
Uvod v seznam ukazov Hadoop FS
Hadoop deluje na svojem lastnem datotečnem sistemu, ki je v naravi znan kot "HDFS razdeljen datotečni sistem Hadoop " . Hadoop se zanaša na porazdeljeno shranjevanje in vzporedno obdelavo. Ta način shranjevanja datoteke na porazdeljenih lokacijah v grozdu je znan kot Hadoop porazdeljeni datotečni sistem, tj HDFS. Za izvajanje različnih operacij na ravni datotek HDFS ponuja lasten nabor ukazov, znan kot Hadoop datotečni sistemski ukazi. Raziščimo te ukaze. V tej temi bomo spoznali Hadoop FS Command.
Ukazi Hadoop FS
Vsak ukaz HDFS ima predpono "hdfs dfs". To pomeni, da določamo, da je privzeti datotečni sistem HDFS. Raziskujmo ukaze drug za drugim
1. Različice
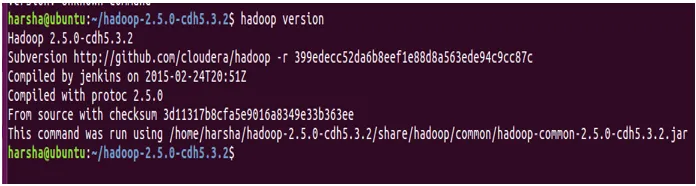
Ukaz različice se uporablja za iskanje različice Hadoopa, nameščene v sistemu.
Sintaksa: Hadoop version
2. je ukaz
Ukaz ls v Hadoopu se uporablja za določitev seznama imenikov na omenjeni poti. Ukaz ls vzame pot parametra hdfs in vrne seznam imenikov, prisotnih na poti.
Sintaksa: hdfs dfs -ls
Primer: hdfs dfs -ls / user / harsha

Za rekurzivni način lahko uporabimo tudi -lsr
Sintaksa: hdfs dfs –lsr
3. Mačji ukaz
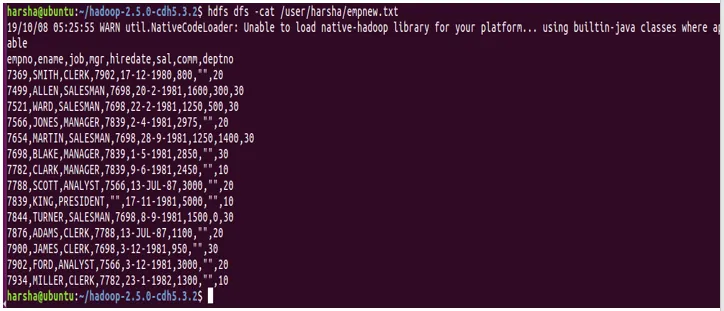
Ukaz Cat se uporablja za prikaz vsebine datoteke na konzoli. Ta ukaz vzame pot datoteke hdfs kot argument in prikaže vsebino datoteke.
Sintaksa: hdfs dfs -cat
Primer: hdfs dfs -cat /user/harsha/empnew.txt
4. ukaz mkdir
Ukaz mkdir se uporablja za ustvarjanje novega imenika v datotečnem sistemu hdfs. Pot hdfs sprejme kot argument in ustvari nov imenik v podani poti.
Sintaksa: hdfs dfs -mkdir
Primer: hdfs dfs -mkdir / user / example
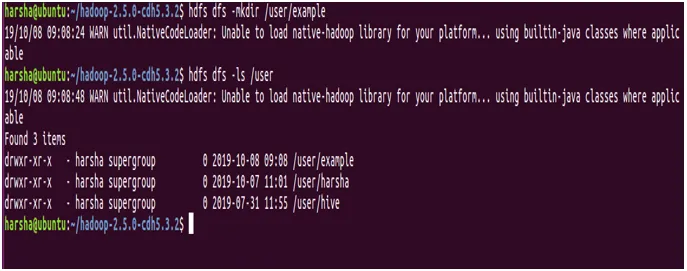
Na zgornjem zaslonu je jasno razvidno, da z ukazom mkdir ustvarjamo nov imenik z imenom "primer" in isto je prikazano z ukazom ls.
Tudi za ukaz mkdir lahko damo možnost '-p'. Če ustvari nadrejene imenike na poti, ustvari na poti.
Primer: hdfs dfs -mkdir -p / user / test / example2
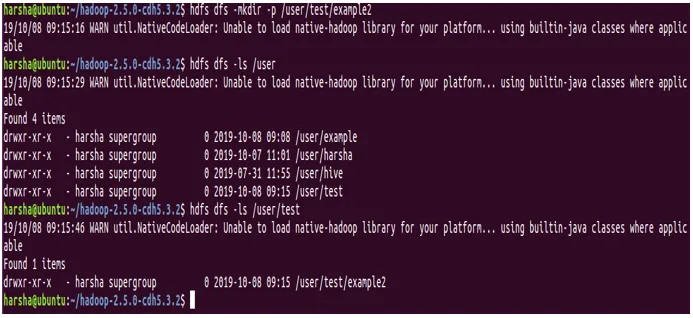
Na zgornjem posnetku zaslona je očitno, da imamo možnost -p in v poti / uporabnik / test / example2 ustvarimo tako teste kot tudi imenike example2.
5. daj ukaz
daj ukaz v HDFS se uporablja za kopiranje datotek z podanega izvornega mesta na ciljno pot hdfs. Tukaj je izvorna lokacija lahko pot do lokalnega datotečnega sistema. ukaz ima dva argumenta, prvi je izvorni imenik, drugi pa ciljno pot HDFS
Sintaksa: hdfs dfs -put
Primer: hdfs dfs -put /home/harsha/empnew.txt / user / test / example2
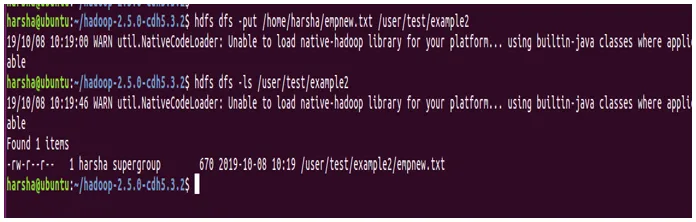
Na zgornjem posnetku zaslona lahko jasno vidimo, da je datoteka kopirana od vira do cilja.
6. ukaz copyFromLocal
Ukaz copyFromLocal v HDFS se uporablja za kopiranje datotek iz izvorne poti do ciljne poti. Vir v tem ukazu je omejen na lokalni datotečni sistem
Sintaksa: hdfs dfs -copyFromLocal /home/harsha/empnew.txt/user/harsha/example

Razlika med ukazom put in copyFromLocal ukazom: Ta dva ukaza lupine hdfs nima veliko razlike. Obe se uporabljata za kopiranje iz lokalnega datotečnega sistema za ciljanje na pot datoteke HDFS.
Toda ukaz put je bolj uporaben in trden, saj omogoča kopiranje več datotek ali imenikov v namembni HDFS
hdfs dfs-vhod
7. dobili ukaz
ukaz ukaz v hdfs se uporablja za kopiranje dane datoteke ali imenika hdfs na ciljno pot lokalnega datotečnega sistema. Vzame dva argumenta, eden je izvor hdfs poti, drugi pa ciljna pot lokalnega datotečnega sistema
Sintaksa: hdfs dfs -get
Primer: hdfs dfs -get / user / test / example2 / home / harsha
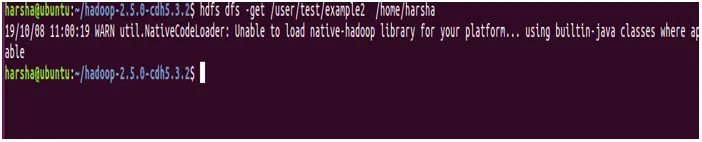
8. ukaz copyToLocal
Ukaz copyToLocal v hdfs se uporablja za kopiranje datoteke ali imenika v hdfs v lokalni datotečni sistem. V tem ukazu je cilj določen v lokalnem datotečnem sistemu. Ta ukaz copyFromLocal je podoben ukazu get.
Sintaksa: hdfs dfs -copyToLocal
Primer: hdfs dfs -copyToLocal / uporabnik / harsha / example / home / harsha
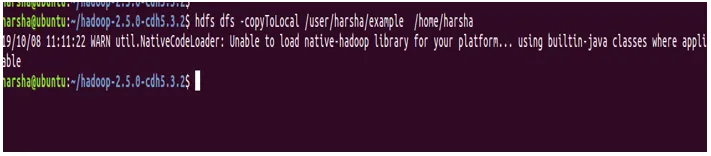
9. ukaz šteje
Ukaz count v hdfs se uporablja za štetje števila imenikov, ki so prisotni na dani poti. Ukaz count vzame določeno pot kot argument in poda število imenikov, prisotnih na tej poti.
Sintaksa: hdfs dfs -count
Primer: hdfs dfs -count / user

10. ukaz mv
Ukaz mv v hdfs se uporablja za premikanje datoteke med hdfs. mv ukaz vzame datoteko ali imenik iz podane izvorne poti hdfs in jo premakne na ciljno pot hdfs.
Sintaksa : hdfs dfs -mv
Primer : hdfs dfs -mv / user / test / example2 / user / harsha
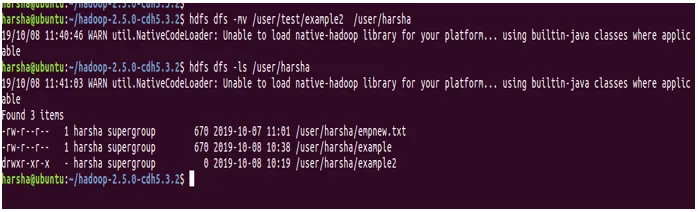
Na zgornjem zaslonu lahko vidimo, da je imenik example2 zdaj prisoten v / user / harsha
11. ukaz setrep
Ukaz setrep v hdfs se uporablja za spreminjanje faktorja podvajanja dane datoteke. Privzeto ima hdfs faktor podvajanja '3'. Če je podana pot imenik, bo ta ukaz spremenil faktor podvajanja vseh datotek v tem imeniku.
Sintaksa: hdfs dfs -setrep (-R) (-w)
-w: Ta zastavica določa, da mora ukaz počakati, da se podvajanje konča.
rep: faktor podvajanja
Primer: hdfs dfs -setrep -w 5 /user/harsha/empnew.txt
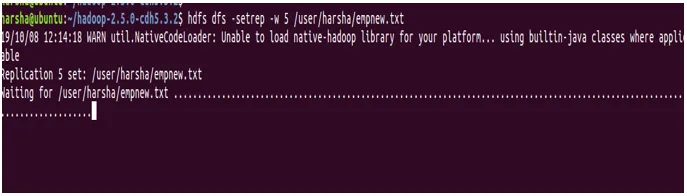
12. ukaz du
ukaz du v hdfs prikazuje uporabo diska za dano pot hdfs. Pot hdfs prevzame kot vhod in vrne uporabo diska v bajtih.
Sintaksa : hdfs dfs -du
Primer: hdfs dfs -du /user/harsha/empnew.txt
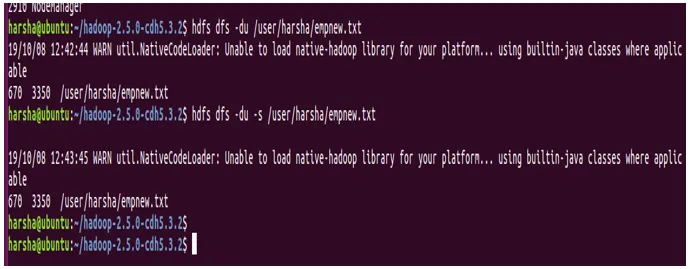
13. ukaz rm
Ukaz rm v hdfs se uporablja za odstranjevanje datotek ali imenikov na dani poti hdfs. Ta ukaz sprejme pot hdfs kot vhod in odstrani datoteke, ki so na tej poti.
Sintaksa : hdfs dfs -rm
Primer : hdfs dfs -rm / user / harsha / example
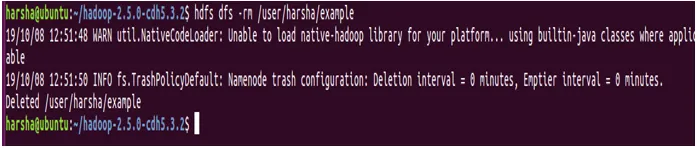
Zaključek - Hadoop FS poveljstvo
S tem smo spoznali različne ukaze hdfs in njihove skladnje s primeri. Priporočamo, da začnemo vse ukaze hdfs, zaženimo skript bin / hdfs. hdfs sledi možnost, znana kot dfs, kar pomeni, da delamo s sistemom datotek Hadoop s porazdeljenim sistemom. S pomočjo zgoraj omenjenih ukazov se lahko dogovarjamo z datotečnim sistemom HDFS.
Priporočeni članki
To je vodnik za Hadoop FS Command. Tukaj obravnavamo najpogosteje uporabljene ukaze HDFS. Če želite izvedeti več, si oglejte tudi naslednji članek -
- Hadoop arhitektura
- Okvir HADOOP
- Namestite Hadoop
- Orodja Hadoop
- Različice Tableau
- Vodnik po seznamu ukazov školjke Unix