stabilnosti je težko, saj je iskra vedno odvisna od toka potoka. |
| Zagotovljene ugodnosti | Omogoča odlično vizualizacijo pretokov podatkov v organizacije in s tem povečuje razumljivost celotnega sistemskega procesa do konca | Zelo priročen in stabilen okvir, ko gre za velike podatke. Učinkovitost se samodejno poveča, ko se opravijo naloge, povezane z paketno in pretočno obdelavo. |
| Uporabljene prejšnje rešitve | Apache Flume bi bilo mogoče uporabiti kar se tiče zaužitja podatkov. Edina pomanjkljivost Flume je pomanjkanje grafičnih vizualizacij in sistemske obdelave | Druge prej obravnavane rešitve so bile Prašiči, panj in nevihta. Uporaba Apache Spark zagotavlja fleksibilnost uporabe vseh funkcij v enem orodju. |
| Omejitve | Omejitev je večinoma povezana s stopnjo indeksiranja porekla, ki postane ozko grlo, kadar gre za splošno obdelavo ogromnih podatkov | Omejitev za Spark prihaja v smislu stabilnosti v smislu API-ja, saj prehod iz RDD-jev v podatkovne okvirje na nabore podatkov pogosto postane zapletena naloga. |
Zaključek - Apache Nifi proti Apache Spark
Za zaključek prispevka lahko rečemo, da je Apache Spark težek konjski konj, medtem ko je Apache Nifi spreten dirkaški konj. Oba imata svoje prednosti in omejitve, ki ju je treba uporabiti na svojih področjih. Odločiti se morate za pravo orodje za vaše podjetje. Spremljajte članke, povezane z novejšimi tehnologijami velikih podatkov, na našem blogu.
Priporočeni članek
To je vodnik za Apache Nifi proti Apache Spark, njihov pomen, primerjava med glavo, ključne razlike, tabela primerjave in sklep. Če želite izvedeti več, si oglejte tudi naslednje članke -
- Apache Hadoop in Apache Spark | Top 10 primerjav, ki jih moraš vedeti!
- Apache Storm proti Apache Spark - Naučite se 15 uporabnih razlik
- 7 pomembnih stvari o Apache Spark (vodnik)
- Najboljših 15 stvari, ki jih morate vedeti o MapReduce vs Spark