

Uvod v Apache Flume
Apache Flume je okvir za zaužitje podatkov, ki podatke, ki temeljijo na dogodkih, zapiše v distribucijski datotečni sistem Hadoop. Znano je dejstvo, da Hadoop obdeluje velike podatke, se postavlja vprašanje, kako se podatki, ustvarjeni iz različnih spletnih strežnikov, prenašajo v datotečni sistem Hadoop? Odgovor je Apache Flume. Flume je zasnovan za zaužitje podatkov z veliko količino podatkov, ki temeljijo na podatkih, ki temeljijo na dogodkih.
Razmislite o scenariju, v katerem število spletnih strežnikov ustvari dnevniške datoteke in jih je treba poslati v datotečni sistem Hadoop. Flume te datoteke zbira kot dogodke in jih prenaša v Hadoop. Čeprav se Flume uporablja za prenos v Hadoop, ni strogega pravila, da mora biti cilj Hadoop. Flume lahko piše v druge okvire, kot sta Hbase ali Solr.
Flume arhitektura
Na splošno je arhitektura Apache Flume sestavljena iz naslednjih komponent:
- Vir drenja
- Flume Channel
- Umivalnik
- Zastopnik Flume
- Flume Dogodek
Na kratko si oglejmo vsako komponento Flume
1. Vir dima
Vir floma je prisoten v generatorjih podatkov, kot sta Face Book ali Twitter. Vir zbira podatke iz generatorja in jih prenaša na kanal Flume v obliki dogodkov Flume. Flume podpira različne vrste virov, kot je Avro Flume Source - povezuje se na Avro vrata in sprejema dogodke od Avrovega zunanjega odjemalca, Thrift Flume Source - poveže se na Thrift vrata in sprejema dogodke iz zunanjih tokov odjemalca Thrift, vira sporočilnega seznama in virov Kafka Flume.
2. Potočni kanal
Vmesna trgovina, ki shrani dogodke, ki jih pošlje Flume Source, dokler jih Sink ne porabi, se imenuje Flume Channel. Kanal deluje kot vmesni most med Source in Sink. Kanali z izlivom so po naravi transakcijski.
Flume nudi podporo za kanal File in Memory. Datotečni kanal je trajen po naravi, kar pomeni, da ko so podatki zapisani v kanal, se ne izgubi, čeprav se agent ponovno zažene. V spominu so dogodki kanalov shranjeni v pomnilniku, zato po naravi ni trajen, a zelo hiter.
3. Pomivalno korito
Potovalni umivalnik je prisoten v skladiščih podatkov, kot so HDFS, HBase. Pomivalno korito porabi dogodke iz Kanala in jih shrani v prodajne destinacije, kot so HDFS. Ni nobenega pravila, da bi pomivalno korito dostavilo dogodke v Store, namesto tega pa ga lahko konfiguriramo tako, da lahko pomivalno korito dostavi dogodke drugemu agentu. Flume podpira različne pomivalna korita, kot so HDFS pomivalno korito, panj za umivanje, pomivalno korito, Avro.
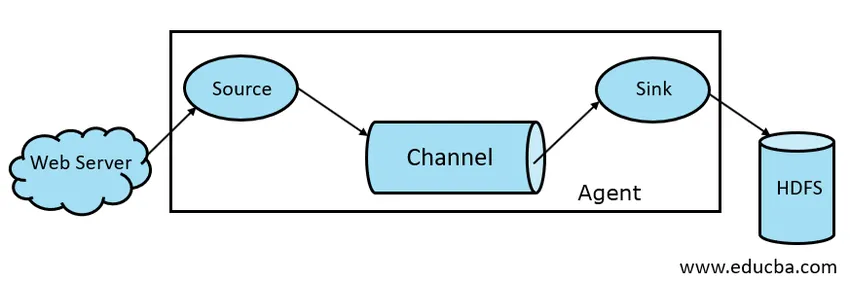
Slika 1.1 Osnovna arhitektura dima
4. Zastopnik plinov
Agent Flume je dolgotrajni postopek Java, ki se izvaja na kombinaciji Source - Channel - Sink. Flume ima lahko več kot eno sredstvo. Flume lahko obravnavamo kot zbirko povezanih agentov Flume, ki se distribuirajo v naravi.
5. Flume Event
Dogodek je enota podatkov, ki se prevažajo v Flumeu . Splošno zastopanje podatkovnega objekta v Flumeu se imenuje Event. Dogodek je sestavljen iz obremenitve nizov bajtov z izbirnimi glavami.
Delo Flume
Flume agent je java postopek, ki je sestavljen iz vira - kanala - umivalnika v najpreprostejši obliki. Vir zbira podatke iz generatorja podatkov v obliki Dogodki in jih posreduje Kanalu. Vir lahko na zahtevo dostavi v več kanalov. Fan out je postopek, pri katerem bo en vir pisal na več kanalov, tako da bodo lahko dobavili v več ponorov.
Dogodek je osnovna enota podatkov, ki se prenašajo v Flume. Kanal shrani podatke, dokler jih Sink ne zaužije. Sink zbira podatke iz Channel in jih dostavi v Centralizirano shranjevanje podatkov, kot je HDFS ali Sink lahko te dogodke posreduje drugemu agentu Flume, kot je potrebno.
Flume podpira Transakcije. Za dosego zanesljivosti Flume uporablja ločene transakcije od vira do kanala in od kanala do pomivalnega korita. Če dogodki niso dostavljeni, se transakcija vrne nazaj in pozneje ponovno prenese.
Da bi razumeli delovanje Flumea, vzemimo primer konfiguracije Flume, kjer je vir spool imenik, pomivalno korito pa Hdfs. V tem primeru je agent Flume v najpreprostejši obliki, to je topologija enojnega odtoka vira - kanal, ki je konfigurirana z uporabo datoteke z lastnostmi Java.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
V zgornjem primeru konfiguracije je agent osnova, s katero definiramo druge lastnosti. izvor1 in ponor1 in kanal1 so imena izvora, pomivalnega korita in kanala, njihove vrste in lokacije pa so prav tako omenjene.
Prednosti Apache Flume
- Flume je v naravi prilagodljiv, zanesljiv in napak. Te lastnosti so podrobno opisane v nadaljevanju
- Prilagodljiv - Flume je možno povečati vodoravno, tj. Lahko dodamo nova vozlišča glede na naše zahteve
- Zanesljivo - Apache Flume ima podporo za transakcije in zagotavlja, da se v procesu prenosa podatkov ne izgubijo nobeni podatki. Ima različne transakcije od vira do kanala in od kanala do vira.
- Flume je prilagodljiv in nudi podporo različnim virom in ponorom, kot so Kafka, Avro, imenik tuljave, Thrift itd
- V Flumeu lahko en vir prenaša podatke na več kanalov, ti kanali pa bodo podatke prenašali v več ponorov, torej lahko en vir pošlje podatke v več ponorov. Ta mehanizem se imenuje Fan ven. Flume podpira tudi Fan Fan.
- Flume zagotavlja enakomeren pretok podatkov, tj. Če se poveča hitrost branja podatkov in se poveča tudi hitrost pisanja podatkov.
- Čeprav Flume običajno zapisuje podatke v centralizirano shrambo, kot je HDFS ali Hbase, lahko Flume konfiguriramo glede na naše zahteve, tako da lahko Sink podatke zapiše drugemu agentu. To kaže na fleksibilnost Flume
- Apache Flume je odprti vir v naravi.
Zaključek
V tem članku Flume so podrobno obravnavane komponente Flume in delo Flume. Flume je prilagodljiva, zanesljiva in razširljiva platforma za prenos podatkov v centralizirano trgovino, kot je HDFS. Njegova sposobnost integracije z različnimi aplikacijami, kot so Kafka, Hdfs, Thrift, omogoča izvedljivo možnost za zaužitje podatkov.
Priporočeni članki
To je vodnik za Apache Flume. Tukaj razpravljamo o arhitekturi, delu in prednostih Apache Flume. Za več informacij si lahko ogledate tudi naslednje članke -
- Kaj je Apache Flink?
- Razlika med Apache Kafka proti Flume
- Velika podatkovna arhitektura
- Orodja Hadoop
- Spoznajte različne JavaScript dogodke