

Kaj je Big Data in Hadoop?
Podatki rastejo vsak dan eksponentno in s tako naraščajočimi podatki se pojavlja potreba po uporabi teh podatkov. Tako kot v starejših dneh smo včasih imeli diskete za shranjevanje podatkov, tudi prenos podatkov je bil počasen, danes pa je teh podatkov premalo in shranjevanje v oblaku se uporablja, ker imamo terabajte podatkov. V današnjem svetu imamo družbene medije, ki največ prispevajo k rasti podatkov. Sestavljen je iz vedenja ljudi, njihovega razmišljanja in več drugih vidikov. Govori se, da se v vsaki minuti na YouTube naloži 300 ur video posnetkov, na Facebook se naloži več kot 20 milijonov fotografij in številne druge. Poleg tega ni ustrezne strukture naloženih podatkov, kar je največji izziv za obdelavo teh podatkov.
Ker se zbira ogromno podatkov z visoko hitrostjo, tradicionalni RDBMS sistemi niso bili sposobni obvladati tako hitre rasti. Poleg tega tudi niso sposobni ravnati z nestrukturiranimi podatki. Zelo težko je bilo obdelati tako veliko količino heterogenih podatkov, ki hitro rastejo, in obdelati te podatke z veliko hitrostjo obdelave. Zato se je pojavila potreba po takem sistemu, ki je sposoben učinkovito obdelati velike naloge. Zato je za rešitev scenarija Hadoop nastal. HDFS je komponenta Hadoopa, ki se je lotila vprašanja shranjevanja velikega nabora podatkov z uporabo porazdeljenega pomnilnika, medtem ko je YARN komponenta, ki se je lotila vprašanja obdelave in drastično zmanjšala čas obdelave.
Hadoop je odprtokodni programski okvir za shranjevanje in obdelavo velikih podatkovnih nizov z uporabo porazdeljenega velikega sklopa blagovne strojne opreme. Razvili so ga Doug Cutting in Michael J. Cafarella in licenco Apache. Napisana je z uporabo Jave in je bila razvita na podlagi papirja, ki ga je Google napisal v sistemu MapReduce in uporablja koncepte funkcionalnega programiranja. Je zanesljiv, ekonomično prilagodljiv in razširljiv.
Ključne komponente Hadoopa
Glavne komponente Hadoopa so naslednje
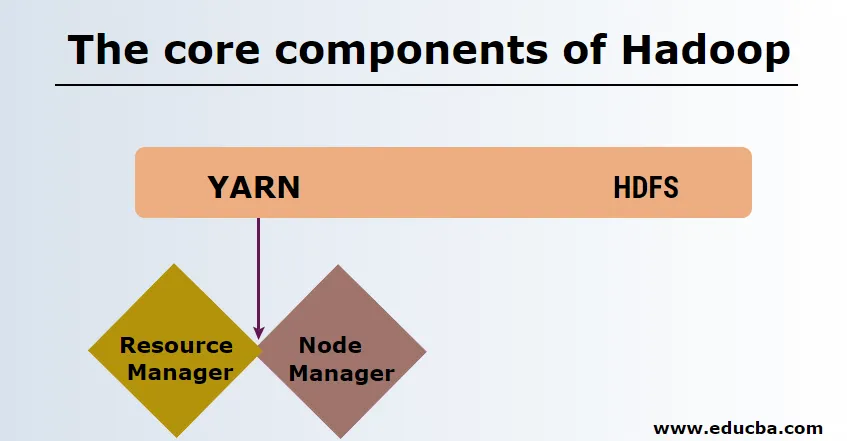
-
HDFS
HDFS ali distribucijski datotečni sistem Hadoop imata Namenode in podatkovno vozlišče. Namenode je glavno vozlišče, ki poganja glavni demon in upravlja podatkovna vozlišča ter spremlja vse operacije. Datanode so sužnji, kjer so podatki dejansko shranjeni.
-
PREJ
Preja je sestavljena iz dveh glavnih komponent:
1. ResourceManager: deluje na glavnem vozlišču in upravlja z vsemi viri ter razporedi vse aplikacije. Ima Scheduler & ApplicationManager.
2. NodeManager: deluje na vsakem pomožnem vozlišču in je odgovoren za upravljanje vsebnikov in spremljanje uporabe virov.
Več komponent Hadoopa
Obstaja več komponent Hadoopa, kot so prašič, panj, sqoop, flume, mahout, oozie, zookeeper, HBase itd.
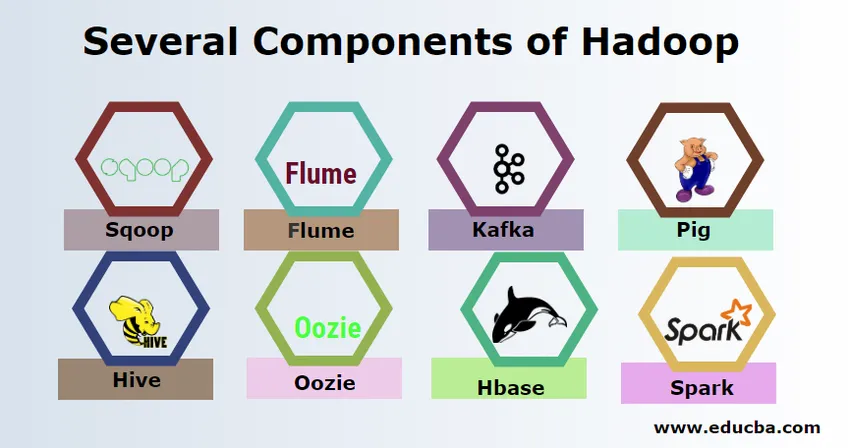
- Sqoop - Uporablja se za uvoz in izvoz podatkov iz RDBMS v Hadoop in obratno.
- Flume - Uporablja se za vlečenje podatkov v realnem času v Hadoop.
- Kafka - Gre za sistem sporočanja, ki se uporablja za usmerjanje podatkov v realnem času v Hadoop.
- Prašič - Uporablja se kot skriptni jezik za obdelavo podatkov.
- Panj - To je okvir za shranjevanje podatkov, zgrajen na HDFS, tako da lahko uporabniki, ki poznajo SQL, izvedejo poizvedbe za pridobivanje podatkov. Te poizvedbe imenujemo HiveQL.
- Oozie - Uporablja se za načrtovanje poteka dela, ki se bo izvajalo v določenih dogodkih ali času.
- Hbase - To je nobena baza podatkov SQL, ki je del Apache Hadoop.
- Spark - Uporablja se za obdelavo v pomnilniku, ki je veliko hitrejša, kot jo zmanjša Hadoop map.
Hadoop ponudniki
Obstaja veliko podjetij, ki ponujajo distribucijo Hadoop. Spodaj je nekaj najboljših ponudnikov za Hadoop:
- Cloudera
- Hortonworks
- MapR
Predpogojev za učenje Hadoopa je malo. Predhodne izkušnje Java in skriptnega jezika so potrebne. Čeprav ima Hadoop že lastne programske jezike na visoki ravni, kot sta prašič in panj, ki ustvarja zaledno kodo za nadaljnjo obdelavo, je še vedno mogoče ustvariti lasten program za zmanjšanje zemljevidov kateri koli programski jezik, kot so programiranje Ruby, Python, Perl in celo C.
Bigdata in Hadoop sta na današnjem trgu veliko povpraševanje. To se bo v prihodnjih dneh še povečalo. Veliko organizacij se je že preselilo v Hadoop in tisti, ki se ne bodo kmalu preselili. Obstaja trenutno poročilo, ki navaja, da so večje korporacije začele vlagati v analitiko velikih podatkov. Napoved trženja velikih podatkov je vedno v trendu naraščanja in to sploh ni kratkotrajno stanje. Poleg vseh teh delovnih mest v Hadoopu in veliki podatki vedno ponujajo visoko plačo v primerjavi z drugimi tehnologijami.
Top Big Data in Hadoop podjetja
Spodaj je nekaj vrhunskih podjetij, ki zaposlujejo največ Hadoop virov.
- Yahoo
- Amazonka
- Kraljevska banka Škotske
- British Airways
- Expedia
- Walmart
Ogromno je podjetij, ki uporabljajo velike podatke. To so:
-
Nokia
Za uporabo uporablja komponente Cloudera in Hadoop, kot so HDFS, HBase, Sqoop, Scribe. Uporabniške podatke je učinkovito uporabljal za razumevanje in izboljšanje uporabniške izkušnje. Uporablja obdelavo podatkov in kompleksne analize za izdelavo zemljevida s predvidljivim prometom in plastnimi modeli nadmorske višine.
-
SAS
S Hadoopom je sodeloval, da bi podatkovnim znanstvenikom pomagal do boljšega vpogleda z zagotavljanjem okolja, ki omogoča vizualno in interaktivno izkušnjo ter tako pomaga raziskovati nove trende. Analitični programi pridobivajo pomembne vpoglede v podatke, tehnologija v pomnilniku pa pomaga hitrejši dostop do podatkov.
Obstaja tudi veliko drugih podjetij, ki uporabljajo velike podatkovne platforme za različne analize. Gre za analizo podatkov o poletih črne škatle v letalski industriji, različne analize na delniškem trgu itd.
Prednosti Haddopa
Spodaj je nekaj prednosti Hadoopa
- Prilagodljiv - za razliko od tradicionalnih RDBMS je zelo razširljiva platforma, saj lahko shranjuje velike množice podatkov v porazdeljenih grozdih nad tržno strojno opremo, ki deluje vzporedno.
- Stroškovno učinkovito - stroški za RDBMS so bili previsoki za shranjevanje podatkov, ki so bili olajšani v Hadoopu.
- Hiter in prilagodljiv - Ponuja hitro dostop do podatkov prek svojega porazdeljenega datotečnega sistema. Ponuja tudi pridobivanje poslovnih spoznanj iz polstrukturiranih in nestrukturiranih podatkov.
- Odpoved na napake - kadar koli se kateri koli podatki pošljejo vozlišču, se isti podatki razmnožijo v druga vozlišča, do katerih je mogoče dostopati v primeru okvare prvega vozlišča.
Zaključek - kaj je Big Data in Hadoop
Podatki nenehno rastejo, zato bodo vedno potrebni veliki podatki, Hadoop pa bo iz teh podatkov smiseln. Zaradi tega bodo strokovnjaki s spretnostmi Hadoop v naslednjih dneh vedno našli veliko priložnosti in so lahko bistvena prednost za organizacijo, ki spodbuja poslovanje in kariero.
Priporočeni članki
To je vodilo o tem, kaj sta Big Data in Hadoop. Tu smo razpravljali o osnovnih pojmih in komponentah velikih podatkov in Hadoopa. Če želite izvedeti več, si oglejte tudi naslednji članek -
- Primeri analize velikih podatkov
- Uporaba Hadoopa
- Vodnik po vizualizaciji podatkov
- Kaj je analiza velikih podatkov?