

Pregled aplikacij Kafka
Eno od trendnih področij v IT industriji je Big Data, kjer se podjetje ukvarja z veliko količino podatkov o strankah in pridobiva koristne vpoglede, ki pomagajo njihovemu poslovanju in strankam zagotavljajo boljše storitve. Eden od izzivov je ravnanje in prenos teh velikih količin podatkov z enega konca na drugega za analizo ali obdelavo. Tu nastopi Kafka (zanesljiv sistem za sporočanje), ki pomaga pri zbiranju in prenašanju ogromne količine podatkov v realnem času. Kafka je zasnovan za porazdeljene sisteme z visokim pretokom in je primeren za obsežne aplikacije za obdelavo sporočil. Kafka podpira številne današnje najboljše komercialne in industrijske aplikacije. Za Kafke strokovnjake obstaja veliko povpraševanja in praktičnih znanj.
V tem članku bomo spoznali Kafko, njene značilnosti, primere uporabe in razumeli nekatere pomembne aplikacije, kjer se uporablja.
Kaj je zdravilo Kafka?
Apache Kafka je bil razvit na LinkedInu in je kasneje postal odprtokodni projekt Apache. Apache Kafka je hiter, napak odporen, razširljiv in porazdeljen sistem sporočanja, ki omogoča komunikacijo med dvema subjektoma, torej med proizvajalci (generator sporočila) in potrošniki (prejemnik sporočila) z uporabo tematik, ki temeljijo na sporočilih, in ponuja platformo za upravljanje vseh vire v realnem času.
Značilnosti, zaradi katerih je Apache Kafka boljši od drugih sistemov za sporočanje in uporaben za sisteme v realnem času, je njegova visoka razpoložljivost, takojšnje samodejno okrevanje po okvarah vozlišča in podpora sporočilu z nizko zamudo. Te značilnosti Apache Kafke pomagajo pri njenem vključevanju v obsežne podatkovne sisteme in je idealen sestavni del za komunikacijo. 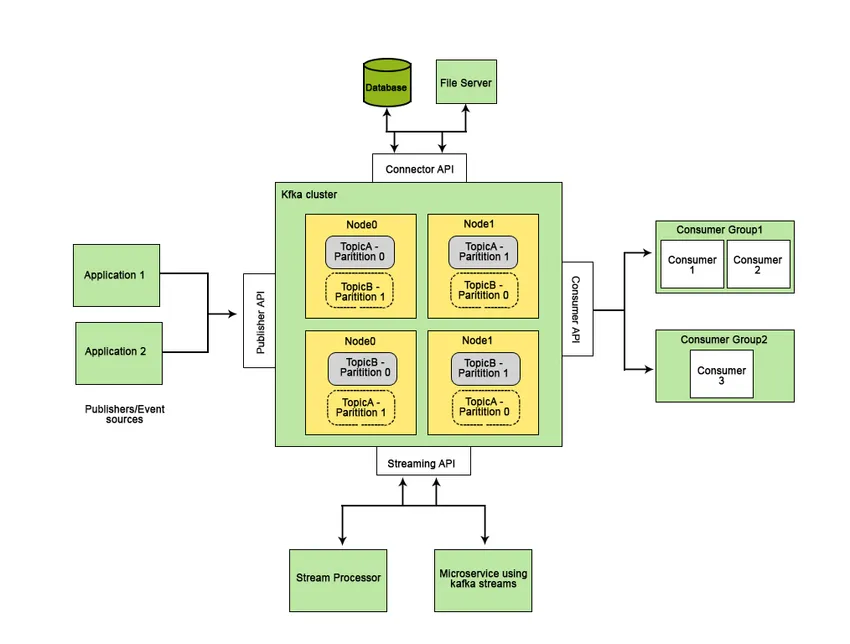
Najboljše aplikacije Kafka
V tem delu članka bomo videli nekaj priljubljenih in široko implementiranih primerov uporabe ter videli nekaj resničnega izvajanja Kafke.
Aplikacije v resničnem življenju
1. Twitter: Dejavnost obdelave toka
Twitter je družabna omrežna platforma, ki uporablja Storm-Kafka (odprtokodno orodje za obdelavo tokov) kot del svoje infrastrukture za obdelavo tokov, kjer se vhodni podatki (tweeti) porabijo za združevanje, preoblikovanje in obogatitev za nadaljnjo porabo ali nadaljnje spremljanje predelovalne dejavnosti.
2. LinkedIn: Obdelava tokov in meritve
LinkedIn uporablja Kafko za pretakanje podatkov in za operativne meritve. LinkedIn uporablja Kafko za svoje dodatne funkcije, kot je Newsfeed za porabo sporočil in izvajanje analiz na prejetih podatkih.
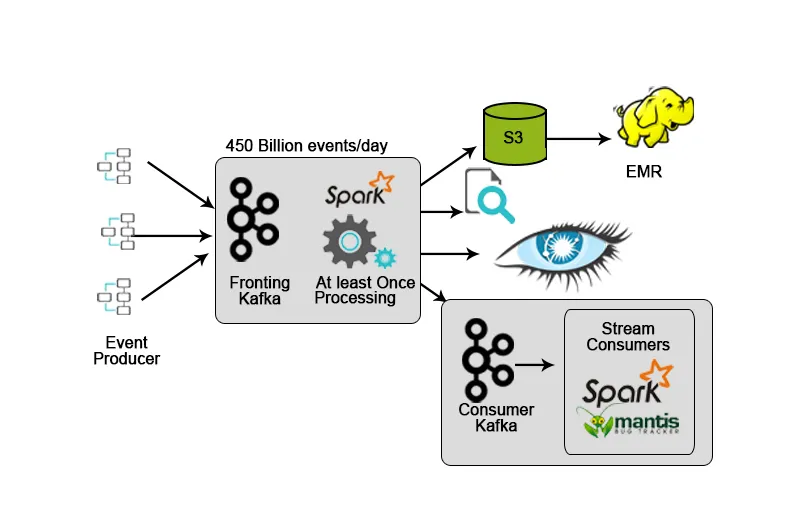
3. Netflix: Spremljanje v realnem času in obdelava tokov
Netflix ima lasten okvir za zaužitje, ki odlaga vhodne podatke v AWS S3 in uporablja Hadoop za izvajanje analitike video tokov, dejavnosti uporabniškega vmesnika, dogodkov za izboljšanje uporabniške izkušnje in Kafka za zajem podatkov v realnem času prek API-jev.
4. Hotstar: Obdelava toka
Hotstar je predstavil lastno platformo za upravljanje podatkov - Bifrost, kjer Kafka uporablja za pretakanje podatkov, spremljanje in sledenje ciljem. Kafka je bila zaradi svoje razširljivosti, razpoložljivosti in zmogljivosti z nizko zamudo idealna izbira za obdelavo podatkov, ki jih platforma hotstar ustvarja vsakodnevno ali ob kakršni koli posebni priložnosti (v živo na kakršnih koli koncertih ali kakršnih koli športnih tekmah v živo itd.), Kjer količina podatkov se znatno poveča.
Apache Kafka večino časa uporablja kot gradnik za razvoj arhitekture pretočnih podatkov. Ta vrsta arhitekture se uporablja v aplikacijah, kot so zbiranje dnevnikov izdelkov / strežnikov, analiza klikovnega toka in pridobivanje informacij iz računalniško ustvarjenih podatkov.
Toda skupaj s Kafko moramo uporabiti dodatna sredstva ali orodja za pretvorbo pridobljenega podatkovnega toka v smiselne podatke, ki pomagajo pri vpogledu, ki jih je mogoče uporabiti pri odločitvah, ki temeljijo na podatkih. Na primer, morda bomo morali v realnem času ustvariti vpogled iz neobdelanih podatkov, pridobljenih z napravami IoT ali podatkov, pridobljenih s platform družbenih medijev, in opraviti neko analizo ali obdelavo ter jo predstaviti podjetju, da sprejme boljše odločitve ali jim pomaga izboljšati izvajanje njihovih storitev.
Za tovrstne primere uporabe želimo svoje vhodne podatke / neobdelane podatke pretočiti v podatkovno jezero, kjer lahko shranimo svoje podatke in zagotovimo kakovost podatkov, ne da bi ovirali njihovo delovanje.
Drugačna situacija je, da lahko beremo podatke neposredno iz Kafke, kadar potrebujemo izredno nizko zamudo, kot je na primer podajanje podatkov v programe v realnem času.
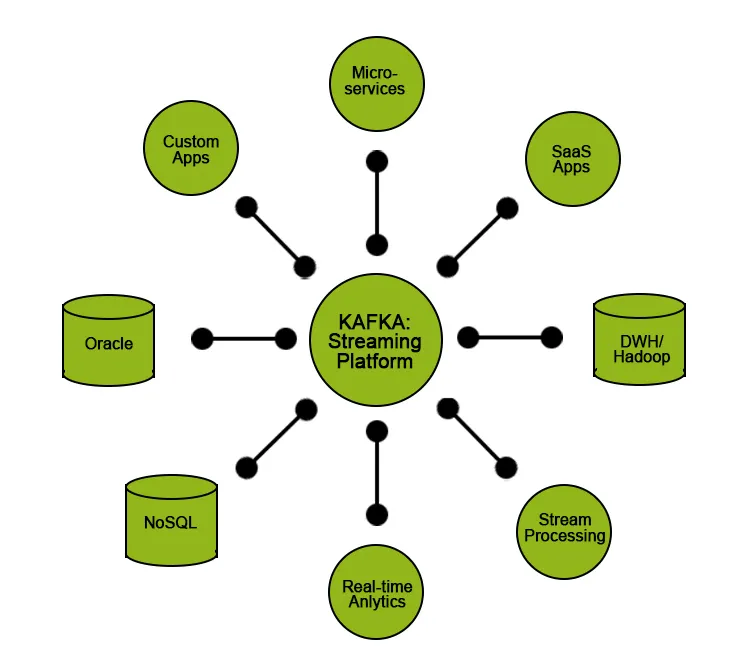
Kafka svojim uporabnikom zagotavlja nekatere funkcionalnosti:
- Objavite in naročite podatke.
- Podatke shranite v vrstnem redu, ko so bili ustvarjeni učinkovito.
- Obdelava podatkov v realnem času / na poti.
Kafka večino časa uporablja za:
- Izvedba podatkovnih cevovodov za pretok podatkov, ki zanesljivo dobivajo podatke med dvema osebama v sistemu.
- Izvajanje aplikacij za pretok v toku, ki preoblikujejo ali manipulirajo ali obdelujejo tokove podatkov.
Uporabite primere
Spodaj je nekaj široko uporabljenih primerov uporabe Kafke:
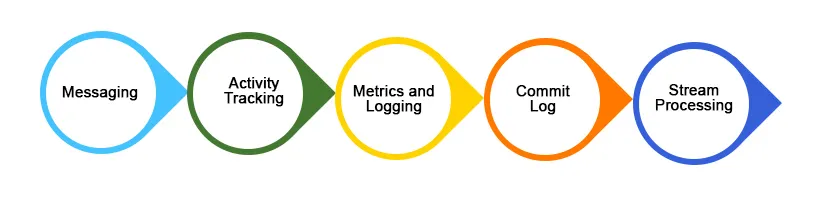
1. Sporočanje
Kafka deluje bolje od drugih tradicionalnih sistemov za sporočanje, kot so ActiveMQ, RabbitMQ, itd. V primerjavi s tem ponuja Kafka boljši pretok, vgrajeno pregradno zmogljivost, podvajanje in napak, zaradi česar je boljši sistem za sporočanje za obsežne aplikacije za obdelavo .
2. Sledenje dejavnosti spletnega mesta
Uporabniške dejavnosti (ogledi strani, iskanja ali kakršna koli izvedena dejanja) lahko prek Kafke spremljate in jih hranite za spremljanje ali analizo v realnem času ali uporabite Kafka za shranjevanje teh vrst podatkov v Hadoop ali skladišče podatkov za kasnejšo obdelavo ali manipulacijo. S sledenjem dejavnosti nastane ogromna količina podatkov, ki jih je treba prenesti na želeno lokacijo brez kakršne koli izgube podatkov.
3. Združevanje dnevnika
Združevanje dnevnikov je postopek zbiranja / združevanja fizičnih datotek dnevnika z različnih strežnikov aplikacije v eno samo repozitorij (datotečni strežnik ali HDFS) za obdelavo. Kafka ponuja dobre zmogljivosti, nižje zamude pri koncu v primerjavi s Flumeom.

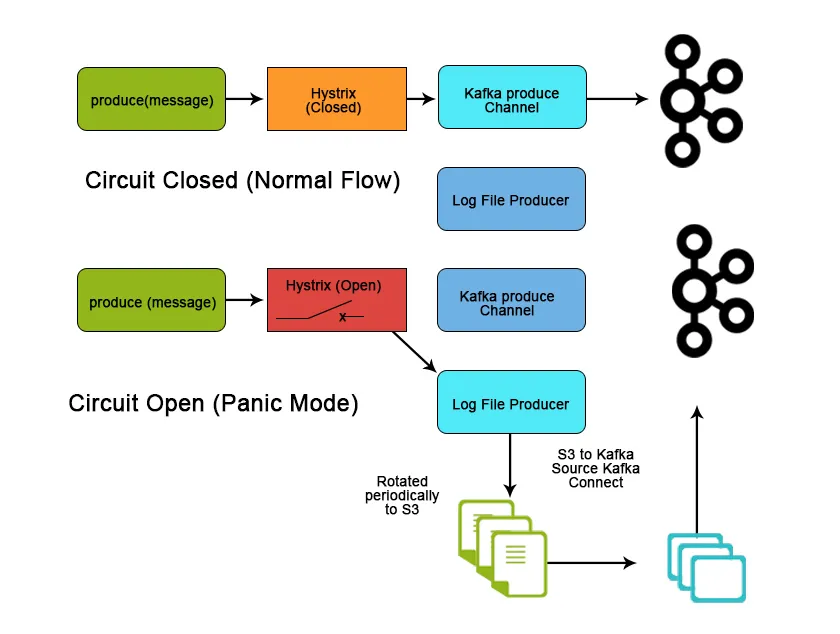
Zaključek
Kafka se v velikem podatkovnem prostoru veliko uporablja kot način za zaužitje in premikanje velike količine podatkov zaradi svojih lastnosti in lastnosti, ki pomagajo doseči razširljivost, zanesljivost in trajnost. V tem članku smo razpravljali o Apache Kafki o njenih značilnostih, primerih uporabe in uporabi ter o tem, kaj je boljše orodje za pretakanje podatkov.
Priporočeni članki
To je vodnik za Kafka aplikacije. Tukaj razpravljamo o tem, kaj je Kafka skupaj z vrhunskimi aplikacijami Kafke, ki vključujejo široko implementirane primere uporabe in nekatere izvedbe v resničnem življenju. Če želite izvedeti več, si oglejte tudi naslednje članke -
- Kaj je zdravilo Kafka?
- Kako namestiti Kafko?
- Kafka Intervju Vprašanja
- Apache Kafka proti Flume
- 8 najboljših naprav IoT, ki jih morate vedeti
- Kafka proti Kinesis | Razlike z Infografiko
- Različne vrste orodij Kafka s komponentami
- Spoznajte najboljše razlike med ActiveMQ in Kafka