

Razlika med velikimi podatki in Apache Hadoop
Vse je na internetu. Internet ima veliko podatkov. Zato je vse Big Data. Ali veste, da se vsak dan ustvari 2, 5 Quintillion bytes podatkov in se zberejo kot Big Data? Naše dnevne dejavnosti, kot so komentiranje, všečkanje, objave itd. Na družbenih medijih, kot so Facebook, LinkedIn, Twitter in Instagram, se seštevajo kot veliki podatki. Domneva se, da bo do leta 2020 ustvarilo skoraj 1, 7 megabajta podatkov za vsako osebo na zemlji. Lahko si predstavljate in razmislite, koliko podatkov se ustvari ob predpostavki vsakega posameznika na zemlji. Danes smo povezani in delimo svoje življenje na spletu. Večina nas je povezana prek spleta. Živimo v pametnem domu in uporabljamo pametna vozila in vsa so povezana z našimi pametnimi telefoni. Si kdaj predstavljate, kako te naprave postajajo pametne? Rad bi vam dal zelo preprost odgovor, saj gre za analizo zelo velike količine podatkov, tj. Big Data. V petih letih bo na svetu več kot 50 milijard pametno povezanih naprav, razvitih za zbiranje, analiziranje in skupno rabo podatkov za boljše življenje.
Sledijo predstavitve velikih podatkov vs Apache Hadoop
Predstavljamo Termin Big Data
Kaj so veliki podatki? Kakšna velikost podatkov se šteje za velike in se imenuje kot velika podatkov? Za izraz Big Data imamo veliko relativnih predpostavk. Mogoče je, da je količina podatkov, recimo 50 terabajtov, lahko velika podatka za Start-up, vendar morda to niso veliki podatki za podjetja, kot sta Google in Facebook. Ker imajo infrastrukturo za shranjevanje in obdelavo teh količin podatkov. Rad bi opredelil izraz Big Data kot:
- Big Data je količina podatkov, ki presega zmožnosti tehnologije za učinkovito shranjevanje, upravljanje in obdelavo.
- Big Data so podatki, katerih obseg, raznolikost in zapletenost zahtevajo novo arhitekturo, tehnike, algoritme in analitiko, da bi ga upravljali in iz njega črpali vrednost in skrito znanje.
- Veliki podatki so obsežni in hitri informacijski viri z veliko hitrostjo in raznolikostjo, ki zahtevajo stroškovno učinkovite, inovativne oblike obdelave informacij, ki omogočajo boljši vpogled, odločanje in avtomatizacijo procesov.
- Big Data se nanaša na tehnologije in pobude, ki vključujejo preveč raznolike, hitro spreminjajoče se ali množične podatke, da bi jih konvencionalne tehnologije, spretnosti in infrastruktura lahko učinkovito obravnavali. Če rečem drugače, je obseg, hitrost ali raznolikost podatkov prevelika.
3 V velikih podatkov
- Obseg: Obseg se nanaša na količino / količino, s katero se ustvarjajo podatki, kot vsako uro, transakcije Wal-Mart-ovih strank podjetju zagotavljajo približno 2, 5 petabajta podatkov.
- Hitrost: Hitrost se nanaša na hitrost, s katero se podatki gibljejo, tako kot da uporabniki Facebooka v povprečju pošiljajo 31, 25 milijona sporočil in si vsak dan po internetu ogledajo 2, 77 milijona videov.
- Raznolikost: Raznolikost se nanaša na različne formate podatkov, ki so ustvarjeni kot strukturirani, polstrukturirani in nestrukturirani podatki. Tako kot pošiljanje e-poštnih sporočil s prilogo v Gmailu ni strukturiranih podatkov, medtem ko objavljanje komentarjev z nekaterimi zunanjimi povezavami tudi označimo kot nestrukturirani podatki. Skupna raba slik, zvočnih posnetkov in video posnetkov je nestrukturirana oblika podatkov.
Velika težava je shranjevanje in obdelava tega ogromnega obsega, hitrosti in raznolikosti podatkov. Moramo razmišljati o drugi tehnologiji razen RDBMS za Big Data. Razlog je, da lahko RDBMS shrani in obdeluje samo strukturirane podatke. Torej tukaj Apache Hadoop prihaja kot reševanje.
Predstavljamo termin Apache Hadoop
Apache Hadoop je odprtokodni programski okvir za shranjevanje podatkov in zagon aplikacij na grozdih strojne opreme. Apache Hadoop je programski okvir, ki omogoča porazdeljeno obdelavo velikih nizov podatkov po grozdih računalnikov z uporabo preprostih modelov programiranja. Zasnovan je tako, da poveča obseg od posameznih strežnikov do več tisoč strojev, pri čemer vsak ponuja lokalno računanje in shranjevanje. Apache Hadoop je okvir za shranjevanje in obdelavo velikih podatkov. Apache Hadoop je sposoben shranjevati in obdelati vse formate podatkov, kot so strukturirani, polstrukturirani in nestrukturirani podatki. Apache Hadoop je odprtokodna in blagovna strojna oprema v IT industrijo prinesla revolucijo. Je lahko dostopen na vseh ravneh podjetij. Za ustanovitev grozda Hadoop in za različno infrastrukturo jim ni treba več vlagati. Zato si v tej objavi podrobneje ogledamo koristno razliko med Big Data in Apache Hadoop.
Okvir Apache Hadoop
Okvir Apache Hadoop je razdeljen na dva dela:
- Hadoop porazdeljeni datotečni sistem (HDFS): Ta plast je odgovorna za shranjevanje podatkov.
- MapReduce: Ta plast je odgovorna za obdelavo podatkov na Hadoop Clusterju.
Hadoop Framework je razdeljen na glavno in suženjsko arhitekturo. Naziv sloja Hadoop Distributed File System (HDFS) Vozlišče je glavna komponenta, medtem ko je Data Node Slave komponenta, medtem ko je v sloju MapReduce Job Tracker glavna komponenta, medtem ko je sledilnik nalog podrejen. Spodaj je prikazan okvir za okvir Apache Hadoop.
Zakaj je Apache Hadoop pomemben?
- Sposobnost hitrega shranjevanja in obdelave ogromnih količin podatkov
- Računalniška moč: Hadoop-ov distribucijski model računalništva hitro obdeluje velike podatke. Več računskih vozlišč uporabljate, več moči za obdelavo imate.
- Odstopanje napak: Obdelava podatkov in aplikacij je zaščitena pred odpovedjo strojne opreme. Če vozlišče pade, se opravila samodejno preusmerijo na druga vozlišča, da se prepriča, da porazdeljeno računanje ne bo uspelo. Več kopij vseh podatkov se shrani samodejno.
- Prilagodljivost: Shranite lahko toliko podatkov, kolikor želite, in se odločite, kako jih kasneje uporabiti. To vključuje nestrukturirane podatke, kot so besedilo, slike in videoposnetki.
- Nizki stroški: Open-source ogrodje je brezplačno in uporablja blago strojne opreme za shranjevanje velikih količin podatkov.
- Prilagodljivost: Vaš sistem lahko enostavno razvijete za obdelavo več podatkov, tako da preprosto dodate vozlišča. Potrebna je majhna administracija
Primerjava med velikimi in velikimi podatki med Apache Hadoop (Infographics)
Spodaj je zgornja 4 primerjava med Big Data in Apache Hadoop
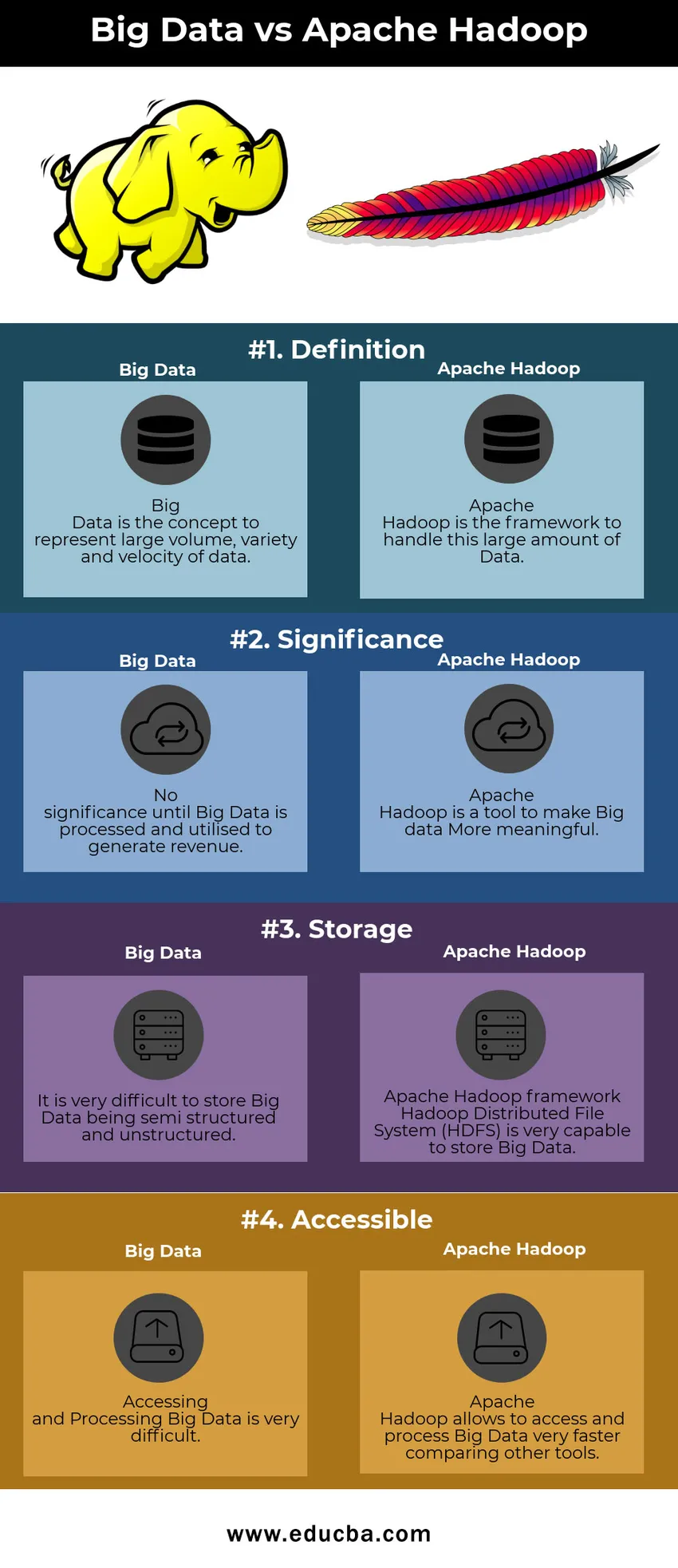
Primerjalna tabela velikih podatkov v primerjavi z Apache Hadoop
Razpravljam o glavnih artefaktih in ločim med Big Data vs Apache Hadoop
| Veliki podatki | Apache Hadoop | |
| Opredelitev | Big Data je koncept, ki predstavlja veliko količino, raznolikost in hitrost podatkov | Apache Hadoop je okvir za ravnanje s to veliko količino podatkov |
| Pomembnost | Ni pomembnega pomena, dokler se Big Data ne obdeluje in uporablja za ustvarjanje prihodka | Apache Hadoop je orodje, s katerim bodo veliki podatki pomembnejši |
| Skladiščenje | Zelo težko je shraniti, da so Big Data polstrukturirani in nestrukturirani | Okvir Apache Hadoop Hadoop porazdeljeni datotečni sistem (HDFS) je zelo sposoben za shranjevanje velikih podatkov |
| Dostopno | Dostop in obdelava velikih podatkov je zelo težaven | Apache Hadoop omogoča hiter dostop do velikih podatkov in njihovo obdelavo v primerjavi z drugimi orodji |
Zaključek - Big Data proti Apache Hadoop
Ne morete primerjati Big Data in Apache Hadoop. Razlog je, da so Big Data težava, medtem ko je Apache Hadoop rešitev. Ker se količina podatkov eksponentno povečuje v vseh sektorjih, je zelo težko shranjevati in obdelovati podatke iz enega samega sistema. Za obdelavo te velike količine podatkov potrebujemo porazdeljeno obdelavo in shranjevanje podatkov. Zato Apache Hadoop ponuja rešitev za shranjevanje in obdelavo zelo velike količine podatkov. Na koncu bom zaključil, da je Big Data velika količina zapletenih podatkov, medtem ko je Apache Hadoop mehanizem za shranjevanje in obdelavo velikih podatkov zelo učinkovito in gladko.
Priporočeni članek
To je vodnik za Big Data vs Apache Hadoop, njihov pomen, primerjava med seboj, ključne razlike, tabela primerjave in sklep. ta članek vsebuje vse koristne razlike med Big Data in Apache Hadoop. Če želite izvedeti več, si oglejte tudi naslednje članke -
- Big Data vs Data Science - kako se razlikujejo?
- Top 5 velikih podatkovnih trendov, ki jih bodo morala podjetja obvladati
- Hadoop proti Apache Spark - zanimive stvari, ki jih morate vedeti
- Apache Hadoop in Apache Spark | Top 10 primerjav, ki jih moraš vedeti!