
Razlika med Hive in HBase
Apache Hive in HBase sta tehnologiji velikih podatkov na osnovi Hadoop-a. Oba sta iskala podatke. Panj in HBase delujeta na vrhu Hadoopa in se razlikujeta v svoji funkcionalnosti. Hive je SQL narečje, ki temelji na zmanjšanju zemljevidov, medtem ko HBase podpira samo MapReduce. HBase shranjuje podatke v obliki parov ključ / vrednost ali družino stolpcev, medtem ko Hive ne shranjuje podatkov.
Razlike med Hive proti HBase (Infographics)
Spodaj je zgornjih 8 razlik med Hive proti HBase
Ključne razlike med Hive proti HBase
- Hbase je združljiv s kislinami, medtem ko panj ni.
- Hive podpira kriterije particioniranja in filtriranja glede na obliko datuma, medtem ko HBase podpira avtomatizirano particijo.
- Hive ne podpira izjav o posodobitvi, medtem ko jih HBase podpira.
- Hbase je hitrejši v primerjavi s Hivem pri pridobivanju podatkov.
- Hive se uporablja za obdelavo strukturiranih podatkov, medtem ko HBase, ker je brez sheme, lahko obdeluje katero koli vrsto podatkov.
- Hbase je v primerjavi s panjom zelo (vodoravno) razširljiv.
- Hive analizira podatke na HDFS s podporo SQL poizvedb in jih nato pretvori v zemljevid in zmanjša delovna mesta, medtem ko v Hbase, ker je v realnem času, neposredno izvaja svoje operacije na bazi podatkov s particijo na tabele in družine stolpcev.
- Ko pri iskanju podatkov panj uporablja lupino, imenovano lupina Hive, da izda ukaze, medtem ko HBase, ker je baza podatkov, bomo uporabili ukaz za obdelavo podatkov v HBase.
- Za odhod do lupine Pive bomo uporabili ukazni panj. Po tem bo videti kot panj>. V HBaseu preprosto damo kot Use HBase.
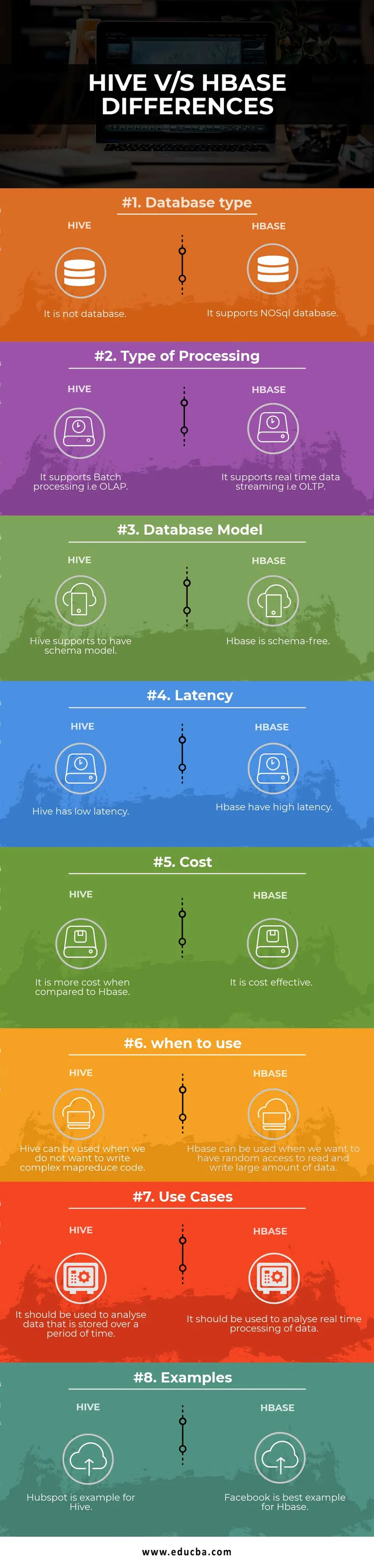
Tabela primerjave med panj in HBase
| Osnove za primerjavo | Panj | Hbase |
| Vrsta baze podatkov | To ni baza podatkov | Podpira bazo podatkov NoSQL |
| Vrsta obdelave | Podpira paketno obdelavo, tj. OLAP | Podpira pretok podatkov v realnem času, tj. OLTP |
| Model baze podatkov | Panj podpira, da ima model sheme | Hbase ni shema |
| Zamuda | Panj ima nizko zamudo | Hbase ima veliko zakasnitev |
| Cena | V primerjavi z HBase je dražje | Je stroškovno učinkovit |
| kdaj uporabiti | Panj lahko uporabljamo, kadar ne želimo napisati zapletene kode MapReduce | HBase lahko uporabimo, kadar želimo imeti naključen dostop za branje in zapisovanje velike količine podatkov |
| Uporabite primere | Uporabljati ga je treba za analizo podatkov, ki so shranjeni v določenem časovnem obdobju | Uporabiti bi ga bilo treba za analizo obdelave podatkov v realnem času. |
| Primeri | Hubspot je primer za Hive | Facebook je najboljši primer za Hbase |
Razlike v kodiranju med Hive proti HBase
Zdaj se pogovorimo o osnovnih razlikah med Hive in HBase pri kodiranju.
| Osnove za primerjavo | Panj | Hbase |
| Za ustvarjanje baze podatkov | USTVARJANJE PODATKOV (ČE NE OBSTOJI) PODATKOVNI IME; | Ker je Hbase baza podatkov, nam ni treba ustvariti posebne baze podatkov |
| Izpustitev baze podatkov | DATABASA DROP (ČE OBSTOJI) PODATKOVNO IME (OMEJITEV ALI KASICADA); | NA |
| Ustvari tabelo | USTVARJITE (ZAČASNO ALI ZUNANJE) TABELO (ČE NE OBSTOJI) TABELNO IME ((ime-imena stolpca (vrsta komentarja-komentar stolpca), ….)) (komentar tabele_ komentar) (ROW FORMAT-format vrstice) (Shranjeno kot oblika datoteke) | USTVARJAM '', '' |
| Spreminjanje tabele | ALTER TABLE name PRENIŠI NA novo ime
ALTER TABLE ime DROP (COLUMN) ime stolpca ALTER TABLE ime DODAJTE STOLPCI (col-spec (, col-spec ..)) ALTER TABLE ime SPREMENI ime stolpca novo ime novo tip SPLOŠNO ime TABELE ZAMENITE STROKOVE (col-spec (, col-spec ..)) | ALTER 'TABLE-NAME', NAME => 'COLUMN-NAME', VERSIONS => |
| Onemogočanje tabele | NA | onemogoči 'TABLE-NAME' ->, da onemogoči določeno ime tabele
onesposobiti vse tabele, ki se ujemajo z običajnim izrazom |
| Omogočanje tabele | NA | omogoči »TABLE-NAME« |
| Če želite spustiti tabelo | DROP TABLE, ČE OBSTOJI ime tabele | Če želimo spustiti tabelo, jo moramo najprej onemogočiti
onemogoči 'ime-tabele' drop 'ime tabele' Podobno lahko uporabimo invalid_all in drop_all za brisanje tabel, ki ustrezajo določenemu pravilnemu izrazu. |
| Za seznam baz podatkov | prikaži baze podatkov; | NA |
| Če želite prikazati tabele v zbirki podatkov | prikažite tabele; | seznam |
| Za opis sheme tabele | opišite ime tabele; | opišite „ime tabele“ |
Vključevanje Hive proti HBase
- Namestite in konfigurirajte Hive.
- Namestite in konfigurirajte HBase.
- Za integracijo Hive in HBase v Pive uporabljamo SKLADIŠČENE VOZIČKE
- Storage Handlers je kombinacija SERDE, InputFormat, OutputFormat, ki sprejema katero koli zunanjo entiteto kot tabelo v Hive.
- Tako ta funkcija uporabniku pomaga pri izdaji poizvedb SQL, naj bo tabela v Hadoopu ali v bazi podatkov, ki temelji na NOSQL, kot so HBase, MongoDB, Cassandra, Amazon DynamoDB.
- Zdaj si bomo ogledali en primer povezovanja Hive s HBase s pomočjo HiveStorageHandler:
- Najprej moramo z ukazom izdelati tabelo Hbase.
ustvarite 'Študent', 'osebne informacije', 'odstranjevanje informacij'
-> Osebni podatki in podatki o oddelku ustvarijo dve različni družini stolpcev v tabeli Študent.
- Nekaj podatkov moramo vstaviti v tabelo Študent. Na primer, kot je navedeno spodaj.
vstaviti 'študent', 'sid01', 'osebne informacije: ime', 'Ram'
dal 'študent', 'sid01', 'osebne informacije: mailid', ' '
dal 'študent', 'sid01', 'deptinfo: deptname', 'Java'
dal 'Student', 'sid01', 'deptinfo: joinyear', '1994'
-> Podobno lahko ustvarimo podatke za sid02, sid03…
- Zdaj moramo izdelati tabelo Hive, ki kaže na tablico HBase.
- Za vsak stolpec v Hbase bomo v Hive ustvarili eno posebno tabelo za ta stolpec. V tem primeru bomo v panju ustvarili 2 tabeli
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> Podobno moramo v panju izdelati tabelo s podatki o odseku.
- Zdaj lahko v panj zapišemo poizvedbo SQL, kot je navedeno spodaj.
select * from student_hbase;
Na ta način lahko Hive integriramo s HBase.
Zaključek - Hive proti HBase
Kot je razpravljeno, sta obe različni tehnologiji, ki zagotavljata različne funkcionalnosti, kjer Hive deluje z uporabo jezika SQL, lahko pa ga imenujemo tudi, ko HQL in HBase uporabljajo pare ključ-vrednost za analizo podatkov. Hive in HBase delujejo bolje, če so združeni, ker ima panj nizke zamude in lahko obdeluje ogromno količino podatkov, vendar ne more vzdrževati posodobljenih podatkov, HBase pa ne podpira analize podatkov, ampak podpira posodobitve na ravni vrstic na veliko količino podatkov.
Priporočeni članek
To je vodnik za Hive proti HBase, njihov pomen, primerjava med glavo, ključne razlike, tabela primerjave in sklep. Če želite izvedeti več, si oglejte tudi naslednje članke -
- Apache Pig vs Apache Pive - Top 12 uporabnih razlik
- Ugotovite 7 najboljših razlik med Hadoopom in HBase
- Top 12 primerjava Apache Hive z Apache HBase (Infographics)
- Hadoop vs Hive - odkrijte najboljše razlike