

Uvod v iskalne ukaze
Apache Spark je okvir, zgrajen na vrhu Hadoopa, za hitre izračune. Razširja koncept MapReduce v scenariju, temelječem na grozdih, da učinkovito izvaja nalogo. Spark Command je napisan v Scali.
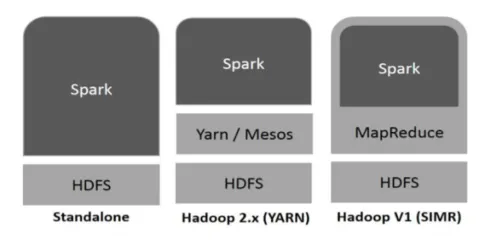
Hadoop lahko Spark uporablja na naslednje načine (glej spodaj):
Slika 1
https://www.tutorialspoint.com/
- Samostojno: Iskrica je neposredno nameščena na vrhu Hadoopa. Iskalna opravila potekajo vzporedno na Hadoopu in Spark.
- Hadoop PRE: Iskrica teče po preji brez predhodne namestitve.
- Iskrica v MapReduce (SIMR): Iskra v MapReduce se poleg samostojnega uvajanja uporablja za zagon iskalnih opravil. S SIMR lahko zaženete Spark in lahko uporabite njegovo lupino brez administrativnega dostopa.
Sestavni deli iskre:
- Apache Spark Core
- Spark SQL
- Iskrivo pretakanje
- MLib
- GraphX
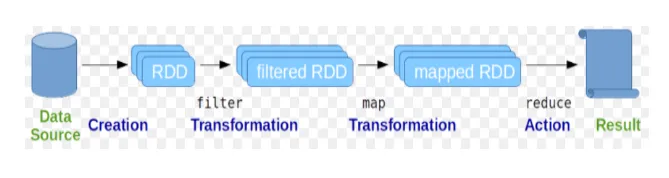
Odporni razporejeni nabori podatkov (RDD) veljajo za temeljno strukturo podatkov ukazov Spark. RDD je v naravi nespremenljiv in samo za branje. Vse vrste izračuna v iskrivih ukazih se izvajajo s preobrazbami in dejanji na RDD-jih.
Slika 2
Googlova slika
Iskriva lupina uporabnikom zagotavlja medij za interakcijo z njenimi funkcionalnostmi. Ukazi iskrice imajo veliko različnih ukazov, ki jih lahko uporabimo za obdelavo podatkov na interaktivni lupini.
Osnovni ukazi iskre
Oglejmo si nekaj osnovnih ukazov Spark, ki so podani spodaj: -
-
Če želite zagnati lupino Spark:

Slika 3
-
Preberite datoteko iz lokalnega sistema:

Tu je "sc" kontekst iskri. Glede na to, da je „data.txt“ v domačem imeniku, se bere tako, drugače je treba določiti celotno pot.
-
Ustvari RDD s paralelizacijo

NewData je zdaj RDD.
-
Preštejte predmete v RDD

-
Zberite
Ta funkcija vrne vso vsebino RDD-ja v gonilniški program. To je koristno pri odpravljanju napak pri različnih korakih pisnega programa.
-
Preberite prve tri predmete iz RDD

-
Shranite izhodne / obdelane podatke v besedilno datoteko

Tukaj je trenutna pot »output« mape.
Vmesni ukazi iskri
1. Filtrirajte na RDD
Ustvarimo nov RDD za elemente, ki vsebujejo "da".

Za obstoječi RDD je treba poklicati filter za transformacijo, da se filtrira z besedo "da", kar bo ustvarilo nov RDD z novim seznamom elementov.
2. Delovanje verige

Tu so preoblikovanje filtrov in štetje delovali skupaj. Temu pravimo verižna operacija.
3. Preberite prvo postavko RDD

4. Preštejte particije RDD
Kot vemo, je RDD sestavljen iz več particij, pojavlja se potreba po štetju št. predelnih sten. Ker pomaga pri nastavljanju in odpravljanju težav med delom z ukazi Spark.

Privzeto minimalno št. pf particija je 2.
5. pridruži se
Ta funkcija združuje dve tabeli (element tabele je dvojno), ki temelji na skupnem ključu. Pri dvojnem RDD je prvi element ključ, drugi element pa vrednost.
6. Predpomni datoteko
Predvajanje je optimizacijska tehnika. Predpomnjenje RDD pomeni, da bo RDD ostal v pomnilniku, vsa prihodnja računanja pa bodo opravljena na teh RDD v pomnilniku. Prihrani čas branja diska in izboljša zmogljivosti. Skratka, skrajša čas za dostop do podatkov.

Vendar podatki ne bodo predpomnjeni, če zaženete nad funkcijo. To lahko dokažemo z obiskom spletne strani:
http: // localhost: 4040 / shramba
Ko je dejanje končano, bo RDD predpomnilnik. Na primer:

Še ena funkcija, ki deluje podobno predpomnilniku (), je vztrajanje (). Persist uporabnikom omogoča prožnost pri argumentiranju, kar lahko pomaga pri predpomnjenju podatkov v pomnilniku, disku ali zunanjem pomnilniku. Vztrajanje brez argumentov deluje enako kot predpomnilnik ().
Napredni ukazi iskri
Oglejmo si nekaj naprednih ukazov Spark, ki so podani spodaj: -
-
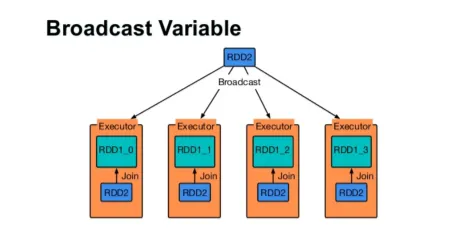
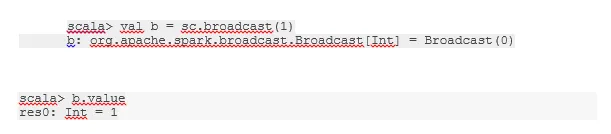
Oddaj spremenljivko
Spremenljiva spremenljivka pomaga programerju, da bere edino spremenljivko, predpomnjeno na vsaki napravi v gruči, namesto da pošlje kopijo te spremenljivke z nalogami. To pomaga zmanjšati stroške komunikacije.
Slika 4
Google Image
Skratka, obstajajo tri glavne značilnosti spremenjene izdaje:
- Brezhibno
- Prilega se v spomin
- Razdeljeno po grozdu
-
Akumulatorji
Akumulatorji so spremenljivke, ki se dodajo povezanim operacijam. Obstaja veliko uporab za akumulatorje, kot so števci, vsote itd.

Ime akumulatorja v kodi je bilo mogoče videti tudi v uporabniškem vmesniku Spark.
-
Zemljevid
Funkcija zemljevida pomaga pri ponovitvi vseh vrstic v RDD. Funkcija, uporabljena na zemljevidu, se uporablja za vsak element v RDD.
Na primer, v RDD (1, 2, 3, 4, 6), če uporabimo "rdd.map (x => x + 2)", bomo dobili rezultat kot (3, 4, 5, 6, 8).
-
Flatmap
Flatmap deluje podobno kot zemljevid, vendar map vrne samo en element, medtem ko flatmap lahko vrne seznam elementov. Zato bo za delitev stavkov na besede potreben splošen zemljevid.
-
Coalesce
Ta funkcija pomaga preprečiti premestitev podatkov. To se uporablja v obstoječi particiji, tako da se podatki premaknejo manj. Tako lahko omejimo uporabo vozlišč v grozdu.
Nasveti in nasveti za uporabo iskanih ukazov
Spodaj so različni nasveti in triki ukazov Spark: -
- Začetniki Spark lahko uporabljajo Spark-shell. Ker so ukazi Spark zgrajeni na Scali, je tako definitivno uporaba lupine iskre scala super. Vendar pa je na voljo tudi iskrenje lupine python, tako da lahko uporabimo tudi nekaj, kar dobro poznajo python.
- Iskriva lupina ima veliko možnosti za upravljanje virov grozda. Spodaj Command vam lahko pomaga pri tem:

- V Sparku je delo z dolgimi zbirkami podatkov običajna stvar. Toda pri napačnem vnosu stvari gre narobe. Vedno je dobro, da s pomočjo filtrirne funkcije Spark spustite slabe vrstice. Dober niz vnosa bo odličen korak.
- Spark za svoje podatke izbere dobro particijo. Vedno pa je dobra praksa, da pazite na predelne stene, preden začnete službo. Preizkušanje različnih particij vam bo pomagalo pri vzporednosti vašega dela.
Zaključek - Iskalni ukazi:
Spark ukaz je revolucionarni in vsestranski velik podatkovni sistem, ki lahko deluje za paketno obdelavo, sprotno obdelavo, predpomnjenje podatkov itd. Spark ima bogat nabor knjižnic strojnega učenja, ki lahko znanstvenikom in analitičnim organizacijam omogočajo močne, interaktivne in hitre aplikacije.
Priporočeni članki
To je vodnik za ukaze Spark. Tu smo razpravljali o osnovnih in naprednih ukazih Spark ter nekaj neposrednih ukazov Spark. Če želite izvedeti več, si oglejte tudi naslednji članek -
- Ukazi Adobe Photoshop
- Pomembni ukazi VBA
- Ukazi Tableau
- Natančni list SQL (ukazi, brezplačni nasveti in triki)
- Vrste združitev v Spark SQL (primeri)
- Komponente iskre | Pregled in top 6 komponent