
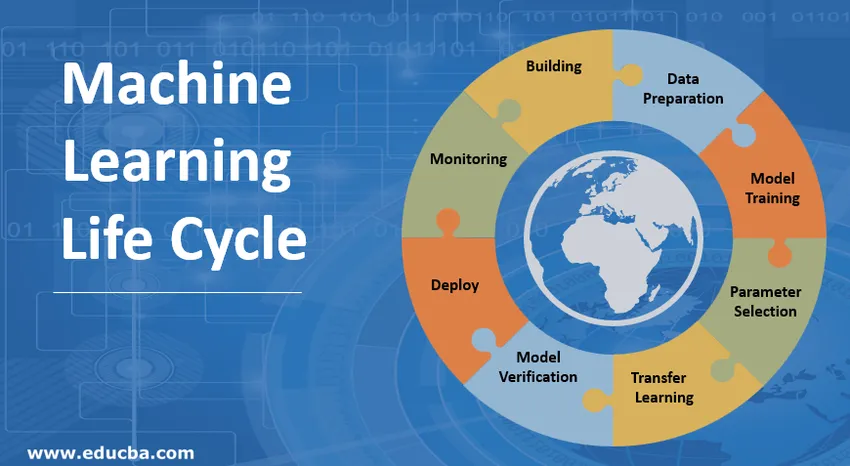
Uvod v življenjski cikel strojnega učenja (ML)
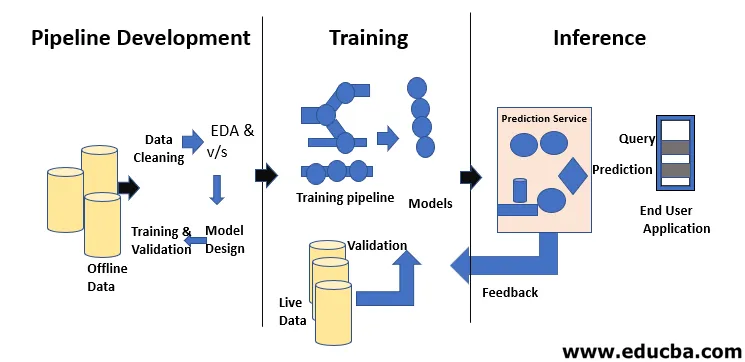
Življenjski cikel strojnega učenja je namenjen pridobivanju znanja s pomočjo podatkov. Življenjski cikel strojnega učenja opisuje trifazni proces, ki ga podatkovni znanstveniki in inženirji podatkov uporabljajo za razvoj, usposabljanje in uporabo modelov. Razvoj, usposabljanje in storitve modelov strojnega učenja so rezultat procesa, imenovanega življenjskega cikla strojnega učenja. Gre za sistem, ki podatke uporablja kot vhod in ima možnost učenja in izboljševanja z algoritmi, ne da bi bil za to programiran. Življenjski cikel strojnega učenja ima tri faze, kot je prikazano na spodnji sliki: razvoj cevovodov, usposabljanje in sklepanje.
Prvi korak v življenjskem ciklu strojnega učenja je preoblikovanje surovih podatkov v očiščen nabor podatkov, ta nabor podatkov se pogosto deli in ponovno uporabi. Če analitik ali podatkovni znanstvenik, ki naleti na težave pri prejetih podatkih, mora imeti dostop do izvirnih skriptov podatkov in preoblikovanja. Obstajajo številni razlogi, zaradi katerih se bomo morda želeli vrniti na starejše različice naših modelov in podatkov. Na primer, iskanje najnovejše najboljše različice lahko zahteva iskanje po številnih alternativnih različicah, saj modeli neizogibno poslabšajo svojo napovedno moč. Razlogov za to degradacijo je veliko, na primer premik v distribuciji podatkov, ki lahko privede do hitrega upada napovedne moči kot nadomestila za napake. Diagnosticiranje tega upada lahko zahteva primerjavo podatkov o usposabljanju s podatki v živo, prekvalifikacijo modela, ponovni pregled prejšnjih oblikovalskih odločitev ali celo preoblikovanje modela.
Učenje iz napak
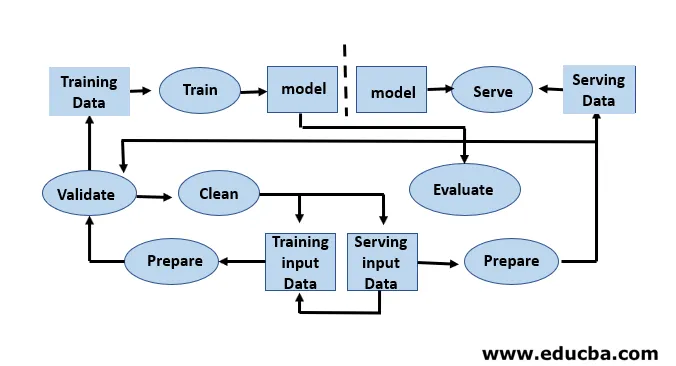
Razvoj modelov zahteva ločeno usposabljanje in testiranje podatkovnih nizov. Prekomerna uporaba preskusnih podatkov med usposabljanjem lahko privede do slabše posplošitve in uspešnosti, saj lahko vodijo do pretiranega prilagajanja. Kontekst ima pri tem ključno vlogo, zato je treba razumeti, kateri podatki so bili uporabljeni za usposabljanje predvidenih modelov in s katerimi konfiguracijami. Življenjski cikel strojnega učenja temelji na podatkih, ker sta model in rezultat usposabljanja povezana s podatki, na katerih se je usposabljalo. Pregled celovitega načrta strojnega učenja s stališča podatkov je prikazan na spodnji sliki:
Koraki, vključeni v življenjski cikel strojnega učenja
Razvijalec strojnega učenja stalno izvaja eksperimentiranje z novimi nabori podatkov, modeli, knjižnicami programske opreme, uglaševanjem parametrov, da optimizira in izboljša natančnost modela. Ker je uspešnost modela popolnoma odvisna od vhodnih podatkov in procesa usposabljanja.
1. Gradnja modela strojnega učenja
Ta korak določa vrsto modela glede na aplikacijo. Ugotavlja tudi, da je uporaba modela v fazi učenja modela, tako da jih je mogoče pravilno oblikovati glede na potrebe predvidene aplikacije. Na voljo so številni modeli strojnega učenja, kot so nadzorovani model, nenadzorovani model, klasifikacijski modeli, regresijski modeli, modeli z gručami in modeli učnega okrepitve. Na spodnji sliki je natančen vpogled:
2. Priprava podatkov
Različni podatki se lahko uporabijo kot vnos za namene strojnega učenja. Ti podatki lahko prihajajo iz številnih virov, kot so podjetja, farmacevtska podjetja, IoT naprave, podjetja, banke, bolnišnice itd. V fazi učenja stroja so na voljo velike količine podatkov, saj se s povečanjem števila podatkov prilagaja prinaša želene rezultate. Te izhodne podatke je mogoče uporabiti za analizo ali jih vstaviti v druge programe ali sisteme strojnega učenja, pri katerih bodo delovali kot osnovno gradivo.
3. Usposabljanje modela
Ta faza se nanaša na oblikovanje modela iz podatkov, ki so mu bili dani. Na tej stopnji se del podatkov o usposabljanju uporablja za iskanje parametrov modela, kot so koeficienti polinoma ali uteži strojnega učenja, kar pomaga zmanjšati napako za dani niz podatkov. Preostali podatki se nato uporabijo za testiranje modela. Ta dva koraka se na splošno ponavljajo večkrat, da bi izboljšali delovanje modela.
4. Izbira parametra
Vključuje izbiro parametrov, povezanih s treningom, ki jih imenujemo tudi hiperparametri. Ti parametri nadzorujejo učinkovitost procesa usposabljanja, zato je na koncu odvisna uspešnost modela. So zelo pomembne za uspešno izdelavo modela strojnega učenja.
5. Prenosno učenje
Ker je veliko koristi pri ponovni uporabi modelov strojnega učenja na različnih področjih. Kljub temu, da modela ni mogoče neposredno prenašati med različne domene, se zato uporablja za zagotavljanje izhodiščnega materiala za začetek usposabljanja modela naslednje faze. Tako znatno skrajša čas treninga.
6. Preverjanje modela
Vhod v to stopnjo je usposobljeni model, ki ga izdela učna faza modela, rezultat pa je preverjen model, ki uporabnikom ponuja dovolj informacij, da lahko ugotovijo, ali je model primeren za njegovo predvideno uporabo. Tako se ta stopnja življenjskega cikla strojnega učenja ukvarja z dejstvom, da model pravilno deluje, ko ga obravnavamo z vhodi, ki jih ne vidimo.
7. Namestite model strojnega učenja
V tej fazi življenjskega cikla strojnega učenja se prijavljamo za integracijo modelov strojnega učenja v procese in aplikacije. Končni cilj te faze je ustrezna funkcionalnost modela po uvedbi. Modele je treba namestiti tako, da jih je mogoče uporabiti za sklepanje in jih je treba redno posodabljati.
8. Spremljanje
Vključuje vključitev varnostnih ukrepov za zagotavljanje pravilnega delovanja modela v njegovi življenjski dobi. Da bi se to zgodilo, sta potrebna ustrezno upravljanje in posodabljanje.
Prednosti življenjskega cikla strojnega učenja
Strojno učenje zagotavlja prednosti moči, hitrosti, učinkovitosti in inteligence z učenjem, ne da bi jih izrecno programirali v aplikacijo. Ponuja priložnosti za izboljšanje zmogljivosti, produktivnosti in robustnosti.
Zaključek - Življenjski cikel strojnega učenja
Sistemi strojnega učenja postajajo iz dneva v dan pomembnejši, saj se količina podatkov, ki sodelujejo v različnih aplikacijah, hitro povečuje. Tehnologija strojnega učenja je srce pametnih naprav, gospodinjskih aparatov in spletnih storitev. Uspeh strojnega učenja je mogoče razširiti tudi na varnostno pomembne sisteme, upravljanje podatkov, visokozmogljivo računalništvo, ki ima velik potencial za aplikacije.
Priporočeni članki
To je vodnik o življenjskem ciklu strojnega učenja. Tukaj razpravljamo o uvodu, učenju napak, korakih v življenjskem ciklu strojnega učenja in prednosti. Obiščite lahko tudi druge naše predlagane članke, če želite izvedeti več -
- Podjetja za umetno inteligenco
- Analiza kompleta QlikView
- Ekosistem IoT
- Cassandra Podatkovno modeliranje