

Uvod v Hashing v DBMS
Ko govorimo o ogromni strukturi podatkovnih baz in njihovi zapletenosti, je iskanje vseh indeksov zelo neučinkovito in doseganje želenih podatkov postane zelo nejasno in zapletena možnost. Z uporabo tehnike hashinga je mogoče doseči ta stanja in dodeliti neposreden kazalec, da se natančno in neposredno nahaja na disku za določen zapis, ne da bi pri tem uporabili zapleteno strukturo indeksa. Podatki v primeru tehnike mešanja so shranjeni v obliki podatkovnih blokov, katerih naslov je ustvarjen z uporabo funkcije, ki je ponavadi znana kot hashing funkcija. Mesto v pomnilniku, kjer se nahaja in so shranjeni zapisi, je znano kot bloki podatkov ali podatkovna zbirka.
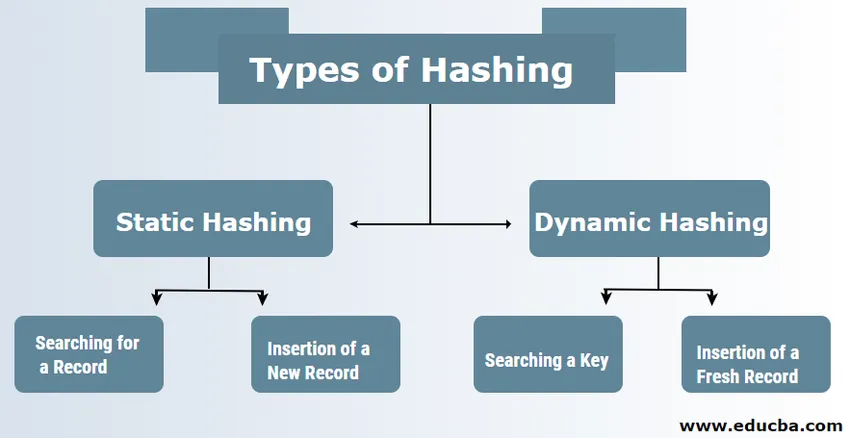
Vrste lopustov v DBMS
V DBMS običajno obstajata dve vrsti tehnik mešanja:
1. statični loputi
2. Dynamic Hashing
1) statični loputi
V primeru statičnega hashiranja je niz podatkov oblikovan in naslov vedra enak. To pomeni, da če poskušamo ustvariti naslov za USER_ID = 113 z uporabo modula 5 funkcije mešanja, potem nam vedno daje rezultat kot 3 z enakim naslovom vedra. V tem primeru ne bo nobene spremembe naslova vnesenega vedra. Zato število vedra ostane ves čas operacije konstantno.
Delovanje statično tipkanega loputa
a. Iskanje zapisa: Če je treba najti zapis, potem natančno enaka funkcija hashtiranja uporablja pri pridobivanju naslova in poti podatkovne zbirke z shranjenimi podatki.
b. Vstavitev novega zapisa: Če je nov in svež zapis v tabelo, potem se ustvari naslov novega svežega zapisa na podlagi ključa, s čimer se shrani zapis na to mesto.
- Izbris zapisa: Če želite zapis izbrisati, je treba najprej pridobiti zapis, ki ga je mogoče izbrisati. Ko je ta naloga opravljena, je treba za ta pomnilniški naslov izbrisati zapise.
- Posodobitev zapisa: Za posodobitev zapisa najprej poiščemo zapis s pomočjo funkcije, ki temelji na hashu in ko je to opravljeno, potem lahko rečemo, da je naš podatkovni zapis v posodobljenem stanju. Da lahko v datoteko vstavimo svež zapis, naslov, ki je ustvarjen s funkcijo, ki temelji na hash-u in je zbirka podatkov, prazna, ali če so podatki že na navedenem naslovu. Takšno situacijo, ki se pojavi zlasti v primeru statičnega mešanja, je mogoče bolje imenovati prelivanje vedra, zato obstajajo nekateri načini za premagovanje te težave, kot so:
(i) Odprto loputanje: Če funkcija mešanja ustvari naslov, za katerega so podatki že vidni v shranjenem stanju, se v tem primeru samodejno dodeli naslednja raven vedra. Ta mehanizem lahko imenujemo linearna tehnika sondiranja.
Na primer, če je R3 svež naslov, ki ga je treba vstaviti, bo funkcija, ki temelji na hashu, ustvarila naslov kot številko 102 za naslov R3. Generirani naslov je v polnem stanju, zato je sistem namenjen iskanju novega podatkovnega niza, ki je 113, in dodelitvi R3 temu baz podatkov.
(ii) Zaprto loputanje: Ko so vedra popolnoma polna, se nato dodeli novo vedro za določen rezultat razpršitve, ki je povezan takoj po predhodno zaključenem, zato se ta metoda imenuje tehnika prekrivanja verige.
Na primer, R3 je svež naslov, ki ga je treba vnesti v novo tabelo, funkcija heširanja se uporablja za ustvarjanje naslova kot številke 110. To vedro je napolnjeno in zato ne more sprejemati novih podatkov, zato se na koncu po 100 postavi sveže vedro.
2) Dynamic Hashing
Tovrstno metodo, ki temelji na hašišu, je mogoče uporabiti za reševanje osnovnih problemov statičnega pisanja, kot je prelivanje vedra, saj se lahko zbirke podatkov širijo in zmanjšujejo z velikostjo, ki je bolj prostorsko optimizirana tehnika, zato jo imenujemo kot razširljiva metoda na osnovi hash Pri tej metodi je razmnoževanje narejeno dinamično, kar pomeni, da sta dejavnost vstavljanja ali brisanje dovoljena, ne da bi pri tem nastala slaba zmogljivost.
a. Iskanje ključa: Izračunajte na hash naslovu potrebnega ključa in preverite število bitov, ki se uporabljajo v primeru imenika, ki je znan kot i. Potem se tisti, ki so najmanj pomembni od bitov I, vzamejo iz imenika, kar daje predstavo o indeksu iz imenika. Z uporabo te vrednosti indeksa pojdite v imenik in poiščite naslov vedra, da poiščete sedanje zapise.
b. Vstavljanje svežega zapisa: Sprva morate slediti natančno istemu postopku pridobivanja, ki ga je treba končati nekje v vedru. Poiščite prostor v tem vedru, nato pa v njega vstavite zapise. Če je ustvarjeno vedro dokončno in polno, se bo vedro razdelilo, zapisi pa se bodo prerazporedili.
Na primer, zadnja dva bita števk 2 in 4 sta 00. Torej bosta šla v vedro B0 in tako naprej glede na funkcijo modula. Ključ 9 ima naslov 10001, ki mora biti prisoten v prvem vedru, vendar se bo razcepil in se bo premaknil v novo vedro B1, kar traja, dokler se vsa vedra in ključi ne razmnožijo. Hash funkcija se uporablja na način, ko se hash funkcija uporablja za izbiro stolpca in njegove vrednosti za ustvarjanje naslova. Najdaljši čas, ko funkcija hash uporablja primarni ključ, ki se nato uporablja za ustvarjanje naslovov podatkovnega bloka. To je preprosta matematična funkcija, pri kateri se lahko primarni ključ šteje tudi za naslov podatkovnega bloka, kar pomeni, da bo vsaka vrstica z istim naslovom kot primarni ključ shranjena v podatkovnem bloku.
Priporočeni članki
To je vodnik za lovljenje v DBMS. Tukaj razpravljamo o uvajanju in različnih vrstah mešanja v DBMS, ki vključujejo statično hešing in dinamično mešanje skupaj s primeri. Za več informacij si lahko ogledate tudi naslednje članke -
- Podatkovni modeli v DBMS
- Prednosti DBMS
- Orodje za integracijo podatkov
- Kaj je RDBMS?