
Uvod v panjsko arhitekturo
Hive arhitektura je zgrajena na vrhu ekosistema Hadoop. Panj ima pogosto interakcije s Hadoopom. Apache Hive se spopade tako z domenskim sistemom baz podatkov SQL kot z zmanjšanjem zemljevidov. Vloge za panje se lahko pišejo v različnih jezikih, kot so Java, python. Arhitektura panj prikazuje, kako pisati panj jezik poizvedbe in kako se interakcije med programerjem izvajajo z vmesnikom ukazne vrstice. Poizvedbeni jezik panj opravi nalogo pretvorbe vseh skupin Hadoop grozda s pomočjo zmanjšanja zemljevidov. Kot smo vsi vedeli, je Hadoop obdeloval velike podatke v porazdeljenem okolju in tvoril okvir z odprto kodo. S panjem je prilagodljiv za upravljanje in izvajanje poizvedbe in dober podpornik za izvajanje funkcij, kot so enkapsulacija, ad-hoc poizvedbe. Ta članek ponuja kratek uvod v arhitekturo panjev, ki je na sloju Hadoop, za izvedbo povzetka velikih podatkov.
Arhitektura panj s svojimi sestavnimi deli
Hive ima pomembno vlogo pri analizi podatkov in integraciji poslovne inteligence in podpira oblike datotek, kot so besedilna datoteka, rc datoteka. Hive uporablja porazdeljen sistem za obdelavo in izvajanje poizvedb, shranjevanje pa se na koncu opravi na disku in na koncu obdela z uporabo okvira za zmanjšanje zemljevidov. Odpravlja težavo z optimizacijo, ki jo najdemo pri zmanjšanju zemljevidov in panju pri opravljanju paketnih opravil, ki so jasno razložena v delovnem toku. Tu meta shranjeva podatke o shemi. Okvir z imenom Apache Tez je zasnovan za izvajanje poizvedb v realnem času.
Spodaj so navedeni glavni sestavni deli panja:
- Stranke panj
- Storitve za panje
- Panj za shranjevanje (Meta skladiščenje)
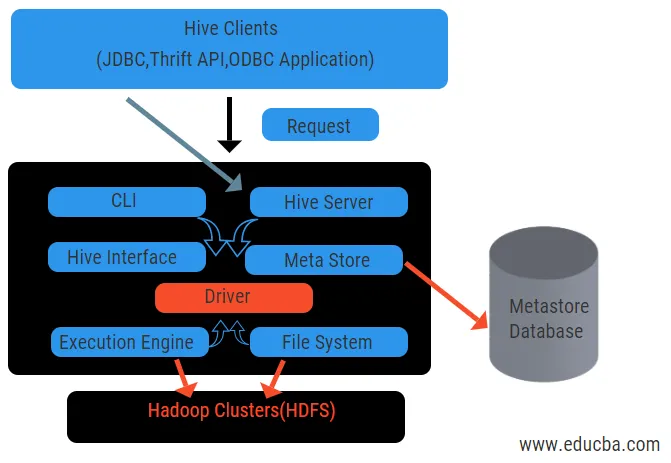
Zgornji diagram prikazuje arhitekturo panja in njegovih sestavnih elementov.
Stranke panj:
Vključujejo aplikacijo Thrift za izvajanje enostavnih ukazov panja, ki so na voljo za python, ruby, C ++ in gonilnike. Te odjemalske aplikacije koristijo za izvajanje poizvedb na panju. Hive ima tri vrste kategorizacije strank: varčne stranke, JDBC in ODBC odjemalci.
Storitve za panje:
Za obdelavo vseh poizvedb panj ima različne storitve. Uporabnik v panju enostavno določi vse funkcije. Oglejmo si vse te storitve na kratko:
- Vmesnik ukazne vrstice (uporabniški vmesnik): omogoča interakcijo med uporabnikom in panjem, privzeto lupino. Zagotavlja GUI za izvajanje ukazne vrstice panja in vpogled v panj. Za posredovanje poizvedb in interakcij s spletnim brskalnikom lahko uporabimo tudi spletne vmesnike (HWI).
- Voznik panja : Prejema poizvedbe iz različnih virov in odjemalcev, kot je varčevalni strežnik, shranjuje in pridobiva na gonilnikih ODBC in JDBC, ki sta samodejno povezana s panjem. Ta komponenta naredi semantično analizo gledanja tabel iz metastore, ki razčleni poizvedbo. Gonilnik pomaga s pomočjo prevajalnika in izvaja funkcije, kot so razčlenjevalec, načrtovalec, izvedba opravil MapReduce in optimizator.
- Prevajalnik: Razčlenjevalni in pomenski postopek poizvedbe opravi prevajalnik. Poizvedbo pretvori v abstraktno sintaksično drevo in spet nazaj v DAG za združljivost. Optimizator nato razdeli razpoložljive naloge. Naloga izvajalca je vodenje nalog in spremljanje časovnega razporeda nalog.
- Execution Engine: Vse poizvedbe obdela procesor. Fazo načrtov DAG izvaja motor in pomaga pri urejanju odvisnosti med razpoložljivimi stopnjami in jih izvaja na pravilni komponenti.
- Metastore: deluje kot osrednje skladišče za shranjevanje vseh strukturiranih informacij metapodatkov, prav tako je pomemben vidni del panja, saj ima informacije, kot so tabele in podrobnosti o particijah in shranjevanje datotek HDFS. Z drugimi besedami, rekli bomo, da metastore deluje kot imenik za tabele. Metastore velja za ločeno bazo podatkov, ki si jo delijo tudi druge komponente. Metastore ima dva dela, ki se imenuje servis in zaostanek.
Podatkovni model panja je strukturiran v predelne stene, vedra, tabele. Vse to je mogoče filtrirati, imeti predelne ključe in oceniti poizvedbo. Poizvedba o panju deluje na ogrodju Hadoop, ne na tradicionalni bazi podatkov. Panj strežnik je vmesnik med oddaljenimi poizvedbami odjemalca do panja. Izvršilni motor je popolnoma vgrajen v panj strežnik. Lahko najdete uporabo panj v strojnem učenju, poslovni inteligenci v postopku odkrivanja.
Delovni tok panja:
Panj deluje v dveh vrstah načinov: v interaktivnem načinu in v ne-interaktivnem načinu. Prejšnji način omogoča, da se vsi ukazi panja gredo neposredno v panjevo lupino, medtem ko kasnejši tip izvrši kodo v načinu konzole. Podatki so razdeljeni na particije, ki se nadalje razdelijo v vedra. Načrti izvajanja temeljijo na združevanju in nagnjenosti podatkov. Dodatna prednost uporabe panja je, da enostavno obdeluje obsežne podatke in ima več uporabniških vmesnikov.
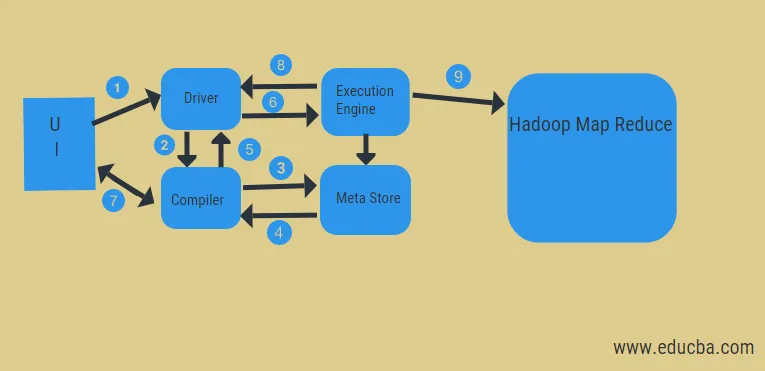
Iz zgornjega diagrama lahko pogledamo pretok podatkov v panj s sistemom Hadoop.
Ti koraki vključujejo:
- izvedite poizvedbo iz uporabniškega vmesnika
- pridobite načrt iz faz DAG voznikovih nalog
- prenesite zahtevo za metapodatke iz meta trgovine
- pošlji metapodatke iz prevajalnika
- vrnitev načrta vozniku
- Izvedite načrt v izvedbeni napravi
- pridobivanje rezultatov za ustrezno poizvedbo uporabnika
- dvosmerno pošiljanje rezultatov
- izvedba obdelave motorja v HDFS z zmanjšanjem zemljevidov in pridobitvijo rezultatov iz podatkovnih vozlišč, ki jih je ustvaril sledilnik opravil. deluje kot povezava med Hive in Hadoop.
Naloga izvršilnega mehanizma je komuniciranje z vozlišči za pridobivanje informacij, shranjenih v tabeli. Tu se za dostop do tabele izvajajo operacije SQL, kot so ustvarjanje, spuščanje, spreminjanje.
Zaključek:
Pregledali smo arhitekturo Hive in njihov delovni tok, panj v osnovi izvaja petabajtno količino podatkov in zato je paket skladiščenja podatkov na platformi Hadoop. Ker je panj dobra izbira za ravnanje z veliko količino podatkov, pomaga pri pripravi podatkov z vodnikom vmesnika SQL za reševanje težav MapReduce. Apache panj je orodje ETL za obdelavo strukturiranih podatkov. Poznavanje dela panj arhitekture podjetnikom pomaga razumeti princip delovanja panja in se dobro začne s programiranjem panjev.
Priporočeni članki:
To je vodnik za panjsko arhitekturo. Tukaj obravnavamo arhitekturo panja, različne sestavne dele in potek dela panja. si lahko ogledate tudi naslednje članke, če želite izvedeti več -
- Hadoop arhitektura
- Uporabe Ruby
- Kaj je C ++
- Kaj je MySQL Database
- Naročilo za panj