
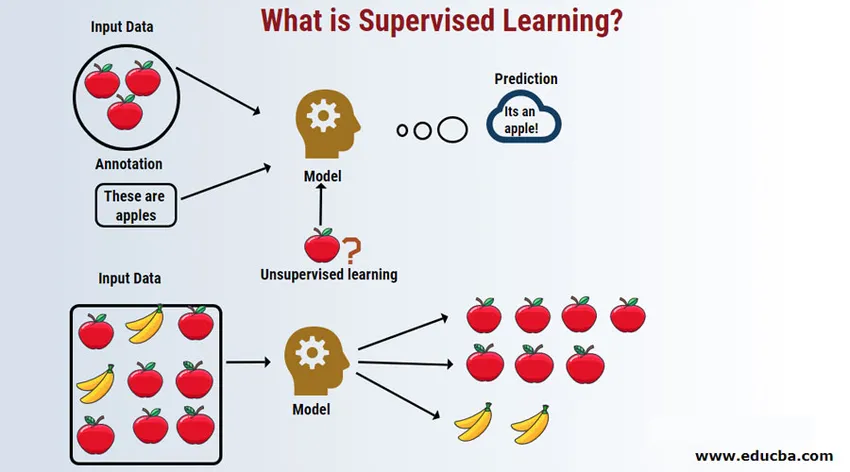
Uvod v nadzorovano učenje
Nadzorovano učenje je področje strojnega učenja, kjer delamo na napovedovanju vrednosti s pomočjo označenih nizov podatkov. Označeni nizi vhodnih podatkov imenujemo neodvisna spremenljivka, napovedani rezultati pa imenujemo odvisna spremenljivka, ker so za njihove rezultate odvisni od neodvisne spremenljivke. Na primer, vsi imamo v svojem e-poštnem računu (na primer Gmail) mapo z neželeno pošto, ki samodejno zazna večino nezaželene e-pošte z goljufijami z natančnostjo nad 95%. Deluje na podlagi nadzorovanega modela učenja, kjer imamo nabor usposabljanja z označenimi podatki, ki je v tem primeru označen kot neželena e-pošta, ki jo uporabniki označijo. Ti sklopi za usposabljanje se uporabljajo za učenje, ki se bodo pozneje uporabili za kategorizacijo novih e-poštnih sporočil kot neželeno pošto, če ustreza kategoriji.
Delo na nadzorovanem strojnem učenju
Razumejmo nadzorovano strojno učenje s pomočjo primera. Recimo, da imamo košaro s sadjem, ki je napolnjena z različnimi vrstami sadja. Naša naloga je kategorizirati sadje glede na njihovo kategorijo.
V našem primeru smo obravnavali štiri vrste sadja in to so jabolka, banana, grozdje in pomaranče.
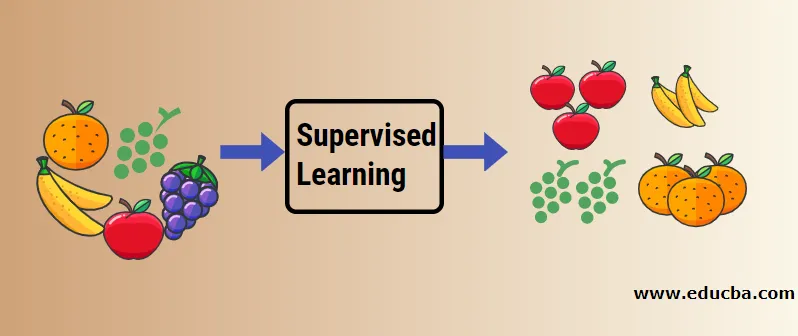
Zdaj bomo poskušali omeniti nekatere edinstvene lastnosti teh sadežev, zaradi katerih so edinstveni.
|
S št. | Velikost | Barva | Oblika |
Ime |
|
1 | Majhna | Zelena | Okrogla do ovalna, Sijajna oblika Cilindrična |
Grozdje |
|
2 | Velik | rdeča | Zaobljena oblika z depresijo na vrhu |
Apple |
|
3 | Velik | Rumena | Dolg ukrivni valj |
Banana |
| 4 | Velik | Oranžna | Zaobljena oblika |
Oranžna |
Zdaj naj povemo, da ste pobrali sadje iz košare s sadjem, si ogledali njegove lastnosti, na primer njegovo obliko, velikost in barvo, nato pa sklepate, da je barva tega sadeža rdeča, velikost, če je velika, oblika je zaobljene oblike z depresijo na vrhu, zato je jabolko.
- Prav tako storite enako tudi za vse ostale preostale sadeže.
- Skrajni desni stolpec (ime sadja) je znan kot odzivna spremenljivka.
- Tako oblikujemo nadzorovan model učenja, zdaj pa bo vsak nov (recimo robot ali tujec) z določenimi lastnostmi dokaj enostavno, da zlahka združijo isto vrsto sadja skupaj.
Vrste algoritma nadzorovanega strojnega učenja
Oglejmo si različne vrste algoritmov strojnega učenja:
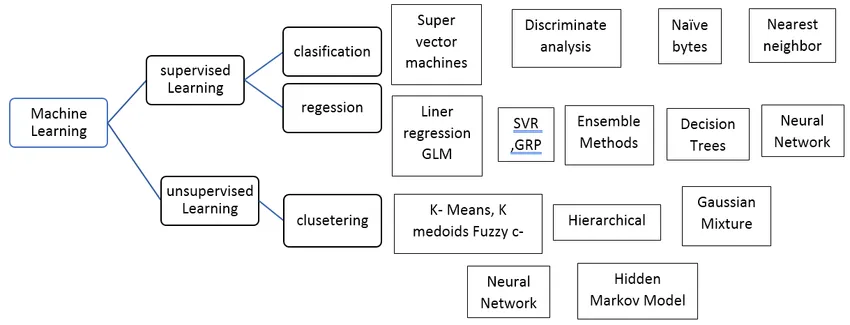
Regresija:
Regresija se uporablja za napovedovanje enotnih vrednosti s pomočjo nabora podatkov o vadbi. Izhodna vrednost se vedno imenuje kot odvisna spremenljivka, medtem ko so vhodi znani kot neodvisna spremenljivka. V nadzorovanem učenju imamo različne vrste regresije, npr.
- Linearna regresija - Tu imamo samo eno neodvisno spremenljivko, ki se uporablja za napovedovanje izhodne, torej odvisne spremenljivke.
- Večkratna regresija - Tu imamo več kot eno neodvisno spremenljivko, ki se uporablja za napovedovanje izhoda, tj. Odvisne spremenljivke.
- Polinomna regresija - Graf med odvisnimi in neodvisnimi spremenljivkami sledi polinomni funkciji. Na primer, na začetku se spomin povečuje s starostjo, nato pri določeni starosti doseže prag, nato pa se s starostjo začne zmanjševati.
Razvrstitev:
Klasifikacija nadzorovanih algoritmov učenja se uporablja za združevanje podobnih predmetov v edinstvene razrede.
- Binarna klasifikacija - Če algoritem poskuša združiti dve različni skupini razredov, se imenuje binarna klasifikacija.
- Razvrstitev v več razredov - če algoritem poskuša predmete razvrstiti v več kot dve skupini, se imenuje klasifikacija v več razredih.
- Trdnost - algoritmi za razvrščanje običajno delujejo zelo dobro.
- Pomanjkljivosti - so nagnjeni k pretiranemu opremljanju in so lahko neomejeni. Na primer - e-poštni klasifikator
- Logistična regresija / klasifikacija - Kadar je spremenljivka Y binarna kategorična (tj. 0 ali 1), za napoved uporabljamo logistično regresijo. Na primer - napovedovanje, ali je neka transakcija s kreditno kartico prevara ali ne.
- Naivni Bayesovi klasifikatorji - klasifikator Naive Bayes temelji na Bayesovem izrekanju. Ta algoritem je ponavadi najbolj primeren, kadar je velikost vhodov velika. Sestavljen je iz acikličnih grafov z enim staršem in številnimi otroškimi vozlišči. Otroška vozlišča so med seboj neodvisna.
- Drevesa odločitve - drevo odločanja je drevesna graf, podobna strukturi, ki je sestavljena iz notranjega vozlišča (test na atributu), veje, ki označuje izid preskusa in listnih vozlišč, ki predstavlja porazdelitev razredov. Koreninsko vozlišče je zgornje vozlišče. Gre za zelo razširjeno tehniko, ki se uporablja za razvrščanje.
- Podporni vektorski stroj - podporni vektorski stroj je ali SVM opravi klasifikacijo tako, da poišče hiperplane, ki bi morale povečati mejo med dvema razredoma. Ti stroji SVM so povezani s funkcijami jedra. Polja, kjer se SVM uporabljajo široko, so biometrija, prepoznavanje vzorcev itd.
Prednosti
Spodaj je nekaj prednosti nadzorovanih modelov strojnega učenja:
- Delovanje modelov je mogoče optimizirati z uporabniškimi izkušnjami.
- Nadzorovano učenje daje rezultate z uporabo predhodnih izkušenj in vam omogoča tudi zbiranje podatkov.
- Nadzorovani algoritmi strojnega učenja se lahko uporabljajo za izvajanje številnih problemov v resničnem svetu.
Slabosti
Slabosti nadzorovanega učenja so naslednje:
- Pri napornih treningih nadzorovanih modelov strojnega učenja lahko traja veliko časa, če je nabor podatkov večji.
- Razvrstitev velikih podatkov včasih predstavlja večji izziv.
- Mogoče se bo treba spoprijeti s težavami prekomernega opremljanja.
- Potrebujemo veliko dobrih primerov, če želimo, da model deluje dobro, medtem ko treniramo klasifikator.
Dobre prakse pri gradnji učnih modelov
Pri izdelavi nadzorovanih modelov učnih strojev je dobra praksa: -
- Pred izdelavo katerega koli dobrega modela strojnega učenja je treba izvesti postopek predobdelave podatkov.
- Morate se odločiti za algoritem, ki naj bo najbolj primeren za določeno težavo.
- Odločiti se moramo, kakšne podatke bomo uporabili za nabor usposabljanja.
- Potrebuje odločitev o strukturi algoritma in funkcije.
Zaključek
V našem članku smo izvedeli, kaj je nadzorovano učenje, in videli smo, da tukaj treniramo model z uporabo označenih podatkov. Nato smo se podali v delo modelov in njihovih različnih vrst. Končno smo videli prednosti in slabosti teh nadzorovanih algoritmov strojnega učenja.
Priporočeni članki
To je vodnik, kaj je nadzorovano učenje ?. Tukaj razpravljamo o konceptih, kako deluje, vrste, prednosti in slabosti nadzorovanega učenja. Če želite izvedeti več, lahko preberete tudi druge naše predlagane članke -
- Kaj je globoko učenje
- Nadzorovano učenje vs poglobljeno učenje
- Kaj je sinhronizacija v Javi?
- Kaj je spletno gostovanje?
- Načini za ustvarjanje odločitvenega drevesa s prednostmi
- Polinomna regresija | Uporaba in funkcije