

Uvod v DataFrame Python Pandas DataFrame
Na spletu je več razširitev za Python Library, Pandas. Eden takšnih je Data (pan) Data (das). Ta beseda, * Panel *, subtilno namiguje na dvodimenzionalno strukturo podatkov, ki je prisotna v tej knjižnici, in neizmerno krepi uporabnike. Prav ta struktura se imenuje DataFrame.
To je v bistvu matrica vrstic in stolpcev, ki vsebuje celoten nabor podatkov, z zelo natančnimi možnostmi indeksiranja istega. DataFrame (DF) si lahko slikovno predstavljamo zelo podobno Excelu. Močno pa je, da je na podatkih, shranjenih v DataFrame, mogoče opraviti analitične in transformacijske operacije.
Kaj točno je DataFrame Python Pandas?
Stran Pydata se lahko sklicuje na nekaj uradne opredelitve.
Če ga pravilno razumemo, omenja DataFrame kot stolpčno strukturo, ki lahko shrani kateri koli objekt python (vključno s samim DataFrame) kot eno vrednost celice. (Celica se indeksira z edinstveno kombinacijo vrstic in stolpcev)
DataFrames so sestavljene iz treh osnovnih komponent: podatkov, vrstic in stolpcev.
- Podatki: Nanaša se na dejanske predmete / entitete, shranjene v celici v DataFrame in na vrednosti, ki jih predstavljajo te entitete. Predmet je katerega koli veljavnega podatkovnega tipa python, bodisi vgrajen ali uporabniško določen.
- Vrstice: Reference, ki se uporabljajo za identifikacijo (ali indeksiranje) določenega niza opažanj iz celotnih podatkov, shranjenih v DataFrame, se imenujejo vrstice. Da bi bilo jasno, predstavlja uporabljene indekse in ne le podatke v posameznem opazovanju.
- Stolpci: Reference, ki se uporabljajo za identifikacijo (ali indeksiranje) niza atributov za vsa opažanja v DataFrame. Kot v primeru vrstic se tudi ti nanašajo na indeks stolpcev (ali glave stolpcev), namesto na podatke v stolpcu.
Torej, brez dodatnega aduta, preizkusimo nekaj načinov za ustvarjanje teh nadvse močnih struktur.
Koraki za ustvarjanje podatkovnih okvirjev Python Pandas
Podatkovni okvir Python Pandas DataFrame lahko ustvarite z uporabo naslednje kode,
1. Uvoz pand
Če želite ustvariti DataFrames, je treba uvoziti knjižnico pand (tukaj ni presenečenje). Uvozili ga bomo z vzdevnikom pd, ki bo priročno napeljal predmete pod modulom.
Koda:
import pandas as pd
2. Ustvarjanje prvega objekta DataFrame
Ko je knjižnica uvožena, so v vašem delovnem prostoru na voljo vse metode, funkcije in konstruktorji. Poskusimo torej ustvariti vanilijo DataFrame.
Koda:
import pandas as pd
df = pd.DataFrame()
print(df)
Izhod:
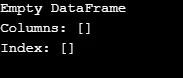
Kot je prikazano v izhodu, konstruktor vrne prazen DataFrame.
Zdaj se osredotočimo na ustvarjanje DataFrames iz podatkov, shranjenih v nekaterih verjetnih predstavitvah.
- DataFrame iz slovarja: Recimo, da imamo slovar, ki shranjuje seznam podjetij v programski domeni in število let, ko so bila aktivna.
Koda:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Oglejmo si predstavitev vrnjenega predmeta DataFrame s tiskanjem na konzolo.
Izhod:

Kot je razvidno, se vsak ključ slovarja obravnava kot stolpec v DataFrame, indeksi vrstic pa se samodejno ustvarijo od 0. Precej enostavno!
Recimo, da ste mu želeli dati indeks po meri namesto 0, 1, .. 4. Morate samo poslati želeni seznam kot parameter konstruktorju in pande bodo naredile potrebno.
Koda:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
Izhod:
Starost podjetja
Alpha Google 21
Beta Amazon 23
Gamma Infosys 38
Delta Directi 22
Zdaj lahko nastavite indekse vrstic na katero koli želeno vrednost.
- DataFrame iz datoteke CSV: Ustvarimo datoteko CSV, ki vsebuje enake podatke kot v našem slovarju. Pokličimo datoteko CompanyAge.csv
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Datoteko je mogoče naložiti v podatkovni okvir (ob predpostavki, da je prisoten v trenutnem delovnem imeniku) na naslednji način.
Koda:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
Izhod:
Starost podjetja
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
Z nastavitvijo imen parametrov , ki zaobide seznam vrednosti, jih dodelite kot glave stolpcev v istem vrstnem redu, kot so prisotni na seznamu. Podobno lahko indekse vrstic nastavite s posredovanjem seznama parametru indeksa, kot je prikazano v prejšnjem razdelku. Zaglavje = Nobeno ne kaže manjkajočih glav stolpcev v podatkovni datoteki.
Recimo, da so bila imena stolpcev del podatkovne datoteke. Potem bo nastavitev header = False opravila potrebno delo.
3. CompanyAgeWithHeader.csv
Podjetje, starost
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Kodeks se spremeni v
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
Izhod:
Starost podjetja
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
- DataFrame iz datoteke Excel: Podatki se pogosto delijo v datoteke excel, saj ostajajo najbolj priljubljeno orodje, ki ga običajni ljudje uporabljajo za sledenje Adhocu. Naše razprave torej ne smemo prezreti.
Predpostavimo, da so podatki, podobni kot v CompanyAgeWithHeader.csv, zdaj shranjeni v CompanyAgeWithHeader.xlsx, v listu z imenom Company Age. Z naslednjo kodo bo ustvarjen enak DataFrame kot zgoraj.
Koda:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
Izhod:
Starost podjetja
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
Kot lahko vidite, lahko enak DataFrame ustvarite s prenosom imena datoteke in imena lista.
Nadaljnje branje in naslednji koraki
Prikazane metode predstavljajo zelo majhno podskupino v primerjavi z vsemi različnimi načini ustvarjanja podatkovnih okvirjev. Ti so bili ustvarjeni z namenom, da se začnejo. Zagotovo raziščite navedene reference in poskusite raziskati druge načine, vključno s povezovanjem z bazo podatkov za branje podatkov neposredno iz DataFrame.
Zaključek
Pandas DataFrame se je v svetu Data Science in Data Analytics izkazal kot izmenjevalec iger, prav tako pa je primeren za ad hoc kratkoročne projekte. Na voljo je z vrsto orodij, ki omogočajo rezanje in zapisovanje nabora podatkov z izjemno lahkoto. Upajmo, da bo to služilo kot odskočna deska pri vaši poti naprej.
Priporočeni članki
To je vodnik za Python-Pandas DataFrame. Tukaj razpravljamo o korakih za ustvarjanje podatkovnega okvira python-pandas in njegovo implementacijo kode. Če želite izvedeti več, si oglejte tudi naslednje članke -
- Top 15 značilnosti Pythona
- Različne vrste nizov Python
- Najboljše 4 vrste spremenljivk v Pythonu
- Najboljših 6 urednikov Pythona
- Nizi v strukturi podatkov