

Uvod v drevo odločitev pri pridobivanju podatkov
V današnjem svetu o "velikih podatkih" izraz "podatkovno rudarjenje" pomeni, da moramo preučiti velike nabore podatkov in izvesti "rudarjenje" podatkov ter iz njih ugotoviti pomemben sok ali bistvo tega, kar želijo povedati podatki. Zelo analogna situacija je tudi pri pridobivanju premoga, kjer so potrebna različna orodja za kopanje premoga, zakopanega globoko pod zemljo. Med orodji pri pridobivanju podatkov je eno izmed njih tudi „Drevo odločanja“. Tako je kopanje podatkov samo po sebi obsežno področje, kjer bomo v naslednjih nekaj odstavkih poglobljeno potopili v „orodje“ orodja Drevesa v Data Mining.
Algoritem drevesa odločitev pri iskanju podatkov
Drevo odločanja je nadzorovan učni pristop, pri katerem treniramo prisotne podatke in že vemo, kaj ciljna spremenljivka dejansko je. Kot že ime pove, ima algoritem drevesno vrsto strukture. Poglejmo najprej teoretični vidik drevesa odločitve in nato v grafičnem pristopu pogledamo isto. V drevesu odločitev algoritem razdeli nabor podatkov na podskupine na podlagi najpomembnejšega ali pomembnejšega atributa. Najpomembnejši atribut je označen v korenskem vozlišču in tam se deli celovit nabor podatkov, ki je prisoten v korenskem vozlišču. Ta ločitev je znana kot odločitvena vozlišča. V primeru, da ni mogoče razdeliti, vozlišče označimo kot listno vozlišče.
Za zaustavitev algoritma, da doseže previsoko stopnjo, je uporabljeno merilo zaustavitve. Eno izmed meril za zaustavitev je najmanjše število opazovanj v vozlišču, preden se zgodi delitev. Medtem ko pri delitvi nabora uporabljate odločitveno drevo, je treba biti pozoren, da ima veliko vozlišč samo hrupne podatke. Da bi se zadovoljili s težavami s tujimi ali hrupnimi podatki, uporabljamo tehnike, znane kot Podrezanje podatkov. Obrezovanje podatkov ni nič drugega kot algoritem za razvrščanje podatkov iz podskupine, ki otežuje učenje iz danega modela.
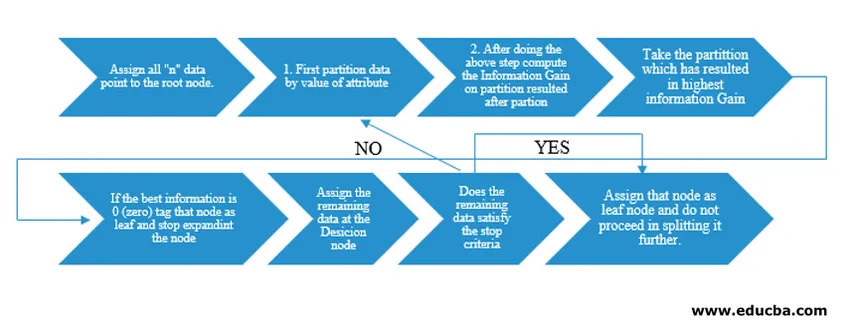
Algoritem odločitvenega drevesa je raziskovalec stroja J. Ross Quinlan izdal kot ID3 (Iterative Dichotomiser). Kasneje je bil C4.5 izpuščen kot naslednik ID3. Tako ID3 kot C4.5 sta pohlepna pristopa. Zdaj si oglejmo diagram poteka algoritma odločitvenega drevesa.
Za naše razumevanje psevdo kod bi vzeli podatkovne točke "n", od katerih ima vsaka atribute "k". Spodaj je prikazan diagram poteka, pri čemer se upošteva „Dobiček informacij“ kot pogoj za ločitev.
IG (on individual split) = Entropy before the split – Entropy after a split (On individual split)
Namesto informacijskega dobička (IG) lahko kot merilo delitve uporabimo tudi Gini indeks. Za lažje razumevanje razlike med tema dvema meriloma si lahko omislimo to pridobitev informacij kot razliko entropije pred razpletom in po razcepu (razdelitev na podlagi vseh razpoložljivih funkcij).
Entropija je kot naključnost in po razcepu bi dosegli točko, da bi imeli stanje najmanj naključnosti. Zato mora biti informacijski dobiček največji v lastnosti, ki jo želimo razdeliti. Če bi želeli izbrati delitev na podlagi Gini indeksa, bi našli Gini indeks za različne atribute in z istim bomo ugotovili uteženi Gini indeks za različen split, za delitev nabora pa bomo uporabili tistega z višjim Gini indeksom.
Pomembni pogoji drevesa odločanja pri iskanju podatkov
Tu je nekaj pomembnih pogojev drevesa odločanja pri pridobivanju podatkov, ki je navedeno spodaj:
- Root vozlišče: To je prvo vozlišče, kjer poteka cepitev.
- Listno vozlišče: To je vozlišče, po katerem ni več veje.
- Odločitveno vozlišče: Vozlišče, nastalo po delitvi podatkov iz prejšnjega vozlišča, je znano kot odločilno vozlišče.
- Podružnica: Pododdelek drevesa, ki vsebuje podatke o poteku na vozlišču odločitve.
- Obrezovanje: kadar pride do odstranitve pododdelkov odločitvenega vozlišča za oskrbo zunanjih ali hrupnih podatkov, se imenuje obrezovanje. Menijo tudi, da je nasprotno od cepitve.
Uporaba drevesa odločitev pri pridobivanju podatkov
Drevo odločitev ima vgrajeno strukturo diagramov poteka z vrsto algoritma. V bistvu ima vzorec "Če X, potem Y drugo Z", medtem ko je razdelitev narejena. Ta vrsta vzorca se uporablja za razumevanje človeške intuicije na programskem področju. Zato lahko to veliko uporabimo pri različnih težavah s kategorizacijo.
- Ta algoritem se lahko široko uporablja na področju, kjer je glede na opravljeno analizo povezana ciljna funkcija.
- Ko so na voljo številni načini ukrepanja.
- Zunanja analiza.
- Razumevanje pomembnega nabora funkcij za celoten nabor podatkov in "mine" nekaj funkcij s seznama sto funkcij velikih podatkov.
- Izbira najboljšega leta za potovanje do cilja.
- Postopek odločanja, ki temelji na različnih okoliščinah.
- Analiza trnov.
- Analiza občutka
Prednosti drevesa odločitve
Spodaj je opisanih nekaj prednosti drevesa odločitve:
- Enostavnost razumevanja: Način, kako je drevo odločanja prikazano v njegovih grafičnih oblikah, olajša razumevanje osebe z neanalitičnim ozadjem. Zlasti za vodilne ljudi, ki želijo pogledati, katere lastnosti so pomembne samo s pogledom na drevo odločitve, lahko ugotovijo svojo hipotezo.
- Raziskovanje podatkov: Kot je razpravljeno, je pridobivanje pomembnih spremenljivk temeljna funkcionalnost drevesa odločanja in z uporabo istega je mogoče med raziskovanjem podatkov ugotoviti, pri kateri odločitvi, katera spremenljivka bo v fazi pridobivanja podatkov in modeliranja potrebna posebna pozornost.
- Človeško posredovanje je med fazo priprave podatkov zelo malo, zaradi česar porabi čas med podatki, se čiščenje zmanjša.
- Drevo odločanja je sposobno obravnavati kategorične in numerične spremenljivke, poleg tega pa lahko obravnava tudi težave s klasifikacijo v več razredih.
- Kot del predpostavke drevesa odločitve nimajo predpostavke o prostorski razdelitvi in strukturi klasifikatorja.
Zaključek
Za konec še zaključimo, da drevesa odločitev prinašajo povsem drugačen razred nelinearnosti in skrbijo za reševanje problemov o nelinearnosti. Ta algoritem je najboljša izbira za posnemanje odločitve na ravni ljudi in za prikaz v matematično-grafični obliki. Pri določanju rezultatov iz novih nevidnih podatkov uporablja pristop od zgoraj navzdol in sledi načelu delitve in osvajanja.
Priporočeni članki
To je vodnik po drevesu odločitev v podatkovnem rudarstvu. Tukaj razpravljamo o algoritmu, pomembnosti in uporabi drevesa odločanja pri pridobivanju podatkov ter njegovih prednosti. Če želite izvedeti več, si oglejte tudi naslednje članke -
- Strojno učenje podatkovne znanosti
- Vrste tehnik analize podatkov
- Drevo odločitve v R
- Kaj je podatkovno rudarjenje?
- Vodnik po različnih metodologijah analize podatkov