

Uvod v algoritem drevesa odločitve
Ko imamo težavo rešiti, ali gre za klasifikacijo ali regresijsko težavo, je algoritem odločitvenega drevesa eden najbolj priljubljenih algoritmov, ki se uporablja za gradnjo klasifikacijskih in regresijskih modelov. Spadajo v kategorijo nadzorovanega učenja, tj. Podatkov, ki so označeni.
Kaj je algoritem drevesne odločitve?
Algoritem drevesne odločitve je nadzorovan algoritem strojnega učenja, pri katerem se podatki nenehno delijo na vsako vrstico na podlagi določenih pravil, dokler ni ustvarjen končni rezultat. Vzemimo primer, predpostavimo, da odprete nakupovalni center in seveda bi si želeli, da bi s časom rasel v poslu. Za to zadevo bi morali v nakupovalnem središču vrniti kupce in nove stranke. Za to bi pripravili različne poslovne in tržne strategije, kot so pošiljanje e-poštnih sporočil potencialnim strankam; ustvarjati ponudbe in ponudbe, ciljati na nove stranke itd. Toda kako vemo, kdo so potencialne stranke? Z drugimi besedami, kako razvrstiti kategorijo kupcev? Tako bodo nekatere stranke obiskale enkrat na teden, druge pa jih želijo obiskati enkrat ali dvakrat na mesec, nekatere pa obiščejo v četrtletju. Torej, drevesa odločitev so eden takšnih algoritmov za razvrščanje, ki bo razvrščal rezultate v skupine, dokler ne ostane več nobena podobnost.
Na ta način se odločitveno drevo spusti v drevesno obliko. Glavne sestavine drevesa odločanja so:
- Vozlišča odločitve, kjer se podatki razdelijo ali rečejo, je to mesto za atribut.
- Povezava odločitve, ki predstavlja pravilo.
- Odločitveni listi, ki so končni rezultati.

Delo algoritma drevesa odločitve
Pri delu drevesa odločanja je vključenih veliko korakov:
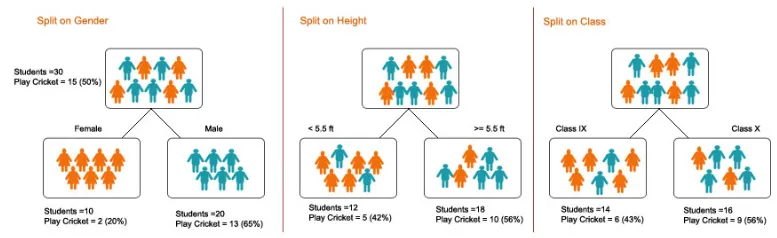
1. Razdelitev - je postopek razdelitve podatkov na podmnožje. Razdelitev se lahko izvede na različne dejavnike, kot je prikazano spodaj, tj. Na podlagi spola, višine ali glede na razred.
2. Obrezovanje - je postopek krajšanja vej drevesa odločitve, s čimer se omeji globina drevesa
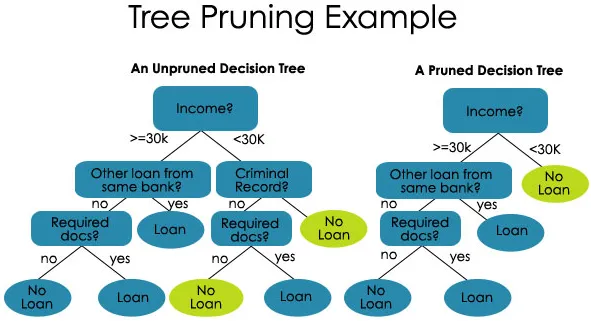
Obrezovanje je tudi dveh vrst:
- Predobrezovanje - tu nehamo rasti drevesa, ko ne najdemo nobene statistično pomembne povezave med atributi in razredom na katerem koli določenem vozlišču.
- Obrezovanje po obrezovanju - da bi lahko obrezali, moramo preveriti zmogljivost modela testnega niza in nato odrezati veje, ki so posledica pretiranega hrupa iz vadbe.
3. Izbira dreves - tretji korak je postopek iskanja najmanjšega drevesa, ki ustreza podatkom.
Primeri in ponazoritev oblikovanja drevesa odločitve
Zdaj, ko smo se naučili načel drevesa odločitve. Razumejmo in ponazorimo to s pomočjo primera.
Recimo, da bi radi igrali kriket na določen dan (na primer soboto). Kateri so dejavniki, ki bodo odločali, ali se bo igra zgodila ali ne?
Jasno je, da je glavni dejavnik podnebje, noben drug dejavnik nima toliko verjetnosti, kot ga ima podnebje za prekinitev igre.
Zbrali smo podatke iz zadnjih 10 dni, ki so predstavljeni spodaj:
| Dan | Vreme | Temperatura | Vlažnost | Veter | Igrati? |
| 1 | Oblačno | Vroče | Visoka | Šibka | Da |
| 2 | Sončno | Vroče | Visoka | Šibka | Ne |
| 3 | Sončno | Blag | Običajno | Močna | Da |
| 4 | Deževen | Blag | Visoka | Močna | Ne |
| 5 | Oblačno | Blag | Visoka | Močna | Da |
| 6 | Deževen | Kul | Običajno | Močna | Ne |
| 7 | Deževen | Blag | Visoka | Šibka | Da |
| 8 | Sončno | Vroče | Visoka | Močna | Ne |
| 9 | Oblačno | Vroče | Običajno | Šibka | Da |
| 10 | Deževen | Blag | Visoka | Močna | Ne |
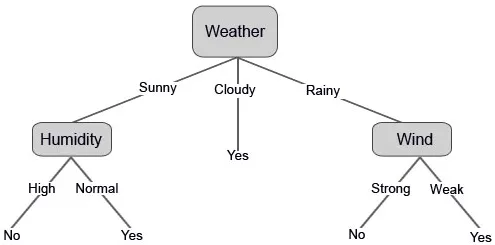
Zgradimo zdaj svoje odločitveno drevo na podlagi podatkov, ki jih imamo. Torej smo razdelili odločitveno drevo na dve ravni, prva temelji na atributu "Vreme", druga vrstica pa temelji na "Vlažnost" in "Veter". Spodnje slike prikazujejo naučeno drevo odločitev.
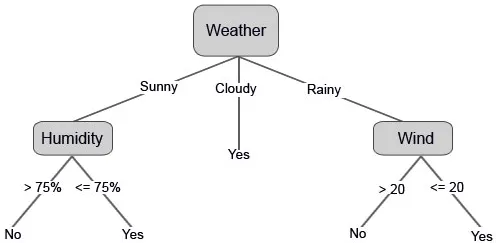
Prav tako lahko nastavimo nekatere mejne vrednosti, če so funkcije neprekinjene.
Kaj je entropija v algoritmu drevesa odločitve?
Z enostavnimi besedami, entropija je merilo neurejenosti vaših podatkov. Čeprav ste ta izraz morda slišali pri pouku matematike ali fizike, je tukaj enako.
Razlog, da se entropija uporablja v drevesu odločitev, je zato, ker je končni cilj v drevesu odločitev združevanje podobnih podatkovnih skupin v podobne razrede, to je urejanje podatkov.
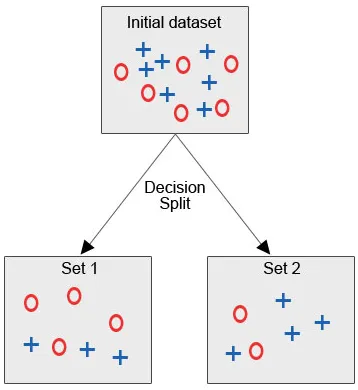
Poglejmo si spodnjo sliko, kjer imamo začetni nabor podatkov in moramo uporabiti algoritem drevesa odločitve, da združimo podobne podatkovne točke v eno kategorijo.
Po razdelitvi odločitve, kot jasno vidimo, večina rdečih krogov spada pod en razred, večina modrih križev pa pod drug razred. Zato je bila odločitev razvrstiti atribute, ki bi lahko temeljili na različnih dejavnikih.
Zdaj pa poskušajmo tukaj nekaj matematike:
Recimo, da imamo element „N“ in te postavke spadajo v dve kategoriji, zdaj pa za razvrščanje podatkov na podlagi nalepk uvedemo razmerje:
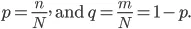
Entropija naše množice je podana z naslednjo enačbo:
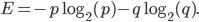
Oglejmo graf za dano enačbo:
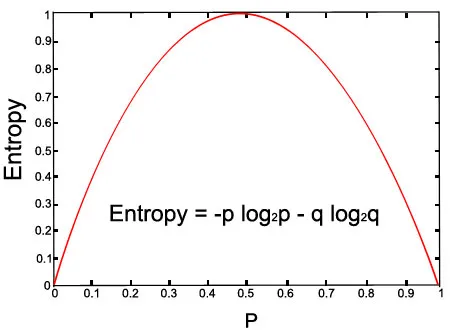
Nad sliko (s p = 0, 5 in q = 0, 5)
Prednosti
1. Odločilno drevo je enostavno razumeti in ko ga razumemo, ga lahko sestavimo.
2. Lahko implementiramo drevo odločitev o številskih in kategoričnih podatkih.
3. Drevo odločitve je dokazano močan model z obetavnimi rezultati.
4. So tudi časovno učinkovite z velikimi podatki.
5. Za usposabljanje podatkov je potrebno manj napora.
Slabosti
1. Nestabilnost - samo če so podatki natančni in točni, bo odločitveno drevo prineslo obetavne rezultate. Tudi če se vhodni podatki rahlo spremenijo, lahko drevo povzroči velike spremembe.
2. Kompleksnost - Če je nabor podatkov ogromen s številnimi stolpci in vrsticami, je oblikovanje drevesa odločanja z veliko vejami zelo zapleteno.
3. Stroški - včasih tudi stroški ostajajo glavni dejavnik, ker kadar je potrebno sestaviti kompleksno drevo odločitev, je potrebno napredno znanje kvantitativne in statistične analize.
Zaključek
V tem članku smo spoznali algoritem drevesa odločitve in kako ga sestaviti. Videli smo tudi veliko vlogo, ki jo v algoritmu drevesa odločanja igra Entropy in nazadnje smo videli prednosti in slabosti drevesa odločitve.
Priporočeni članki
To je vodnik po Algoritmu drevesa odločitve. Tu smo razpravljali o vlogi, ki jo igrajo entropija, delo, prednosti in slabosti. Če želite izvedeti več, lahko preberete tudi druge naše predlagane članke -
- Pomembne metode pridobivanja podatkov
- Kaj je spletna aplikacija?
- Vodnik po tem, kaj je podatkovna znanost?
- Vprašanja o intervjuju z analitikom podatkov
- Uporaba drevesa odločitev pri pridobivanju podatkov