

Razlike med Sqoop in Flume
Sqoop je izdelek iz programske opreme Apache. Sqoop pridobi Hadoop koristne informacije in nato preide v zunanje shrambe podatkov. S pomočjo Sqoopa lahko v HDFS uvozimo podatke iz RDBMS ali mainframe. Flume je tudi iz programske opreme Apache. Zbira in premika rekurzivne podatke, ki se ustvarjajo. Apache Flume ni omejen samo na zbiranje dnevnikov podatkov, ampak so tudi viri podatkov prilagodljivi, zato lahko Flume uporabljamo za prevoz ogromnih količin podatkov. Najboljši način zbiranja, združevanja in premikanja velikih količin podatkov med distribuiranim datotečnim sistemom Hadoop in RDBMS je z uporabo orodij, kot sta Sqoop ali Flume.
Pogovorimo se o teh dveh pogosto uporabljenih orodjih za zgoraj omenjeni namen.
Kaj je Sqoop
Za uporabo Sqoop mora uporabnik določiti orodje, ki ga želi uporabiti orodje, in argumente, ki nadzorujejo določeno orodje. Podatke lahko nato tudi izvozite nazaj v RDBMS s pomočjo Sqoop. Izvozna funkcionalnost Sqoopa se uporablja za pridobivanje koristnih informacij iz Hadoopa in njihovo izvoz v zunanje strukturirane shrambe podatkov. Deluje z različnimi zbirkami podatkov, kot so Teradata, MySQL, Oracle, HSQLDB.
- Sqoop arhitektura: -
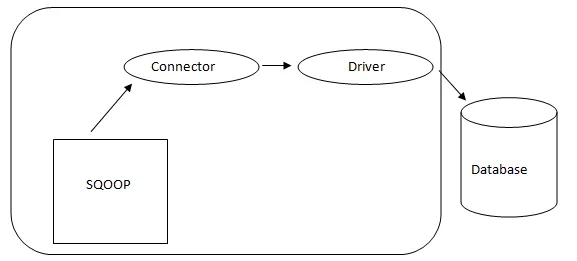
Arhitektura Sqoopa
Priključek v Sqoopu je vtičnik za določen vir podatkovne baze, zato je bistvenega pomena, da je del vzpostavitve Sqoop. Kljub dejstvu, da so gonilniki specifični za baze podatkov in jih distribuirajo različni prodajalci baz podatkov, Sqoop prihaja v paketu z različnimi vrstami priključkov, ki se uporabljajo za razširjen sistem za shranjevanje baz podatkov in informacij. Tako Sqoop tudi iz škatle pošilja različne mešanice priključkov. Sqoop ponuja vtično komponento za idealno omrežje in zunanji sistem. API Sqoop daje koristno strukturo za sestavljanje novih konektorjev, zato lahko vse konektorje baze podatkov spustite v namestitev Sqoop in tako omogočite povezljivost z različnimi podatkovnimi sistemi.
Kaj je Flume
Apache Flume ni omejen samo na zbiranje podatkov, ampak so tudi viri podatkov prilagodljivi, zato lahko Flume uporabljamo za prenos ogromnih količin podatkov, vključno z e-poštnimi sporočili, podatki, ustvarjeni na družbenih medijih, podatki o omrežnem prometu in podobno. možen vir podatkov.
Arhitektura floma: - Arhitektura floma temelji na večjedrnih konceptih:
- Flume Event - predstavljena je kot enota pretoka podatkov, ki ima bajt koristno in niz nizov z dodatnimi glavami nizov. Flume meni, da je dogodek le splošna bajta.
- Flume Agent - To je postopek JVM, ki gosti komponente, kot so kanali, umivalnik in viri. Ima možnost sprejemanja, shranjevanja in posredovanja dogodkov iz zunanjega vira na naslednjo raven.
- Flume Flow - to je čas, ko se dogodek generira.
- Flume Client - nanaša se na vmesnik, kjer odjemalec deluje na izvornem mestu dogodka in ga dostavi agentu Flume.
- Vir - Vir je tisti, ki porabi dogodke v določeni obliki in jih posreduje prek posebnega mehanizma.
- Kanal - Gre za pasivno trgovino, kjer se odvijajo dogodki, dokler jih umivalnik ne odstrani za nadaljnji prevoz.
- Pomivalno korito - dogodek odstrani iz kanala in ga postavi v zunanje skladišče, kot je HDFS. Trenutno podpira ustvarjanje besedilnih in zaporednih datotek ter podpira stiskanje v obeh vrstah datotek.
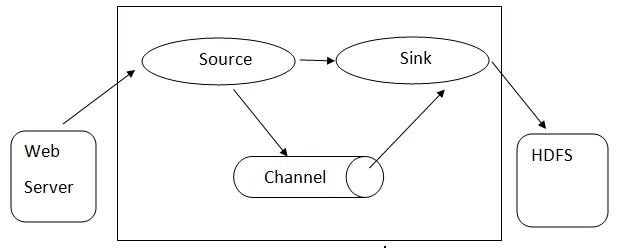
Arhitektura Flume
Primerjava med proizvajalci Sqoop in Flume (Infographics)
Spodaj je zgornja 7 primerjava med Sqoop proti Flume

Ključne razlike med Sqoop proti Flume
Zdaj vemo, da obstaja veliko razlik med Sqoopom in Flume, tukaj so najpomembnejše razlike med njimi -
1. Sqoop je zasnovan za izmenjavo množičnih informacij med Hadoop in Relacijsko bazo podatkov.
Ker se Flume uporablja za zbiranje podatkov iz različnih virov, ki ustvarjajo podatke o določenem primeru uporabe, in nato to veliko količino podatkov iz razpršenih virov prenese v eno samo centralno skladišče.
2. Sqoop vključuje tudi nabor ukazov, ki omogoča vpogled v bazo podatkov, s katero delate. Tako lahko Sqoop obravnavamo kot zbirko povezanih orodij.
Medtem ko zbirate datum, Flume podatke vodoravno spreminja, za zbiranje datuma in združevanje pa jih lahko sproži več agentov Flume. Nato se dnevniki podatkov premaknejo v centralizirano shrambo podatkov, tj. Hadoop Distributed File System (HDFS).
3. Ključni dejavnik za uporabo Flume je, da morajo biti podatki ustvarjeni neprekinjeno in pretočno. Podobno je Sqoop najbolj primeren v situacijah, ko vaši podatki živijo v sistemih baz podatkov, kot so MySQL, Oracle, Teradata, PostgreSQL
Sqoop vs Flume (primerjalna tabela)
| Osnove za primerjavo | SQOOP | FLUME |
|
Osnovna narava | Sqoop dobro sodeluje z vsemi RDBMS, ki imajo JDBC (Java Database Connectivity), kot so Oracle, MySQL, Teradata itd. | Flume deluje dobro za vir podatkov Streaming, ki nenehno ustvarja, kot so dnevniki, JMS, imenik, poročila o zrušitvah itd. |
| Pretok podatkov | Sqoop, ki se uporablja posebej za vzporedni prenos podatkov. Iz tega razloga je lahko izhod v več datotekah | Flume se uporablja za zbiranje in združevanje podatkov zaradi svoje razporejene narave. |
| Potovalni dogodki | Sqoop ne poganjajo dogodki. | Flume je popolnoma usmerjen v dogajanje. |
| Arhitektura | Sqoop sledi arhitekturi, ki temelji na konektorju, kar pomeni, da konektorji vedo, kako se povezati z drugim virom podatkov. | Flume sledi arhitekturi na osnovi agentov, kjer je v njem zapisana koda znana kot sredstvo, ki je odgovorno za pridobivanje podatkov. |
| Kje uporabiti | Primarno se uporablja za hitrejše kopiranje podatkov in nato za njihovo ustvarjanje analitičnih rezultatov. | Običajno se uporabljajo za črpanje podatkov, kadar podjetja želijo analizirati vzorce, vzroke ali analizo občutkov z uporabo dnevnikov in socialnih medijev. |
| Izvedba | Zmanjša prekomerno obremenitev in skladiščenje, tako da jih prenese v druge sisteme in ima hitro delovanje. | Flume je odporen na napake, robusten in ima zanesljiv mehanizem zanesljivosti za preklop in obnovo. |
| Zgodovina izdaj | Prva različica Apache Sqoop je bila predstavljena marca 2012. Trenutna stabilna različica je 1.4.7 | Prva stabilna različica 1.2.0 Apache Flume je bila predstavljena junija 2012. Trenutno stabilna izdaja je Apache Flume različice 1.8.0. |
Zaključek - Sqoop proti Flume
Kot smo izvedeli zgoraj Sqoop in Flume, sta predvsem dve orodji za zaužitje podatkov uporabljeni svet velikih podatkov. Če morate v Hadoop / HDFS zaužiti besedilne podatke dnevnika, potem je Flume prava izbira za to. Če vaši podatki ne bodo redno ustvarjeni, potem bo Flume še vedno deloval, vendar bo to presežek za to situacijo. Podobno Sqoop ni najbolj primeren za obdelavo podatkov, ki temelji na dogodkih.
Priporočeni članki
To je vodnik za razlike med Sqoop-om in Flumeom, njihovim pomenom, primerjavo med seboj, ključnimi razlikami, primerjalno tabelo in sklepom. Ta članek vsebuje vse uporabne razlike med Sqoop in Flume. Če želite izvedeti več, si oglejte tudi naslednje članke
- Hadoop vs Teradata - uporabne razlike za učenje
- 5 Najpomembnejša razlika med Apache Kafka proti Flume
- Big Data v primerjavi z Apache Hadoop - top 4 primerjave, ki se jih morate naučiti
- 5 Najpomembnejša razlika med Apache Kafka proti Flume
- Pomembno branje besedil v primerjavi z obdelavo naravnega jezika - top 5 primerjav