

Razlika med Apache Pive in Apache HBase -
Zgodba o Apache Pive se začne leta 2007, ko se ne more programer Java spopasti, ko uporablja Hadoop MapReduce. Raziskovalci in razvijalci so napovedovali, da je jutri obdobje velikih podatkov. Zbirali so se že različni formati podatkov, kot so strukturirani, polstrukturirani in nestrukturirani. Tudi Facebook se je spopadal z večjo količino obdelave podatkov. Raziskovalci na Facebooku so predstavili Apache Hive za obdelavo podatkov na grozdu Hadoop. Facebook je bil prvo podjetje, ki je pripravilo Apache Hive.
Zgodba Apache HBase se začne leta 2006, ko je zagon Powerset s sedežem v San Franciscu poskušal zgraditi iskalnik naravnega jezika za splet. HBase je implementacija Googlovega Bigtableja. Se kdaj zavedamo, zakaj je bilo treba zasnovati še eno arhitekturo pomnilnika? Relacijski sistem za upravljanje podatkovnih baz obstaja že od zgodnjih sedemdesetih let prejšnjega stoletja. Obstaja veliko primerov uporabe, pri katerih so relacijske baze podatkov popolnoma smiselne, vendar za nekatere specifične težave relacijski model ne ustreza zelo dobro.
Naj pojasnim podrobneje o Apache Pive in Apache HBase.
Razlike med Apache Pive in Apache HBase
Apache Hive je odprtokodni projekt Apache, zgrajen na vrhu Hadoopa, za poizvedovanje, povzemanje in analizo velikih nizov podatkov z uporabo vmesnika, podobnega SQL-u. Apache Hive ponuja jezik, podoben SQL, imenovan HiveQL, ki pregledno pretvori poizvedbe v MapReduce za izvajanje na velikih naborih podatkov, shranjenih v distribucijskem datotečnem sistemu Hadoop (HDFS). Apache Hive je sestavni del skupine Hadoop, ki ga običajno uporabijo analitiki podatkov. Apache panj se uporablja za serijsko obdelavo velikih opravkov ETL. Apache Hive podpira tudi paketne SQL poizvedbe na zelo velikih naborih podatkov. Apache Hive povečuje fleksibilnost načrtovanja sheme ter tudi serijo in deserializacijo podatkov. Apache Hive ne podpira spletne obdelave transakcij (OLTP), ker panj ne podpira poizvedb v realnem času in posodobitev na ravni vrstic.
Apache HBase je odprtokodna baza podatkov NoSQL, ki omogoča dostop do velikih nizov podatkov v realnem času, branje in pisanje. NoSQL je nerelacijska baza podatkov. Apache HBase je razporejena zbirka podatkov, usmerjena v stolpce, ki deluje na vrhu Hadoop Distributed File System (HDFS). Tako HBase prinaša prednosti NoSQL za Hadoop. Apache HBase zagotavlja zmožnosti naključnega dostopa do podatkov, ki so prisotni v HDFS. Izkoristi odstopanje napak, ki ga zagotavlja HDFS. Uporabnik lahko podatke shrani v HDFS neposredno ali prek HBase.
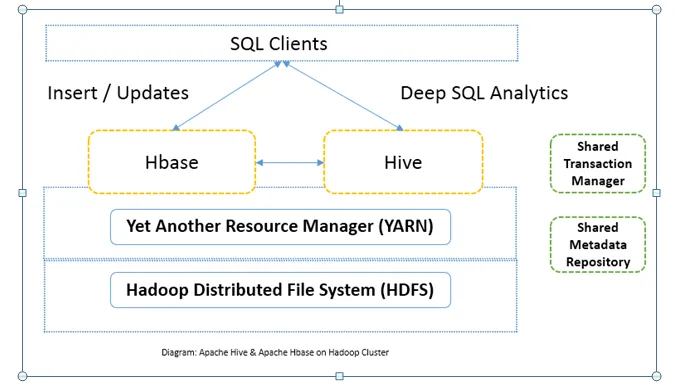
Primerjava med glavo med Apache Hive in Apache HBase (Infographics)
Spodaj je zgornjih 12 razlik med Apache Hive in Apache HBase

Ključne razlike - Apache Hive proti Apache HBase
Spodaj so seznami točk, opišite ključne razlike med Apache Hive in Apache HBase:
- Apache HBase je baza podatkov, medtem ko je Apache Hive motor za baze podatkov.
- Apache Hive se v glavnem uporablja za serijsko obdelavo (OLAP), medtem ko se Apache HBase uporablja predvsem za transakcijsko obdelavo (OLTP).
- Apache Hive izvrši večino poizvedb SQL, medtem ko Apache HBase ne omogoča neposredno poizvedb SQL.
- Apache Hive ne podpira rekordnih operacij, kot so posodabljanje, vstavljanje in brisanje, medtem ko Apache HBase podpira operacije rekordne ravni, kot so posodabljanje, vstavljanje in brisanje.
- Apache Hive deluje na MapReduce, medtem ko Apache HBase teče nad Hadoop Distributed File System (HDFS).
Apache Hive poišče datoteke tako, da določi navidezno tabelo in na njej zažene poizvedbe HQL. To je postopek, pri katerem so datoteke tako rekoč povezane v tabelo, kot je struktura in uporabnik lahko izvede jezik poizvedb Hive (HQL) in te poizvedbe pretvorijo v MapReduce Job by Hive. Uporabniku ni treba pisati opravila MapReduce, poizvedbe HQL se notranje pretvorijo v jar datoteke in te jar datoteke se bodo izvajale na naborih podatkov.
Medtem ko je v Apache HBase, so tabele razdeljene na regije in jih strežejo regijski strežniki. Druge regije so navpično razdeljene po družinah stolpcev v trgovine in Trgovine so shranjene kot datoteke v HDFS.
Kdaj uporabljati Apache Hive:
- Zahteve po skladiščenju podatkov
- Analitična poizvedba
- Analiza podatkov, ki poznajo SQL
Kdaj uporabljati Apache HBase:
- Hitra in interaktivna obdelava podatkov
- Poizvedbe v realnem času
- Hitro iskanje
- Obdelava na strani strežnika
- Naključni branje / pisanje dostopa do velikih podatkov
- Prilagodljivost aplikacije
Apache Hive lahko uporabite za izračun trendov in dnevnikov spletnega mesta za e-poslovanje za določeno trajanje, regijo ali časovni pas. Lahko se uporablja za obdelavo paketnih poizvedb po zgodovinskih podatkih, medtem ko Apache HBase lahko Facebook ali LinkedIn uporabljajo za sporočanje in analitiko v realnem času. Uporablja se lahko tudi za štetje všečkov.
Primerjalna tabela Apache Hive proti Apache HBase
Razpravljam o pomembnih artefaktih in ločim med Apache Pive in Apache HBase.
| Apache panj | Apache HBase | |
| Obdelava podatkov | Apache Pive se uporablja za
paketna obdelava, tj. spletna analitična obdelava (OLAP) | Apache HBase se uporablja za transakcijsko obdelavo, tj. Spletno transakcijsko obdelavo (OLTP) |
| Hitrost obdelave | Apache Hive ima večjo zamudo zaradi izvajanja opravila MapReduce v ozadju | Apache HBase deluje na poizvedbah v realnem času in veliko hitreje kot Apache Hive |
| Združljivost s Hadoop-om | Apache Pive teče na vrhu MapReduce | Apache HBase deluje na vrhu HDFS |
| Opredelitev | Apache Hive je odprtokoden in podoben SQL, ki se uporablja za analitične poizvedbe | Apache HBase je odprtokodna baza podatkov NoSQL, ki se uporablja za poizvedbo v realnem času |
| Skupni metapodatki | Podatki, ustvarjeni v Apache Hive, so samodejno vidni Apache HBase | Podatki, ustvarjeni v Apache HBase, so samodejno vidni Apache Pive |
| Shema | Apache panj podpira shemo za vstavljanje podatkov v tabele | Apache HBase je baza podatkov brez shem. |
| Posodobi funkcijo | Funkcija posodobitve je zapletena v Apache panju | Uporabnik lahko zelo enostavno posodobi podatke v Apache HBase |
| Operacije | Operacije v Apache panju ne potekajo v realnem času | Operacije v Apache HBase potekajo v realnem času |
| Vrste podatkov | Apache Hive je namenjen strukturiranim in polstrukturiranim podatkom | Apache HBase je namenjen nestrukturiranim podatkom. |
| Raven skladnosti | Apache panj podpira eventuelno doslednost | Apache HBase podpira takojšnjo konsistenco |
| Metode razdelitve | Apache Hive podpira funkcije Sharding | Apache HBase podpira tudi funkcije Sharding |
| Shranjevanje podatkov | Datum je shranjen v panj Metastore, particije in vedra v Apache panju | Podatki so shranjeni v stolpcih in vrstico tabel v Apache HBase |
Zaključek - Apache Hive proti Apache HBase
Običajno se Apache Hive proti Apache HBase uporablja skupaj v istem grozdu. Oboje lahko uporabljate skupaj za povečanje procesne moči. Ker panj izboljšuje analitične strani HDFS, medtem ko HBase izboljša transakcije v realnem času. Uporabnik lahko uporablja Hive kot orodje ETL za paketne vstavke s podatki v HBase in nato za izvajanje poizvedb, ki se lahko še naprej pridružijo podatkom, ki so prisotni v tablicah HBase, s podatki, ki so že prisotni na HDFS. Podatke je mogoče prebrati in zapisati iz Apache Hive v HBase in spet nazaj. Vmesnik med Apache Hive in Apache HBase še vedno dozoreva. Prihaja veliko več. Kljub temu lahko rečem, da Apache Hive v primerjavi z Apache HBase naredi skupino Hadoop močnejšo in močnejšo.
Povezani članki:
To je vodnik za Apache Hive proti Apache HBase, njihov pomen, primerjava med seboj, ključne razlike, tabela primerjave in sklep. Če želite izvedeti več, si oglejte tudi naslednje članke -
- Top 5 velikih podatkovnih gibanj
- 5 izzivi analitike velikih podatkov
- Kako razbiti Hadoopov razvijalski intervju?
- 5 izzivi analitike velikih podatkov