
Uvod v modele strojnega učenja
Pregled različnih modelov strojnega učenja, ki se uporabljajo v praksi. V skladu z definicijo je model strojnega učenja matematična konfiguracija, pridobljena po uporabi specifičnih metodologij strojnega učenja. Z uporabo širokega nabora API-jev je danes gradnja modela strojnega učenja precej manjša naprej z manj vrsticami kod. Resnična spretnost strokovnjaka na področju podatkovnih podatkov pa je v tem, da izbere pravi model, ki temelji na izjavi problema in navzkrižni validaciji, namesto da podatke naključno meče na domišljijske algoritme. V tem članku bomo razpravljali o različnih modelih strojnega učenja in kako jih učinkovito uporabiti glede na vrsto težav, ki jih obravnavajo.
Vrste modelov strojnega učenja
Glede na vrsto nalog lahko razvrstimo modele strojnega učenja v naslednje vrste:
- Modeli razvrstitve
- Regresijski modeli
- Grozd
- Zmanjšanje dimenzij
- Globoko učenje itd.
1) Razvrstitev
Glede na strojno učenje je naloga klasifikacije napovedovanje vrste ali razreda predmeta v omejenem številu možnosti. Izhodna spremenljivka za razvrstitev je vedno kategorična spremenljivka. Na primer, napovedovanje e-poštnega sporočila je neželena pošta ali ni standardna naloga binarne klasifikacije. Zdaj si zapišimo nekaj pomembnih modelov za težave s klasifikacijo.
- K-najbližji sosedski algoritem - preprost, a računsko izčrpen.
- Naiven Bayes - Na osnovi Bayesovega izrekanja.
- Logistična regresija - Linearni model za binarno klasifikacijo.
- SVM - se lahko uporablja za binarne / večrazredne klasifikacije.
- Drevo odločitve - klasifikator If If Else, bolj trden za odpuščene.
- Ansambli - Kombinacija več modelov strojnega učenja, ki so združeni, da bi dosegli boljše rezultate.
2) Regresija
V stroju je regresija učenja niz težav, pri katerih lahko izhodna spremenljivka sprejme neprekinjene vrednosti. Na primer napovedovanje cene letalske karte lahko štejemo za standardno regresijsko nalogo. Zapišimo nekaj pomembnih regresijskih modelov, ki se uporabljajo v praksi.
- Linearna regresija - Najpreprostejši osnovni model za regresijsko nalogo, deluje dobro le, če so podatki linearno ločljivi in zelo malo ali ni večkolinearnosti.
- Lasso regresija - Linearna regresija z regulacijo L2.
- Ridge regression - Linearna regresija z regulacijo L1.
- Regresija SVM
- Regresija drevesa odločitve itd.
3) Grozdanje
Z enostavnimi besedami, združevanje je naloga združevanja podobnih predmetov. Modeli strojnega učenja pomagajo samodejno prepoznati podobne predmete brez ročnega posredovanja. Ne moremo zgraditi učinkovitih nadzorovanih modelov strojnega učenja (modelov, ki jih je treba izučiti z ročno kuriranimi ali označenimi podatki) brez homogenih podatkov. Grozd nam pomaga, da to dosežemo na pametnejši način. Sledi nekaj široko uporabljenih modelov grozdov:
- K pomeni - Enostavno, vendar trpi zaradi velike variacije.
- K pomeni ++ - Spremenjena različica K pomeni.
- K medoidi.
- Aglomerativno združevanje - hierarhični model grozdenja.
- DBSCAN - algoritem združevanja na podlagi gostote itd.
4) Zmanjšanje dimenzij
Dimenzionalnost je število spremenljivk napovedovalca, ki se uporabljajo za napovedovanje neodvisne spremenljivke ali target.often v naborih podatkov iz resničnega sveta, število spremenljivk je previsoko. Preveč spremenljivk prinaša tudi prekletstvo prekomernega opremljanja modelov. V praksi med temi velikimi številnimi spremenljivkami vse spremenljivke ne prispevajo enako k cilju in v večjem številu primerov lahko dejansko ohranimo odstopanja z manjšim številom spremenljivk. Naštejmo nekaj pogosto uporabljenih modelov za zmanjšanje dimenzij.
- PCA - iz velikega števila napovedovalcev ustvari manjše število novih spremenljivk. Nove spremenljivke so med seboj neodvisne, vendar manj interpretabilne.
- TSNE - Omogoča vdelavo nižjih dimenzij podatkovnih točk višjih dimenzij.
- SVD - Enojna vrednost razkroja se uporablja za razkroj matrice na manjše dele za učinkovit izračun.
5) Globoko učenje
Globoko učenje je podskupina strojnega učenja, ki se ukvarja z nevronskimi omrežji. Na podlagi arhitekture nevronskih mrež navedemo pomembne modele poglobljenega učenja:
- Večplastni perceptron
- Konvolucijska nevronska omrežja
- Ponavljajoče se nevronske mreže
- Boltzmannov stroj
- Autoencoderji itd.
Kateri model je najboljši?
Zgoraj smo vzeli ideje o številnih modelih strojnega učenja. Zdaj nam prihaja očitno vprašanje "Kateri je najboljši model med njimi?" To je odvisno od težave in drugih povezanih atributov, kot so odstranjevalci, količina razpoložljivih podatkov, kakovost podatkov, funkcija inženiring itd. V praksi je vedno bolje začeti z najpreprostejšim modelom, ki je uporaben za težavo, in povečati zapletenost postopoma s pravilno nastavitvijo parametrov in navzkrižno validacijo. V svetu podatkovnih znanosti obstaja pregovor - „navzkrižna validacija je bolj zanesljiva od domenskega znanja“.
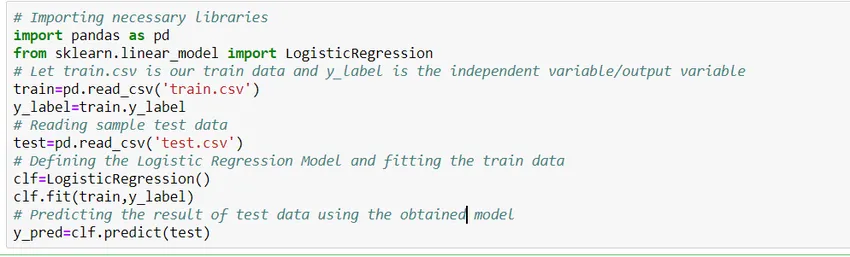
Kako sestaviti model?
Poglejmo, kako sestaviti preprost model regresije logistike z uporabo knjižnice Scikit Learn python. Zaradi poenostavitve predpostavljamo, da je težava standarden klasifikacijski model in „vlak.csv“ je vlak, „test.csv“ pa podatki o vlaku in preskusu.
Zaključek
V tem članku smo razpravljali o pomembnih modelih strojnega učenja, ki se uporabljajo v praktične namene, in kako sestaviti preprost model strojnega učenja v pythonu. Izbira ustreznega modela za določen primer uporabe je zelo pomembna za doseganje ustreznega rezultata naloge strojnega učenja. Za primerjavo uspešnosti med različnimi modeli so določene meritve vrednotenja ali KPI za posebne poslovne težave in za uporabo se izbere najboljši model po uporabi statističnega preverjanja uspešnosti.
Priporočeni članki
To je vodnik za modele strojnega učenja. Tukaj razpravljamo o top 5 vrstah modelov strojnega učenja z njegovo definicijo. Če želite izvedeti več, lahko preberete tudi druge naše predlagane članke -
- Metode strojnega učenja
- Vrste strojnega učenja
- Algoritmi strojnega učenja
- Kaj je strojno učenje?
- Strojno učenje hiperparametrov
- KPI v Power BI
- Hierarhični algoritem grozda
- Hierarhična gruča | Aglomerativno in delitveno grozdenje