
Uvod v Poissonovo regresijo v R
Poissonova regresija je vrsta regresije, ki je podobna več linearni regresiji, le da je odziv ali odvisna spremenljivka (Y) številska spremenljivka. Odvisna spremenljivka sledi Poissonovi porazdelitvi. Napovedovalec ali neodvisne spremenljivke so lahko kontinuirane ali kategorične narave. Na nek način je podobna Logistični regresiji, ki ima tudi diskretno spremenljivko odziva. Predhodno razumevanje Poissonove distribucije in njene matematične oblike je zelo pomembno, da jo izkoristimo za napovedovanje. Pri R je regresijo Poisson mogoče izvesti na zelo učinkovit način. R ponuja obsežen nabor funkcij za njegovo izvajanje.
Izvajanje Poissonove regresije
Zdaj bomo nadaljevali z razumevanjem, kako se model uporablja. V naslednjem razdelku je opisan postopek po korakih za isto. Za to predstavitev razmišljamo o "gala" naboru podatkov iz "oddaljenega" paketa. Nanaša se na raznolikost vrst na otokih Galapagos. V zbirki podatkov je skupaj 7 spremenljivk. Poissonovo regresijo bomo uporabili za določitev razmerja med številom rastlinskih vrst (vrst) z drugimi spremenljivkami v naboru podatkov.
1. Najprej naložite paket "daleč". V primeru, da paketa ni, ga naložite s funkcijo install.packages ().
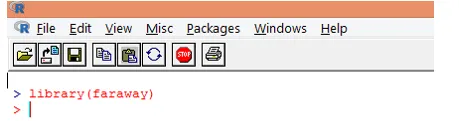
2. Ko je paket naložen, naložite podatkovni niz "gala" v R s funkcijo data (), kot je prikazano spodaj.
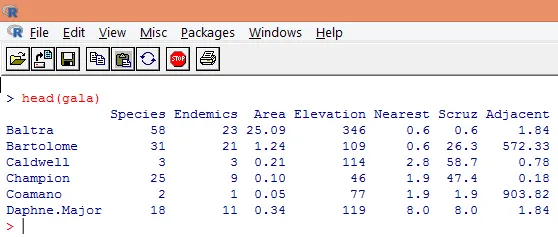
3. Naložene podatke je treba vizualizirati, da preučijo spremenljivko in preverijo, ali obstajajo odstopanja. Z uporabo funkcije head (), kot je prikazano na spodnjem posnetku zaslona, lahko vizualno predstavimo celotne podatke ali le prvih nekaj vrstic.
4. Za boljši vpogled v nabor podatkov lahko uporabimo funkcijo pomoči v R, kot je spodaj. Ustvari dokumentacijo R, kot je prikazano na posnetku zaslona po spodnjem posnetku zaslona.


5. Če preučujemo nabor podatkov, kot je omenjeno v prejšnjih korakih, lahko ugotovimo, da so vrste spremenljivka odziva. Zdaj bomo preučili osnovni povzetek spremenljivk napovedovalca.
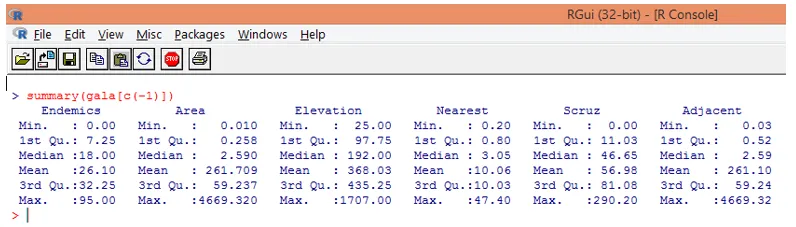
Upoštevajte, kot je razvidno zgoraj, smo izključili spremenljivko Vrste. Povzetek nam daje osnovna spoznanja. Samo opazujte srednje vrednosti za vsako od teh spremenljivk in lahko ugotovimo, da obstaja velika razlika glede na obseg vrednosti med prvo polovico in drugo polovico, npr. Za srednjo vrednost spremenljivke območja je 2, 59, vendar največja vrednost je 4669.320.
6. Zdaj, ko smo končali z osnovno analizo, bomo izdelali histogram za vrste, da preverimo, ali spremenljivka sledi Poissonovi porazdelitvi. To je prikazano spodaj.

Zgornja koda ustvari histogram za spremenljivko vrste, skupaj s krivuljo gostote, ki je nad njim nameščena.
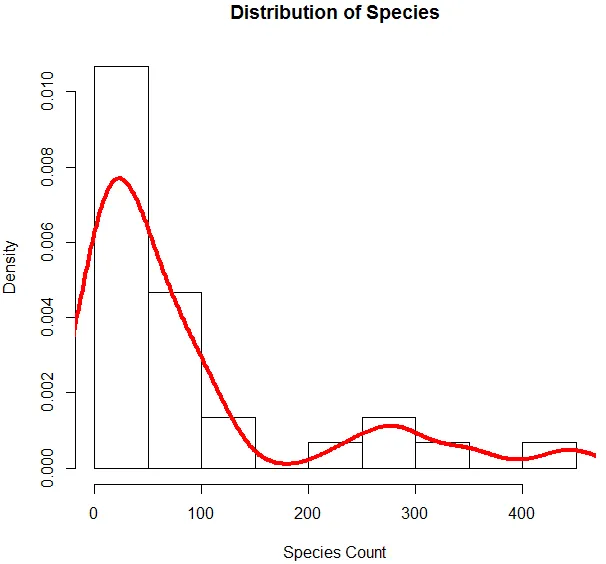
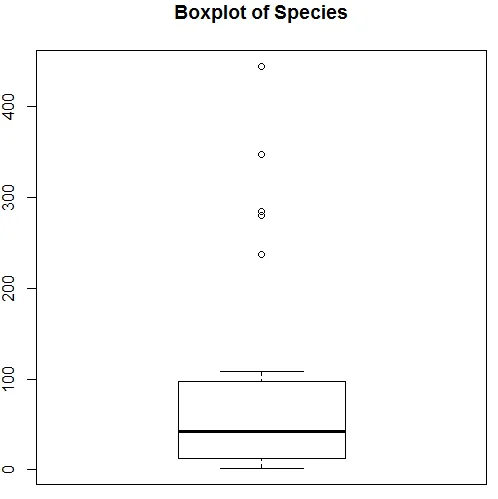
Zgornja vizualizacija kaže, da vrste sledijo Poissonovo porazdelitev, saj so podatki nagnjeni po desni. Lahko ustvarimo tudi boxplot, da dobimo boljši vpogled v distribucijski vzorec, kot je prikazano spodaj.
7. Po predhodni analizi bomo zdaj uporabili Poissonovo regresijo, kot je prikazano spodaj
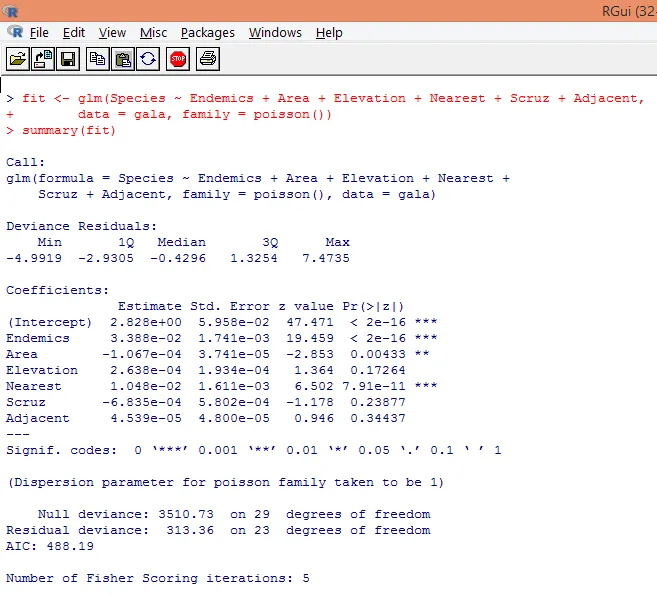
Na podlagi zgornje analize ugotovimo, da so spremenljivke Endemics, Area in Najbližje pomembne in zadostuje le njihova vključitev za oblikovanje pravega Poissonovega regresijskega modela.
8. Izdelali bomo spremenjen Poissonov regresijski model, pri čemer bomo upoštevali le tri spremenljivke. Endemije, območje in najbližje. Poglejmo, kakšne rezultate dobimo.
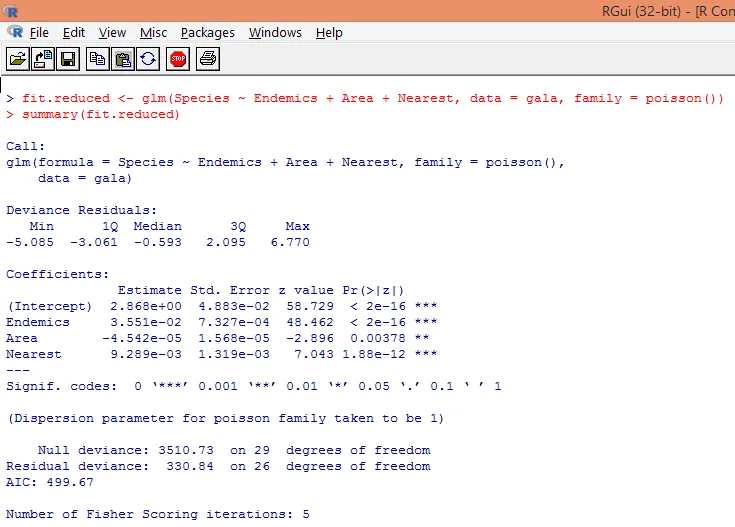
Izhod ustvari odklone, regresijske parametre in standardne napake. Vidimo, da je vsak od parametrov pomemben na ravni p <0, 05.
9. Naslednji korak je razlaga parametrov modela. Modelne koeficiente dobimo bodisi s pregledom koeficientov v zgornjem izhodu bodisi z uporabo funkcije coef ().
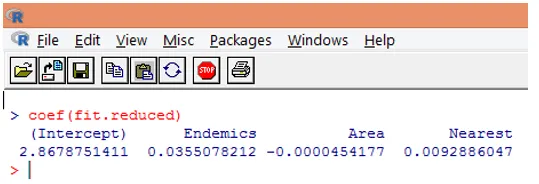
V Poissonovi regresiji je odvisna spremenljivka modelirana kot dnevnik pogojne povprečne loge (l). Regresijski parameter 0, 0355 za Endemics kaže, da je povečanje spremenljivke za eno enoto povezano z 0, 04 povečanjem povprečnega števila dnevnih vrst vrst, pri čemer so ostale spremenljivke stalne. Prestrezje je povprečno število vrst vrst, kadar je vsak napovedovalec enak nič.
10. Vendar je veliko lažje razlagati regresijske koeficiente v prvotni lestvici odvisne spremenljivke (število vrst, ne pa število dnevnikov vrst). Izpostavitev koeficientov bo omogočila enostavno razlago. To se naredi na naslednji način.
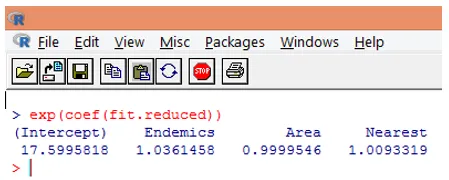
Iz zgornjih ugotovitev lahko rečemo, da se eno enotno povečanje na območju pomnoži s pričakovanim številom vrst za 0, 9999, povečanje števila endemskih vrst, ki jih predstavlja Endemics, pa z enoto pomnoži s številom vrst na 1, 0361. Najpomembnejši vidik Poissonove regresije je, da imajo eksponentni parametri multiplikativni in ne aditivni učinek na spremenljivko odziva.
11. Z zgornjimi koraki smo dobili Poissonov regresijski model za napovedovanje števila rastlinskih vrst na Galapagoških otokih. Vendar je zelo pomembno, da preverite, ali obstaja prevelika disperzija. V Poissonovi regresiji sta varianta in srednja enaka.
Prekomerna disperzija se pojavi, kadar je opažena varianca odzivne spremenljivke večja, kot bi napovedala Poissonova porazdelitev. Analiza prevelike disperzije postane pomembna, saj je pogosta s podatki o štetju in lahko negativno vpliva na končne rezultate. V R-ju lahko prekomerno disperzijo analiziramo s pomočjo paketa "qcc". Spodaj je prikazana analiza.
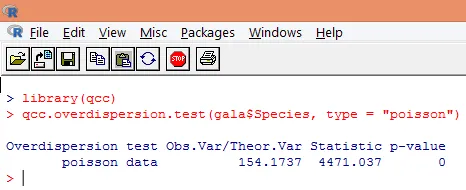
Zgornji pomembni test kaže, da je vrednost p manjša od 0, 05, kar močno nakazuje na prisotnost prevelike disperzije. Poskusili bomo vgraditi model s funkcijo glm (), tako da nadomestimo family = "Poisson" z family = "quasipoisson". To je prikazano spodaj.
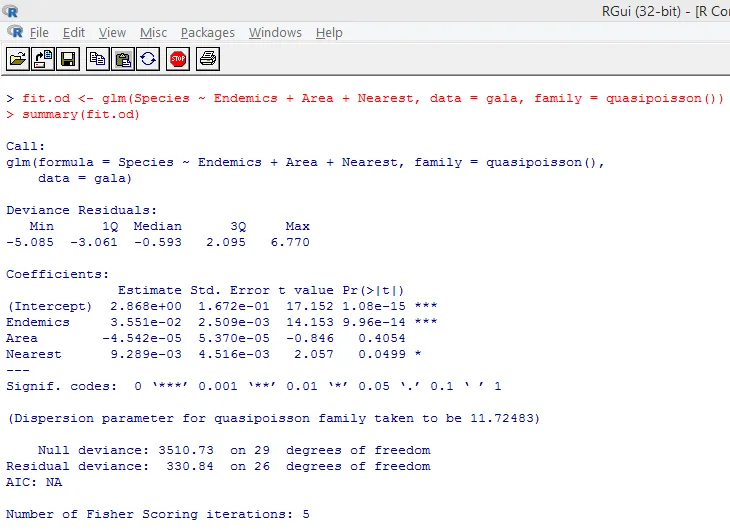
Natančno preučimo zgornji rezultat, lahko vidimo, da so ocene parametrov v kvazi-Poissonovem pristopu enake tistim, ki jih ustvarja Poisson-ov pristop, čeprav so standardne napake pri obeh pristopih različne. Poleg tega je v tem primeru za območje p-vrednost večja od 0, 05, kar je posledica večje standardne napake.
Pomen Poisson regresije
- Poissonova regresija v R je uporabna za pravilno napovedovanje spremenljive / števne spremenljivke.
- Pomaga nam prepoznati tiste pojasnjevalne spremenljivke, ki imajo statistično pomemben vpliv na spremenljivko odziva.
- Poisson regresija v R je najprimernejša za dogodke redke narave, saj ponavadi sledijo Poissonovi porazdelitvi kot običajni dogodki, ki običajno sledijo običajni porazdelitvi.
- Primeren je za uporabo v primerih, ko je spremenljivka odziva majhno celo število.
- Ima široko uporabo, saj je napovedovanje diskretnih spremenljivk v mnogih situacijah ključnega pomena. V medicini se lahko uporablja za napovedovanje vpliva zdravila na zdravje. Veliko se uporablja v analizi preživetja, kot je smrt bioloških organizmov, okvara mehanskih sistemov itd.
Zaključek
Poissonova regresija temelji na konceptu Poissonove porazdelitve. Gre za drugo kategorijo, ki spada v nabor regresijskih tehnik, ki združuje lastnosti tako linearnih kot tudi logističnih regresij. Vendar se za razliko od Logistične regresije, ki ustvarja samo binarni izhod, uporablja za napovedovanje diskretne spremenljivke.
Priporočeni članki
To je vodnik o Poissonovi regresiji v R. Tukaj govorimo o uvodu Izvedba Poissonove regresije in pomembnosti Poisson regresije. Obiščite lahko tudi druge naše predlagane članke, če želite izvedeti več -
- GLM v R
- Generator naključnih števil v R
- Regresijska formula
- Logistična regresija v R
- Linearna regresija proti logistični regresiji | Najboljše razlike