

Uvod v linearno regresijsko analizo
Pogosto je zmedeno spoznavanje nekega koncepta, ki je celo del našega vsakodnevnega življenja. Vendar to ni problem, lahko si pomagamo in se razvijemo, da se učimo iz svojih vsakodnevnih dejavnosti le z analizo stvari in se ne bojimo postavljati vprašanj. Zakaj cena vpliva na povpraševanje po blagu, zakaj sprememba obrestne mere vpliva na ponudbo denarja. Na vse je mogoče odgovoriti s preprostim pristopom, znanim kot linearna regresija. Edina zapletenost, ki jo čutimo pri obravnavi linearne regresijske analize, je prepoznavanje odvisnih in neodvisnih spremenljivk.
Poiskati moramo, kaj vpliva na kaj, in polovica problema je rešena. Moramo videti, ali cena ali povpraševanje vplivata na vedenje drug drugega. Ko smo spoznali, katera je neodvisna in odvisna spremenljivka, je dobro, da se lotimo analize. Na voljo je več vrst regresijske analize. Ta analiza je odvisna od spremenljivk, ki so nam na voljo.
3 vrste regresijske analize
Te tri regresijske analize imajo največ primerov uporabe v resničnem svetu, sicer pa obstaja več kot 15 vrst regresijske analize. Vrste regresijske analize, o katerih bomo razpravljali, so:
- Linearna regresijska analiza
- Multipla linearna regresijska analiza
- Logistična regresija
V tem članku se bomo osredotočili na preprosto linearno regresijsko analizo. Ta analiza nam pomaga ugotoviti odnos med neodvisnim in odvisnim dejavnikom. Z enostavnejšimi besedami nam regresijski model pomaga ugotoviti, kako spremembe neodvisnega dejavnika vplivajo na odvisni dejavnik. Ta model nam pomaga na več načinov, kot so:
- Je preprost in močan statistični model
- Pomagal nam bo pri pripravi napovedi in napovedi
- Pomagala nam bo pri boljši poslovni odločitvi
- Pomagal nam bo analizirati rezultate in popraviti napake
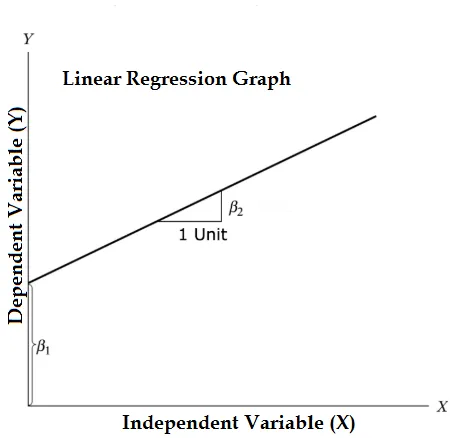
Enačba linearne regresije in jo razdelite na ustrezne dele
Y = β1 + β2X + ϵ
- Kjer sta β1 v matematični terminologiji znana kot prestreznica in β2 v matematični terminologiji, znana kot naklon. Znani so tudi kot regresijski koeficienti. ϵ je izraz napake, to je del Y regresijskega modela ne zna razložiti.
- Y je odvisna spremenljivka (drugi izrazi, ki se zamenljivo uporabljajo za odvisne spremenljivke, so odzivna spremenljivka, regres in izmerjena spremenljivka, opažena spremenljivka, odzivna spremenljivka, pojasnjena spremenljivka, izhodna spremenljivka, eksperimentalna spremenljivka in / ali izhodna spremenljivka).
- X je neodvisna spremenljivka (regresorji, nadzorovana spremenljivka, manipulirana spremenljivka, pojasnjevalna spremenljivka, spremenljivka izpostavljenosti in / ali vhodna spremenljivka).
Problem: Za razumevanje, kaj je linearna regresijska analiza, vzamemo nabor podatkov "Avtomobili", ki privzeto prihaja v R imenikih. V tem naboru podatkov je 50 opazovanj (v osnovi vrstice) in 2 spremenljivki (stolpci). Imeni stolpcev sta "Dist" in "Speed". Tu moramo videti vpliv spremenljivk na razdaljo zaradi spremenljivih hitrosti. Za prikaz strukture podatkov lahko zaženemo kodno Str (nabor podatkov). Ta koda nam pomaga razumeti strukturo nabora podatkov. Te funkcionalnosti nam pomagajo do boljših odločitev, saj imamo v mislih boljšo sliko o strukturi nabora podatkov. Ta koda nam pomaga prepoznati vrsto podatkovnih nizov.
Koda:

Podobno lahko za preverjanje statističnih kontrolnih točk nabora podatkov uporabimo kodo Povzetek (avtomobili). Ta kodeks pomeni povprečno, srednjo, paleto nabora podatkov na poti, ki jo lahko raziskovalec uporablja, ko se spopada s težavo.
Izhod:
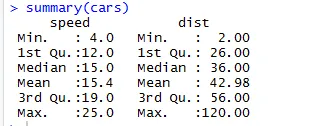
Tu lahko vidimo statistični rezultat vsake spremenljivke, ki jo imamo v svojem naboru podatkov.
Grafični prikaz nizov podatkov
Vrste grafičnih predstav, ki bodo zajete tukaj, so in zakaj:
- Scatter Plot: S pomočjo grafa lahko vidimo, v katero smer gre naš model linearne regresije, ali obstajajo kakšni trdni dokazi, ki dokazujejo naš model ali ne.
- Box Plot: Pomaga nam najti tujce.
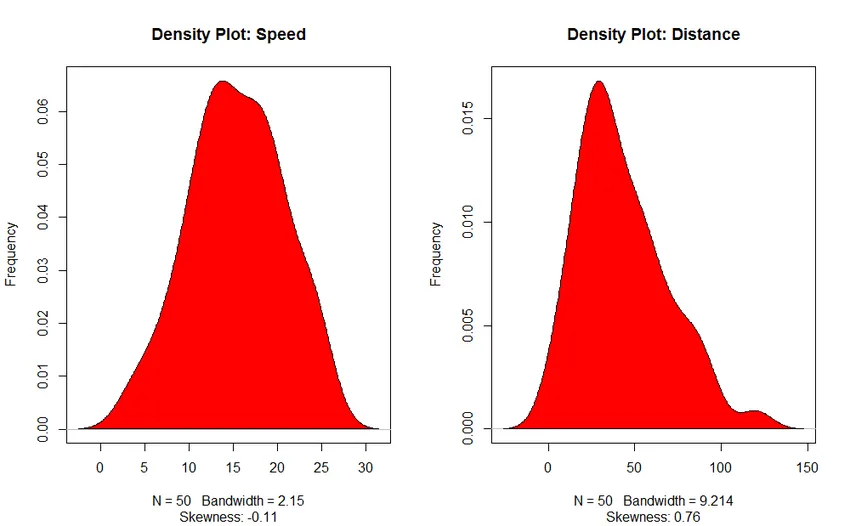
- Slika gostote: Pomagajte nam razumeti porazdelitev neodvisne spremenljivke, v našem primeru je neodvisna spremenljivka "Hitrost".
Prednosti grafičnega upodabljanja
Tu so naslednje prednosti:
- Lahko razumeti
- Pomaga nam pri hitri odločitvi
- Primerjalna analiza
- Manj truda in časa
1. Scatter Plot: Pomagal bo prikazati kakršna koli razmerja med neodvisno spremenljivko in odvisno spremenljivko.
Koda:

Izhod:
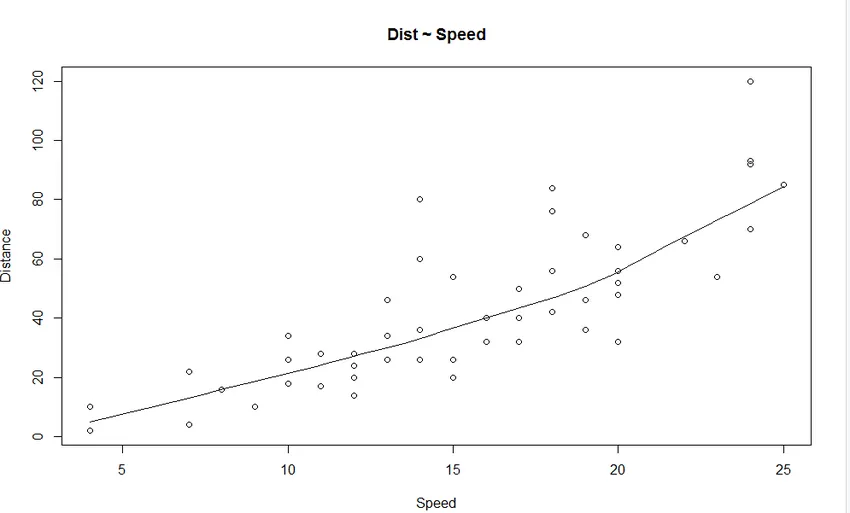
Iz grafa lahko vidimo linearno naraščajoč odnos med odvisno spremenljivko (Razdalja) in neodvisno spremenljivko (Hitrost).
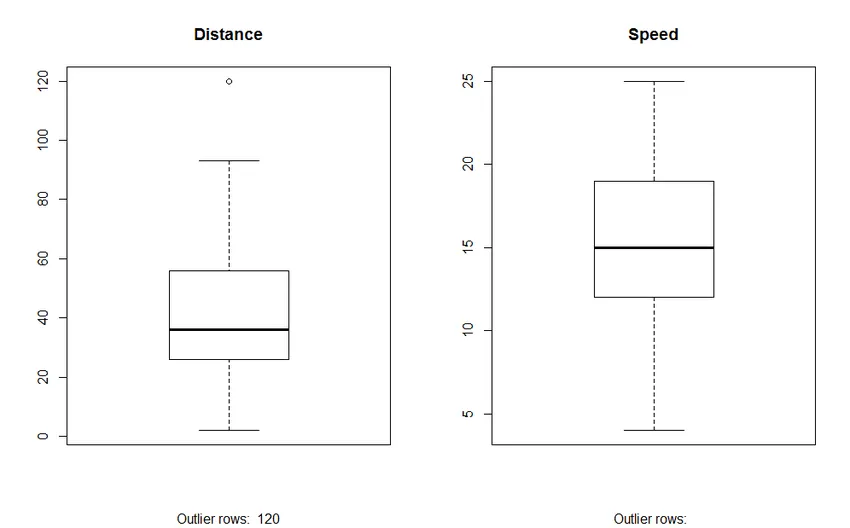
2. Box Plot: Box plot nam pomaga, da prepoznamo odseke v naborih podatkov. Prednosti uporabe škatle so:
- Grafični prikaz lokacije in širjenja spremenljivk.
- Pomaga nam razumeti naklonjenost in simetrijo podatkov.
Koda:

Izhod:
3. Načrt gostote (za preverjanje normalnosti porazdelitve)
Koda:
 Izhod:
Izhod:
Korelacijska analiza
Ta analiza nam pomaga najti odnos med spremenljivkami. V glavnem obstaja šest vrst korelacijske analize.
- Pozitivna korelacija (0, 01 do 0, 99)
- Negativna korelacija (-0, 99 do -0, 01)
- Ni korelacije
- Popolna korelacija
- Močna korelacija (vrednost bliža ± 0, 99)
- Šibka korelacija (vrednost bližja 0)
Scatter plot nam pomaga ugotoviti, katere vrste podatkovnih korelacijskih nizov so med njimi in kodo za iskanje korelacije

Izhod:
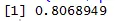
Tu imamo močno pozitivno povezavo med hitrostjo in razdaljo, kar pomeni, da sta med njima neposreden odnos.
Linearni regresijski model
To je osnovna komponenta analize, prej smo samo preizkušali in preizkušali, ali je nabor podatkov dovolj logičen za izvajanje takšne analize ali ne. Funkcija, ki jo nameravamo uporabiti, je lm (). Ta funkcija vsebuje dva elementa, ki sta Formula in Data. Preden dodelimo, da je spremenljivka odvisna ali neodvisna, moramo biti o tem zelo prepričani, ker je od tega odvisna celotna formula.
Formula izgleda tako,
Linearna regresija <- lm (odvisna spremenljivka ~ neodvisna spremenljivka, podatki = datum. Okvir)
Koda:

Izhod:
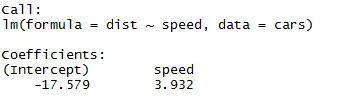
Kot se lahko spomnimo iz zgornjega dela članka, je enačba linearne regresije:
Y = β1 + β2X + ϵ
Zdaj bomo ustrezali informacijam, ki smo jih dobili iz zgornje kode v tej enačbi.
dist = −17.579 + 3.932 ∗ hitrost
Samo če najdemo enačbo linearne regresije, ne moremo preveriti tudi njene statistične vrednosti. Za to moramo posredovati kodo »Povzetek« na našem modelu linearne regresije.
Koda:

Izhod:

Obstaja več načinov preverjanja statistične pomembnosti modela, tukaj uporabljamo metodo P-vrednosti. Model lahko štejemo za statistično ustrezen, kadar je vrednost P manjša od vnaprej določene statistično pomembne ravni, ki je idealno 0, 05. V naši povzetki (linearna_regresija) lahko vidimo, da je vrednost P pod 0, 05, zato lahko sklepamo, da je naš model statistično pomemben. Ko smo prepričani v svoj model, lahko uporabimo svoj nabor podatkov za napovedovanje stvari.
Priporočeni članki
To je vodnik za linearno regresijsko analizo. Tukaj obravnavamo tri vrste linearne regresijske analize, grafični prikaz nizov podatkov s prednostmi in linearne regresijske modele. Obiščite lahko tudi druge naše sorodne članke, če želite izvedeti več -
- Regresijska formula
- Regresijsko testiranje
- Linearna regresija v R
- Vrste tehnik analize podatkov
- Kaj je regresijska analiza?
- Najpomembnejše razlike med regresijo in klasifikacijo
- Najboljših 6 razlik linearne regresije in logistične regresije