

Uvod v ukaze panj
Ukaz Hive je orodje za infrastrukturo skladišča podatkov, ki sedi na vrhu Hadoopa in povzema velike podatke. Obdeluje strukturirane podatke. Olajša poizvedovanje in analiziranje podatkov. Ukaz Hive se imenuje tudi "shema pri branju". Hive ne preveri podatkov, ko se naloži, preverjanje se zgodi le, ko je poslana poizvedba. Ta lastnost panja omogoča hitro nalaganje. To je kot kopiranje ali preprosto premikanje datoteke brez omejitev ali preverjanj. Panj je prvi razvil Facebook. Kasneje jo je prevzela programska fundacija Apache in jo nadalje razvijala.
Tu so sestavni deli ukaza Hive:
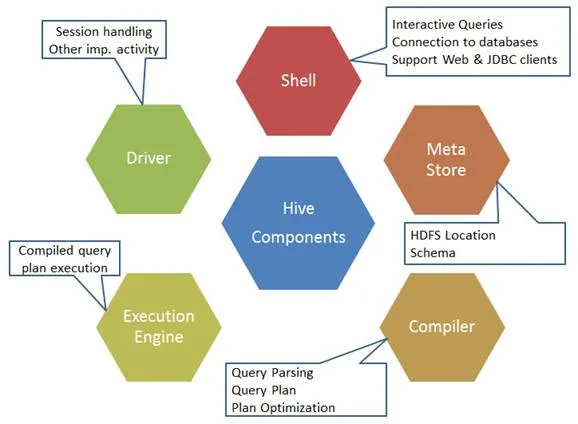
Slika 1. Sestavni deli panja
https://www.developer.com/
Spodaj so naštete funkcije ukaza Pive:
- Trgovine za panje so surovi in predelani nabor podatkov v Hadoopu.
- Zasnovan je za on-line obdelavo transakcij (OLTP). OLTP so sistemi, ki omogočajo veliko količino podatkov v zelo krajšem času, ne da bi se zanašali na en sam strežnik.
- Je hiter, razširljiv in zanesljiv.
- Poizvedovalni jezik vrste SQL, naveden tukaj, se imenuje HiveQL ali HQL. To olajša naloge ETL in druge analize.
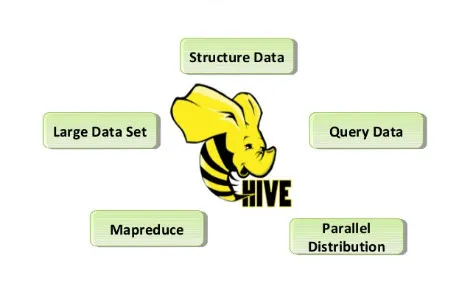
Slika 2. Lastnosti panja
Slike virov: - Google
Tudi v ukazu Hive je malo omejitev, ki so navedene spodaj:
- Hive ne podpira poizvedb.
- Hive zagotovo podpira prepisovanje, žal pa ne podpira brisanja in posodobitev.
- Panj ni zasnovan za OLTP, ampak se zanj uporablja.
Za vnos interaktivne lupine panj:
$ HIVE_HOME / koš / panj
Osnovni ukazi panja
-
Ustvari
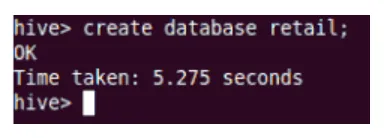
To bo ustvarilo novo bazo podatkov v podjetju Hive.
-
Spusti
Kapljica bo odstranila mizo iz Pive
-
Spreminjati
Ukaz Alter vam bo pomagal preimenovati tabelo ali stolpce tabel.
Na primer:
panj> ALTER TABLE zaposlenega PRENEŽI zaposlenemu1;
-
Pokaži
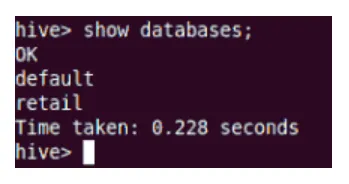
Ukaz Show bo prikazal vse baze podatkov, ki so nastanjene v panju.
-
Opišite
Ukaz Opisi vam bo pomagal pri informacijah o shemi tabele.
Vmesni ukazi panja
Panj razdeli tabelo na različno povezane particije na podlagi stolpcev. S temi particijami boste lažje iskali podatke. Te particije se nadalje delijo v vedre in tako učinkovito izvajajo poizvedbe po podatkih.
Z drugimi besedami, vedra razdelijo podatke v niz gruč, tako da izračunajo hash kodo ključa, omenjeno v poizvedbi.
-
Dodajanje particije
Dodajanje particije je mogoče doseči s spreminjanjem tabele. Recimo, da imate tabelo EMP s polji, kot so Id, Ime, Plača, Dept, Oznaka in yoj.
panj> ALTER TABLE zaposleni
> DODAJ DELO (leto = '2012')
lokacija '/ 2012 / part2012';
-
Preimenovanje particije
panj> ALTER TABLE PARTICION (leto = '1203')
PRENEŽITE SE NA DELO (Yoj = '1203');
-
Spusti particijo
panj> ALTER TABLE DROP (ČE OBSTOJE)
> DELITEV (leto = '1203');
-
Relacijski upravljavci
Relacijski operaterji so sestavljeni iz določenega sklopa operaterjev, ki pomaga pri pridobivanju ustreznih informacij.
Na primer: Recite, da je tabela "EMP" videti tako:
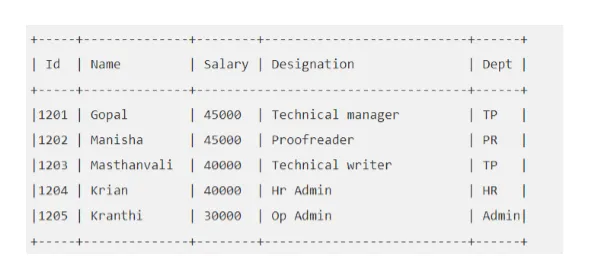
Izvedimo poizvedbo Hive, ki nam bo prinesla zaposlenega, katerega plača je večja od 30000.
panj> IZBIRAJO * IZ EMP, KJER JE Plača> = 40000;
-
Aritmetični operaterji
To so operaterji, ki pomagajo pri izvajanju aritmetičnih operacij na operandih in tako vedno vrnejo številčne vrste.
Na primer: Če želite dodati dve številki, na primer 22 in 33
panj> IZBERI 22 + 33 DODAJ IZ temp;
-
Logični operater
Ti operaterji naj izvajajo logične operacije, ki v zameno vedno vrnejo True / False.
panj> IZBIRAJ * IZ EMP KJE Plača> 40000 && Dept = TP;
Napredni ukazi za panj
-
Pogled
Koncept pogleda v Hiveu je podoben kot v SQL-u. Pogled se lahko ustvari v času izvajanja stavka SELECT.
Primer:
panj> CREATE VIEW EMP_30000 AS
IZBERI * IZ EMP
KJE plača> 30000;
-
Nalaganje podatkov v tabelo
Panj> Naloži podatke lokalno na poti '/home/hduser/Desktop/AllStates.csv' v države tabele;
Tu je »Države« že ustvarjena tabela v panju.
https://www.tutorialspoint.com/hive/
Hive ima nekaj vgrajenih funkcij, ki vam pomagajo pri boljšem rezultatu.
Kot okrogla, talna, BIGINT itd.
-
Pridružite se
Klavzula pridruživanja lahko pomaga pri združevanju dveh tabel na podlagi istega imena stolpca.
Primer:
panj> IZBERI c.ID, c.NAME, c.AGE, o.AMOUNT
PRI KUPCIH c PRIDRUŽITE NAROČILA o
ON (c.ID = o.CUSTOMER_ID);
Hive podpirajo vse vrste spojev: levi zunanji spoj, desni zunanji spoj, polni zunanji spoj.
Nasveti in nasveti za uporabo ukazov panja
Hive naredi obdelavo podatkov tako enostavno, enostavno in razširljivo, da uporabnik posveča manj pozornosti optimizaciji poizvedb Hive. Toda če boste med pisanjem poizvedbe v Hive pozorni na nekaj stvari, bo zagotovo prinesel velik uspeh pri obvladovanju delovne obremenitve in prihranku denarja. Spodaj je nekaj nasvetov v zvezi s tem:
- Predelne stene in vedri: Hive je veliko podatkovno orodje, ki lahko poizveduje na velikih naborih podatkov. Vendar lahko pisanje poizvedbe brez razumevanja domene prinese velike particije v Hive.
Če uporabnik pozna nabor podatkov, je mogoče ustrezne in zelo uporabljene stolpce združiti v isto particijo. To bo pomagalo pri hitrejšem in neučinkovitem izvajanju poizvedbe.
Na koncu je št. zmanjšal se bo tudi delovanje zemljevidov in V / I operacij.
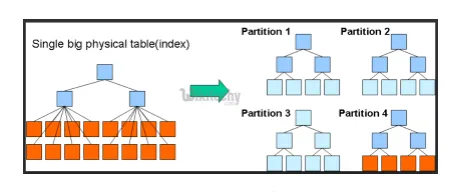
Slika 3. Predelna stena
Slike virov: Googlova slika
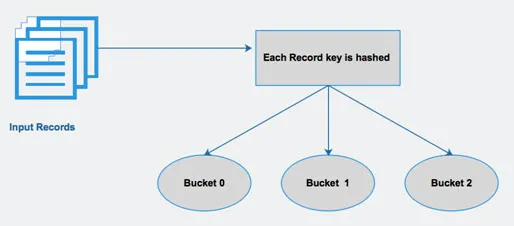
Slika 4 Žepkanje
Slike virov: - Googlova slika
- Vzporedno izvajanje: Hive izvaja poizvedbo v več stopnjah. V nekaterih primerih so te faze lahko odvisne od drugih faz, zato se po predhodni stopnji ne more začeti. Vendar lahko neodvisne naloge tečejo vzporedno, da prihranijo celoten čas teka. Če želite omogočiti vzporedni tek v panju:
nastavi hive.exec.parallel = res;
Tako bo to povečalo izkoriščenost grozdov.
- Blokiranje vzorčenja: Vzorčenje podatkov iz tabele bo omogočilo raziskovanje poizvedb o podatkih.
Kljub sklepanju denarja želimo raje vzorčiti nabor podatkov bolj naključno. Vzorčenje blokov ima različne močne skladnje, kar pomaga pri vzorčenju podatkov na različne načine.
Za vzorčenje je mogoče uporabiti vzorčenje. informacije iz nabora podatkov, kot je povprečna razdalja med izvozi in namembnim krajem.
Poizvedba 1% velikih podatkov bo dala popoln odgovor. Raziskovanje postane lažje in učinkovitejše.
Zaključek - ukazi panja
Hive je abstrakcija višje stopnje na vrhu HDFS, ki omogoča prilagodljiv jezik poizvedb. Pomaga pri poizvedovanju in obdelavi podatkov na lažji način.
Panj se lahko namesti z drugimi velikimi podatkovnimi elementi, da v celoti izkoristi njegovo funkcionalnost.
Priporočeni članki
To je vodnik ukazov za panj. Tu smo razpravljali o osnovnih in naprednih ukazih panja ter nekaj neposrednih ukazov panja. Če želite izvedeti več, si oglejte tudi naslednji članek -
- Vprašanja za intervju
- Panj VS Hue - top 6 uporabnih primerjav
- Ukazi Tableau
- Ukazi Adobe Photoshop
- Uporaba ORDER BY Function v panju
- Prenesite in namestite panj korak za korakom