

Uvod v tehnike podatkovne znanosti
V današnjem svetu, kjer so podatki novo zlato, so na voljo različne vrste analiz za podjetja. Rezultat projekta s področja znanosti o podatkih se močno razlikuje glede na vrsto razpoložljivih podatkov, zato je tudi vpliv spremenljiv. Ker je na voljo veliko različnih vrst analiz, je treba nujno razumeti, kaj je treba izbrati nekaj osnovnih metod. Bistveni cilj tehnik znanosti podatkov ni samo iskanje ustreznih informacij, temveč tudi odkrivanje šibkih povezav, zaradi katerih model slabo deluje.
Kaj je Data Science?
Podatkovna znanost je področje, ki se širi v več disciplin. Vključuje znanstvene metode, procese, algoritme in sisteme za zbiranje znanja in delo na istem. To polje vključuje različne zvrsti in je skupna platforma za poenotenje pojmov statistika, analiza podatkov in strojno učenje. Pri tem teoretično znanje statistike, skupaj s podatki v realnem času in tehnikami pri strojnem učenju z roko v roki, prinašajo pozitivne rezultate za podjetje. Z uporabo različnih tehnik, ki se uporabljajo v podatkovni znanosti, lahko v današnjem svetu nakazujemo na boljše odločanje, ki bi sicer lahko zamudilo človeško oko in um. Ne pozabite, da stroj nikoli ne pozabi! Za povečanje dobička v svetu, ki temelji na podatkih, je čarobnost Data Science nujno orodje.
Različne vrste tehnike znanosti podatkov
V naslednjih nekaj odstavkih bomo preučili skupne tehnike znanosti o podatkih, ki se uporabljajo v vsakem drugem projektu. Čeprav je včasih znanost o teh podatkih poslovno specifična in morda ne sodi v spodnje kategorije, je povsem v redu, da jih označimo kot različne vrste. Na visoki ravni delimo tehnike na nadzorovane (poznamo ciljni vpliv) in nenadzorovane (ne vemo za ciljno spremenljivko, ki jo poskušamo doseči). V naslednji stopnji lahko tehnike razdelimo glede na:
- Rezultat, ki bi ga dobili, ali kakšen je namen poslovne težave
- Vrsta uporabljenih podatkov
Naj najprej pogledamo segregacijo na podlagi namere.
1. Nenadzorovano učenje
- Zaznavanje anomalije
Pri tej vrsti tehnike prepoznamo vsak nepričakovani pojav v celotnem naboru podatkov. Ker se vedenje razlikuje od dejanskega dogajanja v podatkih, so osnovne predpostavke naslednje:
- Pojav teh primerov je zelo majhen.
- Razlika v vedenju je precejšnja.
Pojasnjeni so algoritmi anomalije, na primer Isolation Forest, ki zagotavlja rezultat za vsak zapis v naboru podatkov. Ta algoritem je drevesni model. Z uporabo te vrste tehnike zaznavanja in njene priljubljenosti se uporabljajo v različnih poslovnih primerih, na primer pri ogledih spletnih strani, hitrosti strjevanja, prihodku na klik itd. Na spodnjem grafu lahko razložimo, kako izgleda anomalija.
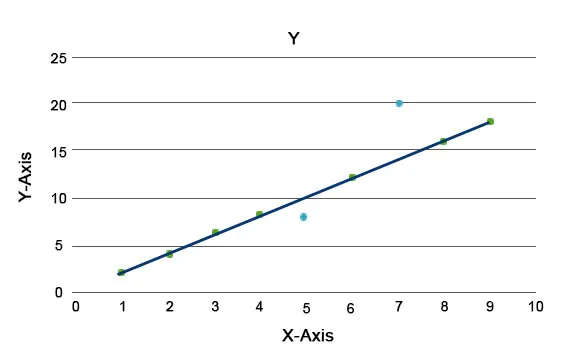
Tu so modre barve anomalije v naboru podatkov. Razlikujejo se od običajne linije trendov in se pojavljajo manj.
- Grozdna analiza
S to analizo je glavna naloga ločitev celotnega nabora podatkov v skupine, tako da so trendi ali lastnosti podatkovnih točk v eni skupini med seboj precej podobni. V terminologiji podatkovne znanosti jih imenujemo grozd. Na primer, v maloprodajnem podjetju obstaja načrt obsega poslovanja in nujno je vedeti, kako bi se novi kupci obnašali v novi regiji na podlagi preteklih podatkov, ki jih imamo. Nemogoče je oblikovati strategijo za vsakega posameznika v populaciji, vendar bo koristno, da se populacija razdeli v grozde, tako da bo strategija učinkovita v skupini in je razširljiva.
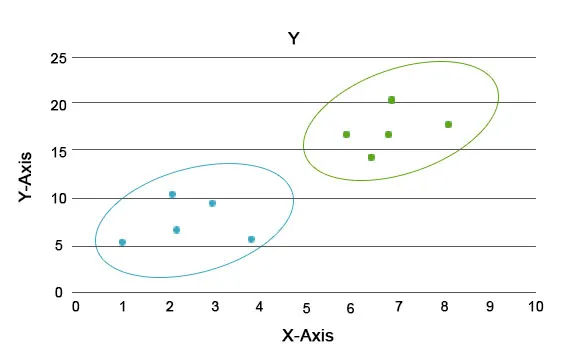
Tu sta modra in oranžna barva različni grozdi, ki imajo v sebi edinstvene lastnosti.
- Analiza povezav
Ta analiza nam pomaga pri vzpostavljanju zanimivih odnosov med predmeti v naboru podatkov. Ta analiza odkrije skrite odnose in pomaga pri predstavitvi elementov podatkovnih zbirk v obliki pravil za povezovanje ali nabora pogostih elementov. Pravilo povezave je razčlenjeno na 2 koraka:
- Pogosta generacija nabora predmetov: V tem se ustvari nabor, kjer se pogosto pojavljajo elementi, ki so postavljeni skupaj.
- Generacija pravil: Zgornji niz, ki je vgrajen zgoraj, se prenaša skozi različne plasti oblikovanja pravil, da se ustvari skrit odnos med seboj. Na primer, nabor lahko spada v konceptualne ali izvedbene težave ali v težave z aplikacijo. Te se nato razgradijo na posamezna drevesa, da se oblikujejo pravila za pridružitev.
Na primer, APRIORI je algoritem povezovanja pravil za povezovanje.
2. Nadzorovano učenje
- Regresijska analiza
V regresijski analizi določimo odvisno / ciljno spremenljivko in preostale spremenljivke kot neodvisne spremenljivke in sčasoma domnevamo, kako ena / več neodvisnih spremenljivk vpliva na ciljno spremenljivko. Regresija z eno samostojno spremenljivko se imenuje univariatna, z več kot eno pa je znana kot multivariatna. Naj razumemo, če uporabimo univariatno in nato lestvico za multivariatno.
Na primer, y je ciljna spremenljivka in x 1 je neodvisna spremenljivka. Torej iz poznavanja ravne črte lahko enačbo zapišemo kot y = mx 1 + c. Tu "m" določa, kako močno y vpliva x 1 . Če je "m" zelo blizu nič, to pomeni, da s spremembo x 1 y ne vpliva močno. Če je število večje od 1, se učinek krepi in majhna sprememba x 1 privede do velike razlike v y. Podobno kot univariata lahko tudi v multivariatnem zapišemo kot y = m 1 x 1 + m 2 x 2 + m 3 x 3 ………., Tudi tukaj je vpliv vsake neodvisne spremenljivke določen z ustreznim „m“.
- Analiza klasifikacije
Podobno kot z grozdnimi analizami so tudi algoritmi za razvrstitev zgrajeni s ciljno spremenljivko v obliki razredov. Razlika med združevanjem in klasifikacijo je v tem, da pri združevanju ne vemo, v katero skupino sodijo podatkovne točke, medtem ko pri razvrščanju vemo, v katero skupino spada. In od regresije se razlikuje z vidika, da bi moralo biti število skupin fiksno število za razliko od regresije, je neprekinjeno. Obstaja kopica algoritmov pri klasifikacijski analizi, na primer podporni vektorski stroji, logistična regresija, odločitvena drevesa itd.
Zaključek
Za zaključek razumemo, da je vsaka vrsta analiz sama po sebi obsežna, vendar lahko tukaj damo majhen okus različnim tehnikam. V naslednjih nekaj opombah bi vzeli vsakega posebej in se podrobneje seznanili z različnimi podtehnikami, uporabljenimi v vsaki od tehnik.
Priporočeni članek
To je vodnik po Tehniki znanosti o podatkih. Tukaj razpravljamo o uvedbi in različnih vrstah tehnik v znanosti o podatkih. Če želite izvedeti več, lahko preberete tudi druge naše predlagane članke -
- Orodja za podatkovno znanost | 12 najboljših orodij
- Algoritmi s podatki o tipih podatkov
- Uvod v podatkovno kariero podatkov
- Data Science vs vizualizacija podatkov
- Primeri multivariatne regresije
- Ustvarite drevo odločitev s prednostmi
- Kratek pregled življenjskega cikla Data Science