

Kaj je AWS Kinesis?
Kinesis je platforma, ki pomaga pri zbiranju, obdelavi in analiziranju pretočnih podatkov v Amazon Web Services. Pretočni podatki so velika količina podatkov, ki se sprožijo iz različnih virov, kot so socialni mediji, IoT senzorji, vremenska napoved, zdravstvena oskrba itd. Uporabljajo se pri gradnji aplikacij na podlagi potreb uporabnika. Nekatere izmed pogostih aplikacij vključujejo napovedno analitiko v velikih podatkih, strojnem učenju itd. V tej temi bomo spoznali AWS Kinesis.
AWS Kinesis Services
Preden začnemo s storitvami, najprej razumemo nekatere terminologije, ki se uporabljajo v Kinesisu.
Terminologija
| Izraz | Opredelitev |
| Zapis podatkov | Podatkovna enota, shranjena v podatkovnem toku Kinesis. Sestavljen je iz bloka podatkov, zaporedne številke in ključa particije |
| Strga | Niz zaporedja zapisov podatkov. Če povečate hitrost prenosa podatkov, lahko število rezk povečate ali zmanjšate. |
| Obdobje zadrževanja | Časovno obdobje, do katerega lahko dostopate do podatkov, potem ko so dodani v tok.
Privzeto obdobje zadrževanja: 24 ur |
| Proizvajalec | Podatke shranjuje v tok Kinesis |
| Potrošnik | Dobiva zapise iz Kinesis Stream-a in jih obdeluje. |
Kinesis ponuja 3 osnovne storitve. To so:
1. Kinezijski tokovi
Tok kineze je sestavljen iz niza zaporedja podatkovnih zapisov, znanih kot Shards. Ti Shards imajo fiksno zmogljivost, ki lahko zagotovi največjo hitrost branja 2 MB / sekundo in hitrost zapisa 1 MB / sekundo. Največja zmogljivost toka je vsota zmogljivosti vsakega drobca.
Delovanje kineze:
- Podatki, ki jih pridobijo IoT in drugi viri, znani kot Proizvajalci, se vnesejo v tok Kinesis za shranjevanje v Shards.
- Ti podatki bodo v Shardu na voljo največ 24 ur.
- Če ga je treba hraniti več kot ta privzeti čas, se lahko uporabnik poveča na obdobje hrambe 7 dni.
- Ko podatki dosežejo Shards, lahko primeri EC2 te podatke uporabijo za različne namene.
- Primeri EC2, ki pridobivajo podatke, so znani kot potrošniki.
- Po obdelavi podatkov se poda v eno od Amazonovih spletnih storitev, kot so Simple Storage Service (S3), DynamoDB, Redshift itd.
2. Kinesis Firehose
Kinesis Firehose je koristen pri prenosu podatkov v spletne storitve Amazon, kot so Redshift, Simple storage service, Elastic Search itd. To je del platforme za pretakanje, ki ne upravlja z nobenimi viri. Proizvajalci podatkov so konfigurirani tako, da je treba podatke poslati Kinesis Firehose in jih nato samodejno poslati na ustrezen cilj.
Delo Kinesis Firehose:
- Kot je omenjeno pri delovanju AWS Kinesis Streams, Kinesis Firehose dobiva tudi podatke proizvajalcev, kot so mobilni telefoni, prenosni računalniki, EC2 itd. Vendar za to ni treba odvzeti podatkov ali podaljšati obdobja hrambe, kot so Kinesis Streams. To je zato, ker Kinesis Firehose to naredi samodejno.
- Podatki se nato samodejno analizirajo in pošljejo v storitev Simple Storage Service
- Ker ni obdobja hrambe, je treba podatke analizirati ali poslati v katero koli shrambo, odvisno od uporabnikove zahteve.
- Če je treba podatke poslati v Redshift, jih je treba najprej prestaviti v storitev Simple Storage Service in od tam kopirati v Redshift.
- Toda v primeru elastičnega iskanja lahko podatke vanjo vnesemo neposredno, podobno kot storitev preprostega shranjevanja.
3. Kinesis Analytics
Kinesis Firehose dovoljuje izvajanje SQL poizvedb v podatkih, ki so prisotni v Kinesis Firehose. S pomočjo teh poizvedb SQL je mogoče podatke shraniti v Redshift, Simple Storage Service, ElasticSearch itd.
AWS Kinesis Architecture
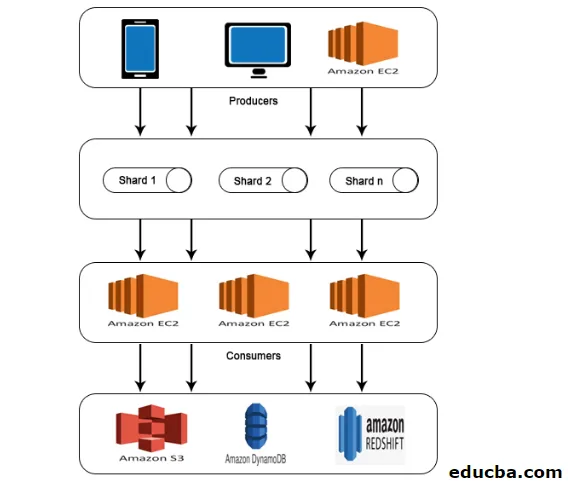
AWS Kinesis Architecture je sestavljena iz
- Proizvajalci
- Škode
- Potrošniki
- Skladiščenje
Podobno kot delo, razloženo v AWS Kinesis Data Stream, se tudi podatki proizvajalcev vnesejo v Shards, kjer se podatki obdelujejo in analizirajo. Analizirani podatki se nato premaknejo v primere EC2 za izvajanje nekaterih aplikacij. Končno bodo podatki shranjeni v kateri koli od Amazonovih spletnih storitev, kot so S3, Redshift itd.
Kako uporabljati AWS kinesis?
Če želite sodelovati z AWS Kinesis, je treba narediti naslednja dva koraka.
1. Namestite vmesnik ukazne vrstice AWS (CLI).
Namestitev vmesnika ukazne vrstice je za različne operacijske sisteme drugačna. Torej, namestite CLI na podlagi vašega operacijskega sistema.
Za uporabnike Linuxa uporabite ukaz sudo pip install AWS CLI
Prepričajte se, da imate različico python 2.6.5 ali novejšo. Po prenosu ga konfigurirajte z ukazom za konfiguriranje AWS. Nato bodo pozvane naslednje podrobnosti, kot je prikazano spodaj.
AWS Access Key ID (None): #########################
AWS Secret Access Key (None): #########################
Default region name (None): ##################
Default output format (None): ###########
Za uporabnike sistema Windows prenesite ustrezen namestitveni program MSI in ga zaženite.
2. Izvajajte Kinesis operacije z uporabo CLI
Upoštevajte, da podatkovni tokovi Kinesis niso na voljo za brezplačno stopnjo AWS. Torej, ustvarjeni tokovi Kinesis se bodo zaračunali.
Zdaj si oglejmo nekaj kinezijskih operacij v CLI.
- Ustvari tok
Ustvari tok KStream s številom skodelic 2 z naslednjim ukazom.
aws kinesis create-stream --stream-name KStream --shard-count 2
Preverite, ali je tok ustvaril.
aws kinesis describe-stream --stream-name KStream
Če je ustvarjen, se bo prikazal izhod, podoben naslednjem primeru.
(
"StreamDescription": (
"StreamStatus": "ACTIVE",
"StreamName": " KStream ",
"StreamARN": ####################,
"Shards": (
(
"ShardId": #################,
"HashKeyRange": (
"EndingHashKey": ###################,
"StartingHashKey": "0"
),
"SequenceNumberRange": (
"StartingSequenceNumber": "###################"
)
)
) )
)
- Daj zapis
Zdaj se lahko podatkovni zapis vstavi z ukazom put-record. Tu se v tok vstavi zapis, ki vsebuje preskus podatkov.
aws kinesis put-record --stream-name KStream --partition-key 456 --data test
Če je vstavljanje uspešno, bo izhod prikazan, kot je prikazano spodaj.
(
"ShardId": "#############",
"SequenceNumber": "##################"
)
- Pridobite zapis
Najprej mora uporabnik pridobiti iterator ostrine, ki predstavlja položaj toka za drobce.
aws kinesis get-shard-iterator --shard-id shardId-########## --shard-iterator-type TRIM_HORIZON --stream-name KStream
Nato zaženite ukaz s pridobljenim iteratorjem ostrine.
aws kinesis get-records --shard-iterator ###########
Izveden bo vzorec, kot je prikazano spodaj.
(
"Records":( (
"Data":"######",
"PartitionKey":"456”,
"ApproximateArrivalTimestamp": 1.441215410867E9,
"SequenceNumber":"##########"
) ),
"MillisBehindLatest":24000,
"NextShardIterator":"#######"
)
- Pospravi
Da se izognete stroškom, lahko ustvarjeni tok izbrišete s spodnjim ukazom.
aws kinesis delete-stream --stream-name KStream
Zaključek
AWS Kinesis je platforma, ki zbira, obdeluje in analizira pretočne podatke za več aplikacij, kot so strojno učenje, napovedna analitika in tako naprej. Pretočni podatki so lahko poljubnega formata, kot so zvok, video, senzorski podatki itd.
Priporočeni članki
To je vodnik za AWS Kinesis. Tukaj razpravljamo o uporabi AWS Kinesis in tudi njegove storitve z delom in arhitekturo. Če želite izvedeti več, si oglejte tudi naslednji članek -
- AWS Arhitektura
- Kaj je AWS Lambda?
- Tehnologije velikih podatkov
- Arhitektura podatkovnega rudarjenja
- Storitve skladiščenja AWS
- Vodnik za tekmovalce AWS s funkcijami